
Thế giới xã hội của chúng ta dưới góc nhìn Distributed System
Chuẩn bị thiết kế một giải pháp thay thế được hỗ trợ bởi AI

Trong loạt bài viết tiếp theo, tôi sẽ liên tục áp dụng các phép so sánh để chuyển đổi qua lại giữa các hệ thống máy tính quen thuộc và thế giới rộng lớn hơn, bao gồm cả xã hội loài người. Tôi hy vọng mỗi bước chuyển dịch sẽ bổ sung thêm nhiều hiểu biết sâu sắc. Mục tiêu đầu tiên của tôi, trong bài viết này và bài tiếp theo, là xem xét cách chúng ta có thể hiểu nền văn minh "thực sự đang làm gì" dưới góc nhìn một hệ thống tính toán. Sau đó, một vài bài viết tiếp theo sẽ giới thiệu các công nghệ then chốt để làm việc hiệu quả hơn trong các hệ thống nhân tạo mà chúng ta chủ động thiết kế.
Các khái niệm cơ bản về Distributed Systems
Distributed systems là một kỹ thuật then chốt để mở rộng quy mô (scaling) sử dụng máy tính trong xã hội của chúng ta. Mục tiêu chính của bài viết này là xem xét lại các distributed system và bắt đầu suy nghĩ về các phép so sánh với xã hội loài người.
Hãy để tôi sử dụng một ví dụ xuyên suốt để minh họa các ưu điểm và kỹ thuật cốt lõi của distributed computing (điện toán phân tán). Gần đây, việc bắt kịp tất cả các phát triển mới và những quảng cáo thổi phồng xung quanh AI thực sự rất khó khăn. Lẽ tự nhiên, cách tiếp cận kiểu Silicon Valley là xây dựng một sản phẩm AI theo dõi các phát triển này bằng cách đọc rất nhiều trang web. Rắc rối là có thể không có một chiếc máy tính đơn lẻ nào đủ mạnh để tránh bị tụt lại phía sau! Không vấn đề gì: chúng ta có thể đưa nhiều máy chủ (servers) vào sử dụng để đạt được mục tiêu performance scaling, cải thiện throughput (tổng lượng công việc mà một hệ thống có thể thực hiện cùng một lúc).
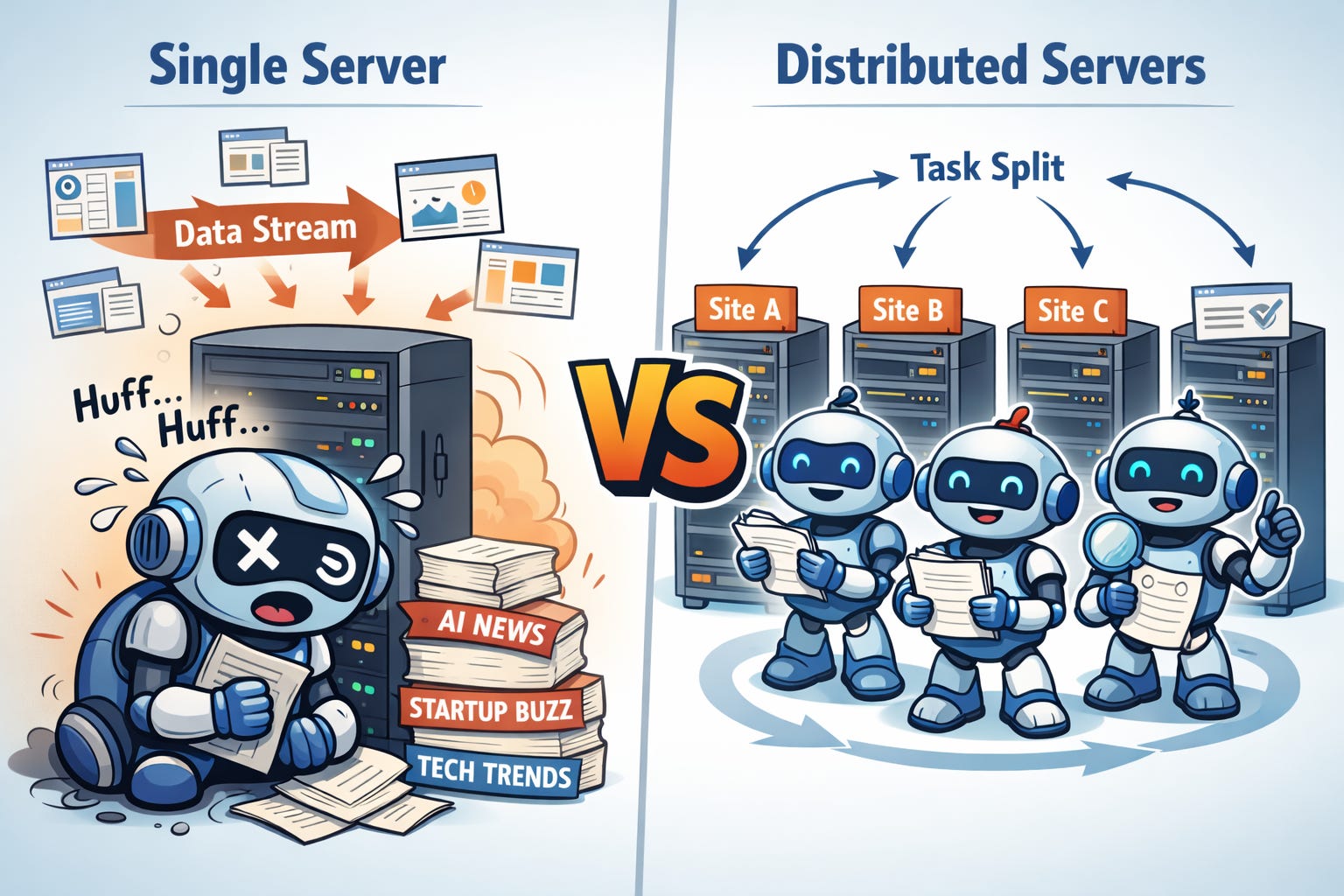
Trình theo dõi AI (AI tracker) của chúng ta đang tích lũy những thông tin chi tiết mà nhiều người đang háo hức tiếp cận. Thật không may, những người đó lại phân bố khắp toàn cầu, và việc một người truy cập dữ liệu được lưu trữ ở nửa kia thế giới sẽ mất thời gian. Tốc độ ánh sáng (có lẽ?) là giới hạn cơ bản cho truyền thông, và các sự chậm trễ khác được đưa vào bởi tính kém hiệu quả trong các hệ thống cụ thể. Do đó giá trị của georeplication (sao chép địa lý), nơi dữ liệu được trải rộng trên các hệ thống máy tính trong không gian, thậm chí cố tình nhân bản một số dữ liệu trên nhiều node. Giờ đây, người dùng có thể truy cập các replica (bản sao) gần họ nhất, giúp giảm latency (độ trễ).

Việc lưu trữ dữ liệu dư thừa cũng có những lợi ích khác. Hãy xem xét cả fault tolerance (khả năng chịu lỗi), việc thiết kế các hệ thống để chịu đựng các lỗi của một số bộ phận của chúng. Nếu một trong các server ngừng hoạt động, các server khác có thể gánh vác phần việc đó. Miễn là mọi dữ liệu quan trọng đều được sao chép trên ít nhất hai server, chúng ta có thể chịu đựng được lỗi của một node đơn lẻ. Với lượng sao chép dữ liệu nhiều hơn, chúng ta có thể chịu đựng được nhiều lỗi hơn.

Hãy cùng đánh giá các yếu tố thiết yếu của distributed system cho đến nay. So với các hệ thống máy tính tích hợp chặt chẽ hơn mà chúng ta đã thảo luận trong bài viết đầu tiên, có hai sự khác biệt nổi bật.
Các phần của hệ thống nằm đủ xa nhau trong không gian để chúng ta thực sự nhận thấy các communication delays (sự chậm trễ truyền thông).
Có đủ các bộ phận riêng biệt của hệ thống đến mức chúng ta nên lập kế hoạch cho các partial failures (lỗi cục bộ), nơi một số node bị lỗi nhưng các node khác nên tự tiếp tục công việc.
Ngay cả các hệ thống máy tính mà chúng ta không gọi là “phân tán” cũng có các lỗi ở các bộ phận phụ của chúng, với một ví dụ kinh điển là một vụ hỏng ổ cứng (hard-disk crash). Khi một ổ cứng bị lỗi trong một data center (trung tâm dữ liệu), một kỹ thuật viên có thể nhảy vào thay thế nó, nhưng chúng ta thường chấp nhận việc toàn bộ máy tính đi kèm bị ngừng hoạt động cho đến khi việc bảo trì đó hoàn tất. Ngược lại, các distributed system có xu hướng tự phát hiện và phản ứng trước các lỗi mà không cần sự can thiệp của con người.
Phân tán qua các biên giới tin cậy (Trust Boundaries)
Câu chuyện trở nên thú vị hơn khi chúng ta bắt đầu nghĩ về việc các máy tính khác nhau được vận hành bởi các bên khác nhau vốn không tin tưởng lẫn nhau. Một cách nói khác là chủ sở hữu của các máy chủ khác nhau có thể đối mặt với những incentive (động lực) không tương thích với nhau. Có thể có các động lực zero-sum (tổng bằng không) nơi một bên có lợi trên sự tổn hại của bên khác.
Đối với ví dụ xuyên suốt của chúng ta, hãy tưởng tượng rằng cần rất nhiều năng lực tính toán đến mức công việc phải được chia sẻ trên các máy chủ do các công ty khác nhau vận hành. Các công ty đó có thể xem nhau là đối thủ cạnh tranh trực tiếp và lo lắng về việc cố tình cung cấp kết quả bị lỗi để phá hoại lẫn nhau. Hoặc họ chỉ lo lắng về vấn đề kẻ ăn bám (free-rider problems) nơi các công ty lười biếng và cố lừa các bên khác làm hầu hết mọi công việc. Ví dụ, một mối quan tâm rộng rãi trong loại tình huống này là tính toàn vẹn integrity, thực thi việc dữ liệu phải đại diện cho thông tin chính xác, được tác động theo những cách thích hợp bởi các bên được ủy quyền. Ví dụ đang chạy của chúng ta bao gồm một yêu cầu rằng kết quả phân tích về những gì đang diễn ra với AI nên đại khái nhất quán với trạng thái thực tế của thế giới. Trong distributed system này, việc các công ty chấp nhận phân tích từ các đối tác của họ nhưng cũng tiến hành audit (kiểm toán) các kết quả đó theo cách nào đó là hợp lý. Họ trả thêm chi phí tính toán phụ mà (1) nên ít hơn nhiều so với chi phí tự thực hiện phân tích một mình nhưng cũng (2) mang lại kết quả trong việc phát hiện ít nhất là các nỗ lực trắng trợn từ các bên gọi là đối tác nhằm cung cấp thông tin sai lệch hoặc giả mạo.

Những biến chứng này có thể phát sinh trong các bối cảnh giống như các trò chơi nơi mọi người đều chơi theo luật lệ rõ ràng với "điều kiện chiến thắng" cố định, nhưng sự tồn tại của nhiều người chơi sẽ hướng cấu trúc incentive (động lực) chung theo các hướng khác nhau trên toàn hệ thống. Cybersecurity (an ninh mạng) đưa vào thêm những bước ngoặt: một số node trong hệ thống có thể bị xâm nhập và bị "lừa" hành xử khác đi. Chúng ta cũng có thể lo ngại rằng các chủ sở hữu thực sự của một số node quyết định dừng việc tuân thủ các luật lệ chung vì bất kỳ lý do gì, bắt đầu hành xử theo những cách gây gián đoạn một cách tùy tiện. Nhiều distributed system cũng được thiết kế để chịu đựng các lỗi thuộc loại này, và chất lượng thiết kế đó chính là Byzantine fault tolerance (khả năng chịu lỗi Byzantine).

Phần cuối cùng này của cuộc thảo luận đã bổ sung thêm hai đặc tính nền tảng quan trọng mà chúng ta thường lo lắng trong các distributed system.
Các node có thể có những chủ sở hữu khác nhau vốn đang cạnh tranh với nhau trong một số khía cạnh đồng thời hợp tác trong các khía cạnh khác.
Các node có thể bị lỗi theo những cách không chỉ giống như biến mất mà thay vào đó gây ra hành vi xấu tùy ý.
Kết nối với Xã hội loài người của chúng ta
Các quy ước hợp tác làm nền tảng cho một distributed system được gọi là một protocol (giao thức). Bây giờ tôi muốn hướng sự chú ý của chúng ta sang việc phân tích cách thế giới con người hoạt động, được xem xét như một distributed protocol. Với sự hiểu biết tốt về những gì what đang diễn ra, chúng ta có thể suy nghĩ giống như các nhà tư vấn kỹ thuật được gọi đến để phân tích một legacy system (hệ thống cũ) bám đầy bụi, đảo ngược quy trình thiết kế của nó một phần bằng cách hiểu được ý định của những nhà thiết kế ban đầu, mà nói một cách đại khái ở đây đại diện cho tiến hóa. Sau đó, chúng ta sẽ bắt đầu hình dung cách chúng ta có thể hiện thực hóa các mục tiêu phù hợp tốt hơn nữa bằng cách sử dụng các ý tưởng kỹ thuật.
Trước hết, chúng ta có thể kiểm tra tính hợp lý của ý tưởng xem xã hội loài người như một distributed system. Các node của hệ thống là những con người cá thể, một cách tự nhiên. Còn về bốn thách thức nền tảng mà chúng ta đã nói qua thì sao?
Chắc chắn có các communication delays (sự chậm trễ truyền thông) giữa những người phối hợp trong các dự án, tỷ lệ thuận với khoảng cách địa lý.
Các partial failures (lỗi cục bộ) có thể xuất hiện vì những lý do từ những đồng nghiệp bốc đồng vốn có cho đến thiên tai.
Con người thành lập các tổ chức cạnh tranh với nhau.
Con người có thể thể hiện hành vi xấu tùy ý, vì các lý do từ chơi khăm lẫn nhau cho đến mục đích ác ý.
Cho đến nay mọi thứ vẫn tốt. Bây giờ hãy xem liệu chúng ta có thể rút ra một số kết luận sơ bộ về nhận thức (cognition) mà chúng ta quen thuộc, bằng cách so sánh với các hệ thống máy tính mà chúng ta đã thảo luận trong phần lớn bài viết này. Một nguyên tắc quan trọng trong thiết kế hệ thống máy tính là layering (phân lớp), nơi các hệ thống phức tạp được chia thành các phần xếp chồng lên nhau, mỗi lớp mặc nhiên thừa nhận các lớp bên dưới và do đó có được triển khai đơn giản hơn. Hãy nghĩ về một phân rã đơn giản chỉ thành hai lớp: một lớp local (cục bộ) và một lớp distributed (phân tán). Lớp trước sử dụng các data structure và algorithm được viết mà không cần bận tâm đến ví dụ như việc một phần của máy tính bị lỗi. Sau đó, distributed protocol được viết bằng cách sử dụng các tính năng local đó để đưa ra quyết định diễn ra trên các node cá thể, nhằm hỗ trợ cho sự hợp tác rộng lớn hơn.
Tôi không muốn thử thách vận may của mình với độ dài của bài viết này, vì vậy chúng ta sẽ phải đợi hầu hết việc truy vết hậu quả của góc nhìn này. Tuy nhiên, tôi sẽ lồng ghép ở đây một chút khởi động suy đoán. Construal level theory (lý thuyết cấp độ diễn giải) là một lý thuyết tâm lý học mà tôi lần đầu tiên biết đến từ blog Overcoming Bias. Bài viết Wikipedia tôi trích dẫn viết: “ý tưởng cốt lõi của CLT là một đối tượng càng xa cá nhân, nó sẽ càng được nghĩ đến một cách trừu tượng hơn, trong khi đối tượng càng gần, nó sẽ càng được nghĩ đến một cách cụ thể hơn.” Các kết quả bao gồm việc chúng ta nghĩ về các thuật ngữ vĩ mô như tương lai của nền văn minh, và nghĩ theo các thuật ngữ cụ thể hơn về cách chúng ta nên sắp xếp cuộc sống của mình cho năng suất hàng ngày. Có vẻ hơi kỳ lạ khi bộ não của chúng ta lại hoạt động theo cách đó. Tại sao các cấp độ quy mô khác nhau lại liên kết với nhau?
Chúng ta hãy nghĩ lại cuộc thảo luận của chúng ta về ý thức, nơi tôi đã lập luận rằng một số từ có vẻ cơ bản thực chất lại ám chỉ đến các phần cứng tinh thần mà chúng ta đều chia sẻ, hoặc đúng hơn là các loại quyết định mà các khối phần cứng đó đưa ra cho chúng ta. Điều gì sẽ xảy ra nếu não bộ của chúng ta tuân theo các hệ thống máy tính trong việc được tổ chức về mặt cơ bản thành các lớp cho tính toán local và distributed, nơi phân tán là về sự phối hợp xã hội? Khi đó sẽ hợp lý tại sao các cụm khái niệm lại liên kết với hai chế độ gần và xa: các chủ đề chế độ gần (near-mode) nên được định tuyến đến phần cứng cho tính toán local, và các chủ đề chế độ xa (far-mode) nên được định tuyến đến phần cứng cho tính toán distributed (các phần local để triển khai distributed protocol). Ở một mức độ nào đó, hành vi này không có gì bí ẩn hơn việc một CPU gửi các yêu cầu phép cộng tới một mạch cộng và các yêu cầu phép nhân tới một mạch nhân. Tất nhiên, chúng ta đang nói về mạch tinh thần linh hoạt hơn nhiều, nhưng phép so sánh này vẫn có thể chứng minh là hữu ích.
Bài viết tiếp theo sẽ gợi ý một protocol quan trọng được cho là được hỗ trợ bởi phần cứng trong đầu của tất cả chúng ta. (Bạn sẽ phải chờ đợi trong sự hồi hộp vào lúc này!) Sau đó, chúng ta sẽ nghĩ về các mục tiêu cao hơn mà protocol đó phục vụ và các kỹ thuật từ tính toán nào có thể giúp chúng ta đạt được chúng hiệu quả hơn nữa, khi chúng ta thiết kế các hệ thống trí tuệ nhân tạo.