
Điều Gì Làm Cho Language Processing Khó Khăn?
Và làm thế nào chúng ta có thể bảo vệ các hệ thống AI của mình khỏi những thách thức đó?

Có một cách đặt vấn đề nhất định được coi là đương nhiên trong hầu hết các cuộc thảo luận về tiến trình AI. Các tác vụ nhận thức khác nhau quen thuộc với chúng ta vì con người chúng ta thấy cần phải giải quyết chúng thường xuyên. Chúng ta có thể lập một danh sách các tác vụ được xếp hạng theo tầm quan trọng trong nền kinh tế và văn hóa của chúng ta. Sau đó, chúng ta có thể bắt đầu đo lường tiến trình của AI bằng mức độ hoàn thành tốt các tác vụ mà chúng ta đã liệt kê.
Tuy nhiên, last post on codesign đã gợi ý việc suy nghĩ kỹ lưỡng về việc chuyển dịch sang trí tuệ nhân tạo là một cơ hội tốt để thiết kế lại nhiều hơn cách thức thế giới vận hành. Một số bài toán quen thuộc là khó vì những lý do mà chúng ta có quyền kiểm soát, vậy tại sao không sử dụng những đòn bẩy đó? Bây giờ tôi sẽ sử dụng ví dụ về natural language để minh họa cho cùng một mô hình. Thảo luận của chúng ta sẽ tổng quát hóa cho các phần khác trong thế giới loài người của chúng ta được tạo ra bởi sự tiến hóa (một số phần sẽ được đề cập trong các bài viết tương lai), khi tôi nhấn mạnh hai khía cạnh của lịch sử tiến hóa của chúng ta vốn đã tạo ra một cách hệ thống các phương pháp không phù hợp với các hệ thống thế hệ tiếp theo. Hai thuộc tính đó là sự tiến hóa diễn ra chậm chạp và dành nguồn lực đáng kể cho signaling.
Kết luận sẽ là natural language là một giao diện cồng kềnh không cần thiết cho các hệ thống AI sắp tới, và chúng ta nên làm tốt hơn. Cũng tình cờ là natural language là trung tâm của cuộc cách mạng hiện tại về generative AI. Hầu hết chúng ta đều sốc trước sự ra mắt của ChatGPT, một large language model mạnh mẽ đã phát triển sự hiểu việc rộng rãi rõ rệt về thế giới của chúng ta thông qua việc training trên nhiều tài liệu nhất có thể mà OpenAI có thể tìm thấy trực tuyến. Không ai (hoặc hầu như không ai?) lập kế hoạch trước cho tương lai giáo dục AI trong việc tạo ra tất cả các tài liệu này, nhưng hóa ra một cách cực kỳ hiệu quả để tìm hiểu về thế giới là tìm ra các pattern ẩn chứa trong các bài viết về các khía cạnh khác nhau của thế giới đó. Khi tôi mở ra quan điểm của mình trong blog này, tôi sẽ giải thích cách chúng ta có thể lấy cảm hứng từ thành công vang dội này nhưng làm tốt hơn (với vai trò quan trọng của codesign), có lẽ ngay cả khi không cần lượng lớn training data.
Sự tiến hóa diễn ra chậm chạp
Đây là một ví dụ từ một thể loại thú vị nhận được sự đưa tin khá tốt trên các phương tiện truyền thông chính thống. Hãy xem xét vụ kiện pháp lý năm 2017 O’Connor v. Oakhurst Dairy. Các delivery driver đã có sự bất đồng với chủ sử dụng lao động của họ về cách dùng từ của một điều luật kiểm soát thời gian làm thêm giờ. Cụm từ có vấn đề là “canning, processing, preserving, freezing, drying, marketing, storing, packing for shipment or distribution of.” Rõ ràng là cách diễn đạt này nêu ra một danh sách các hoạt động không hề nhỏ, nhưng chính xác thì danh sách này dài bao nhiêu? Nó chứa tám hay chín mục? Câu trả lời phụ thuộc vào việc chúng ta có áp dụng dấu phẩy Oxford comma hay không! Nói cách khác, chữ “or” ở cuối có nên có một dấu phẩy phía trước để chỉ ra rằng chúng ta sắp đưa ra mục cuối cùng của danh sách dài hay không? Hay chúng ta thực sự đang nêu ra một danh sách lồng nhau như một phần tử của danh sách bên ngoài?
Rõ ràng cụm từ này tuyên bố rằng việc packing for shipment nằm trong phạm vi áp dụng. Câu hỏi là liệu packing for distribution cũng nằm trong phạm vi áp dụng hay không. Có lẽ chỉ có distribution chứ không phải packing for distribution là đủ điều kiện. Chúng ta nhận được câu trả lời “hiển nhiên” khác nhau tùy thuộc vào việc chúng ta có áp dụng Oxford comma hay không. Một tòa án phúc thẩm đã phán quyết rằng các Oxford comma được giả định trong luật, do đó distribution không phải là nhiệm vụ công việc cốt lõi của các delivery driver, và họ có quyền nhận tiền làm thêm giờ cho công việc đó.
Giờ đây, từ bối cảnh, thật là điên rồ khi tưởng tượng rằng chúng ta viết ra một danh sách dài các nhiệm vụ cho các delivery driver mà lại bỏ qua distribution. Tuy nhiên, một lợi ích quan trọng của luật pháp là tính rõ ràng về các quy tắc để tránh các vấn đề từ các cách hiểu khác nhau của những người đọc có bối cảnh khác nhau. Chúng ta biết rằng natural language của chúng ta chứa đầy tính mơ hồ và chúng ta đã quen với việc điều hướng nó, nhưng các ví dụ như các delivery driver chiến thắng cho thấy chúng ta vẫn có thể gặp rắc rối từ sự mơ hồ như thế nào. Ngành luật đã phát triển các quy chuẩn để cố gắng giảm thiểu các mơ hồ, nhưng các sai sót vẫn lọt qua.
Tôi sẽ sử dụng sự mơ hồ của ngôn ngữ để minh họa cho mô hình rộng hơn về việc sự tiến hóa diễn ra quá chậm chạp khiến các đặc tính quan trọng không thích ứng kịp với những thay đổi trong cách thế giới vận hành. Bất kỳ trường hợp nào của mô hình này cũng cần chỉ rõ hai tham số chính. Đầu tiên, chúng ta cần cách mọi thứ đã từng diễn ra: con người sống trong các hunter-gatherer bands tối đa vài trăm người. Sau đó, chúng ta cần cách mọi thứ đã thay đổi: con người có thể tham gia vào một nền kinh tế và văn hóa toàn cầu hóa với hàng tỷ người.
Bây giờ là chi tiết hơn về cách mọi thứ đã từng diễn ra, trong trường hợp này là với anatomically modern humans, những người đã xuất hiện hàng trăm nghìn năm trước. Họ sống trong các nhóm xã hội nhỏ theo tiêu chuẩn ngày nay, và họ hiếm khi tương tác với những người từ các nhóm khác. Kết quả là các thành viên trong nhóm đã chia sẻ rất nhiều context: các model về thế giới và những ý tưởng nào đáng để giao tiếp. Context cho phép giải quyết sự mơ hồ. Trên thực tế, giao tiếp có thể hiệu quả hơn rất nhiều bằng cách tận dụng sự mơ hồ, khi có đủ shared bối cảnh (shared context), một mệnh đề trực quan mà một số nghiên cứu chính thức (formal study) đã xác nhận. Vì vậy, hãy cho sự tiến hóa lợi ích của sự hoài nghi và giả định một hệ thống ngôn ngữ hoạt động tốt cho con người 100.000 năm trước, tận dụng sự mơ hồ một cách tự nhiên.
Tua nhanh đến ngày nay, nơi mọi người giao tiếp qua các khoảng không gian, thời gian và văn hóa rộng lớn hơn nhiều. Có nhiều cơ hội để nói chuyện hoặc viết thư cho ai đó có context rất khác biệt, và hậu quả của sự hiểu lầm có thể rất khó chịu – đủ để tạo ra một bất lợi thực sự cho sự sống sót hoặc sinh sản. Thật không may, sự tiến hóa vẫn chưa có thời gian để bắt kịp, vì nó diễn ra chậm hơn nhiều so với tốc độ thay đổi văn hóa. Chúng ta tin rằng con người chỉ mới settled down thành các nhóm lớn hơn vài trăm người cùng với sự trỗi dậy của nông nghiệp, vào khoảng 10.000 năm trước. Tổng thời gian kể từ đó là ngắn so với tốc độ hoạt động thông thường của sự tiến hóa.
Chúng ta sẽ quay lại trong một bài viết sau về lý do tại sao sự tiến hóa tự nhiên lại chậm chạp như vậy, nhưng hiện tại, hình ảnh sau đây giúp chúng ta hiểu tại sao ngôn ngữ lại bị “mắc kẹt” ở trạng thái mơ hồ và nguy hiểm khi sử dụng giữa các context khác nhau. Về cơ bản, “sự tiến hóa” văn hóa diễn ra nhanh hơn sự tiến hóa sinh học thuần túy, và khoảng cách giữa hai bên ngày càng lớn theo thời gian. Ở đây tôi thậm chí còn cho sự tiến hóa một lợi thế không công bằng, vì các chuyên gia dường như đồng ý rằng hầu như không có gì thay đổi về mạch xử lý ngôn ngữ của chúng ta trong 100.000 năm qua (hãy xem cuốn The Language Instinct để chứng minh điều đó cho đông đảo độc giả), nhưng dù sao tôi vẫn mô tả tiến trình chậm chạp.
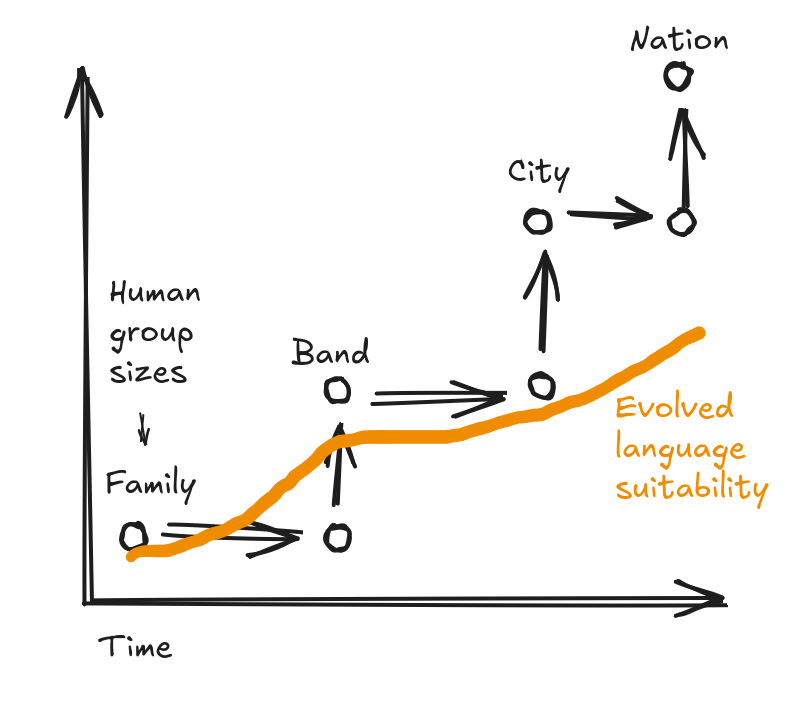
Chúng ta kỳ vọng sẽ thấy cùng một loại khoảng cách giữa một hệ thống có hầu như bất kỳ mức độ thiết kế (design) liên tục và có chủ ý nào với một hệ thống khác chỉ tiến triển thông qua chọn lọc tiến hóa.
Sự tiến hóa đã chuyển hướng các nguồn lực sang Signaling
Chúng ta vừa thảo luận về việc khi chúng ta cho sự tiến hóa lợi ích của sự hoài nghi trong việc hướng tới các mục tiêu “đúng đắn”, nó vẫn có thể kém hiệu quả trong việc đạt được chúng. Nhưng liệu có thể xảy ra trường hợp sự tiến hóa đang ngầm hướng tới một mục tiêu nào đó trái ngược với những gì chúng ta nói rằng chúng ta muốn hay không? Ngôn ngữ cung cấp một ví dụ điển hình về mô hình như vậy, trong hiện tượng rộng lớn hơn về signaling. Lần đầu tiên tôi biết đến góc nhìn này thông qua evolutionary psychology từ các cuốn sách khoa học phổ thông như The Moral Animal and The Blank Slate (nhìn chung là một số đề xuất sách phi hư cấu yêu thích của tôi).
Ví dụ kinh điển về signaling là đuôi của con chim công peacock. Những con chim trống này phát triển những chiếc đuôi cầu kỳ thực sự gây cản trở cho công việc sinh tồn hàng ngày của chúng. Ý tưởng đằng sau signaling (tiến hóa) là gây ra sự cản trở chính là mục đích: con công trống có chiếc đuôi lộng lẫy nhất sẽ gửi tín hiệu (signal) mạnh mẽ nhất đến con công mái (peahen - đối tác cái của nó) rằng nó thực sự giỏi sinh tồn. Các con công mái có lẽ không có năng lực nhận thức để trải qua lập luận đó một cách có chủ ý. Tuy nhiên, trong quá khứ tiến hóa xa xôi, hóa ra một heuristic tốt để xác định bạn tình hàng đầu là chú ý đến những chiếc đuôi có hình dạng và kích thước nhất định (khiêm tốn so với tiêu chuẩn ngày nay). Khi sở thích này tồn tại, runaway selection có thể khuếch đại mức độ cực đoan của đặc điểm này thông qua chọn lọc tình dục sexual selection, nơi những động vật có khả năng thu hút nhiều hơn các bạn tình tiềm năng sẽ sinh sản nhiều hơn, và do đó gene của chúng lan rộng trong quần thể.

Bây giờ hãy nghĩ về ngôn ngữ. Bên cạnh những mục đích hiển nhiên ngay lập tức như truyền đạt thông tin thực tế một cách hiệu quả, con người chúng ta cũng sử dụng ngôn ngữ để signal năng lực với các bạn tình tiềm năng hoặc các đối tác liên minh. Cả việc tạo ra (generating) và tiêu thụ (consuming) ngôn ngữ đều là cơ hội để thể hiện. Ví dụ, các chính trị gia chứng tỏ họ xứng đáng được bầu cử bằng cách đưa ra các bài phát biểu, nơi họ không chỉ thể hiện kiến thức về “các vấn đề” mà còn cả sự lưu loát ngôn từ chung – lựa chọn các từ và cụm từ đủ hoa mỹ để thu hút khán giả của họ mà không quá xa vời với bất kỳ ai. Hoặc có thể họ thực hiện kỳ tích thậm chí còn khó hơn là giấu các thông điệp cho những người nghe thông minh hơn trong khi vẫn hấp dẫn đông đảo cử tri. Khán giả sau đó có thể thể hiện bằng cách kín đáo cho nhau biết rằng họ đã giải mã được các thông điệp bí mật đó.
Các cuốn sách hoặc bài viết blog dày đặc cũng là một cơ hội tuyệt vời cho signaling theo cả hai hướng. Tác giả có cơ hội thể hiện khả năng viết tốt của họ, và người đọc có thể xuất hiện và đăng các bình luận để cho thấy họ đã thực hiện phân tích gốc nhằm tăng thêm giá trị và sau đó giải thích nó tốt như thế nào.

Kết quả đối với AI và Natural Language
Vì vậy, natural language đã được định hình bởi các lực lượng tiến hóa di chuyển chậm chạp và do đó đã không cập nhật nó cho các nhu cầu của thế giới hiện đại. Nếu chúng ta nghĩ các ví dụ về ngôn ngữ pháp lý khó hiểu là buồn cười, chúng ta đang hướng tới các rắc rối lớn hơn nữa khi các AI agent hoạt động thay mặt chúng ta và có thể hiểu lầm nhau theo những cách thảm khốc mà con người không có bất kỳ cơ hội nào để phát hiện. Ví dụ, hãy tưởng tượng một safety-inspector agent tương tác với một agent đại diện cho một dự án xây dựng một cây cầu (có lẽ thậm chí tự động qua đêm) vốn hóa ra an toàn cho xe tải nhưng không an toàn cho người đi bộ, vì sự bất đồng về ý nghĩa của từ “safe”. Không chỉ vậy, mà natural language còn khó một cách có mục đích (hard on-purpose) do áp lực tiến hóa từ signaling. Việc giải quyết các vấn đề khó một cách có mục đích thường là một quyết định engineering tồi!
Có rất nhiều sự kỳ vọng vào việc các agent thực hiện nhiều thứ với natural language. Ví dụ, một agent giúp người tìm việc gửi đi nhiều resume được tùy chỉnh cho các nhà tuyển dụng tiềm năng – có thể bóp méo sự thật một chút khác nhau cho mỗi phiên bản, tùy thuộc vào những gì được kỳ vọng sẽ thu hút những người đọc khác nhau. Sau đó ở phía ngược lại, các nhà tuyển dụng sử dụng các resume-filtering agent vốn cố gắng hết sức để cắt giảm nhiễu và tìm ra các ứng viên xứng đáng để phỏng vấn. Cuộc chạy đua vũ trang đang phát triển này nghe có vẻ giống như khoa học viễn tưởng phản địa đàng (dystopian) đối với tôi.
Chúng ta hãy lùi lại một bước và áp dụng góc nhìn codesign. Ngôn ngữ có vai trò trung tâm rõ rệt trong AI vì vai trò trung tâm thực sự của nó đối với chúng ta với tư cách là con người. Chúng ta có phần cứng đặc biệt dành riêng cho ngôn ngữ. Tuy nhiên, vấn đề là nhiều quan sát viên không đi đủ xa trong việc lên kế hoạch cho một tương lai đầy rẫy các AI agent. Chính sự phổ biến của các trí tuệ thay thế này gợi ý rằng các giao diện natural-language sẽ ngày càng trở nên kém tối ưu (suboptimal). Chúng ta nên có khả năng cung cấp các phong cách giao tiếp giúp tránh sự mơ hồ (avoid ambiguity) và được thiết kế cho việc xử lý đơn giản (ngược lại với việc khó một cách có mục đích). Thậm chí, chúng ta nên để các AI tự lặp đi lặp lại để phát triển các phương pháp giao tiếp vượt trội của riêng chúng.
Như một ví dụ cụ thể hơn một chút, chúng ta có thể nghĩ về các agent hỗ trợ cả hai phía của một thị trường việc làm. Điều gì sẽ xảy ra nếu các resume được trình bày dưới dạng structured format với các tuyên bố (tương đối) dễ xác minh, chẳng hạn như bằng cách liên hệ với các agent đại diện cho chủ sử dụng lao động? Với natural language, người tìm việc luôn có thể tuyên bố rằng các phát biểu sai của họ thực chất là đúng khi được đọc theo những cách hơi khác nhau. Ngay cả khi không có rủi ro về sự không chính xác, máy tính vẫn có thể sẽ rẻ hơn nhiều khi ingest và phân tích simple structured data so với việc xử lý toàn bộ sắc thái của natural language, vì vậy chúng ta có thể tiết kiệm thời gian compute và điện năng ngay cả khi bỏ qua yếu tố xác minh.
Điều quan trọng cần thừa nhận là có một điều gì đó đặc biệt về natural language ngày nay: có rất nhiều tài liệu về nó có sẵn trực tuyến. Các LLM khởi xướng cuộc cách mạng generative-AI đã được train trên kho tàng ngôn ngữ đó. Hóa ra các sắc thái của thế giới của chúng ta được bao phủ rất tốt bởi ngôn ngữ mà mọi người đã viết về thế giới đó, vì vậy từ trước đến nay chúng ta đã tạo ra các tài liệu (documentation) mà AI có thể sử dụng để tìm hiểu các chi tiết cụ thể.
Được rồi, vậy nếu chúng ta muốn duy trì những lợi thế đó nhưng tránh sự mơ hồ và khó khăn có mục đích của natural language, các lựa chọn của chúng ta là gì? Chúng ta có thể tìm hoặc tạo ra một nguồn khác gồm nhiều ví dụ hữu ích không? Hay chúng ta thậm chí có thể tìm ra một con đường dẫn đến trí thông minh mà không cần trải qua những núi training data khổng lồ (hầu như là một câu hỏi dị giáo ở Thung lũng Silicon ngày nay!)? Trong khi chúng ta đang mơ lớn, cũng đáng để xem xét liệu chúng ta có thể tăng hiệu quả tính toán (computational efficiency) và giảm sử dụng năng lượng hay không.
Cuối cùng tôi sẽ quay lại những câu hỏi đó, nhưng bài viết tiếp theo sẽ nói về một lĩnh vực tương tự mà chúng ta đã có thể thấy những lợi thế từ việc lệch khỏi training data ngôn ngữ hiện có. Thay vì natural language, tôi sẽ nói về software và các programming language, đưa chúng ta đến gần hơn với những gì tôi làm để kiếm sống.