
Safe Recursive Self-Improvement với các Verified Compilers
Một bài toán thách thức vừa tầm trong AI alignment

Bài viết trước của tôi đã giới thiệu formal verification như một nhân tố hỗ trợ việc cải thiện tìm kiếm tiến hóa (evolutionary search). Mặc dù các tiến bộ về năng lực AI và safety thường được trình bày như có sự đánh đổi lẫn nhau, nhưng có hy vọng cải thiện cả hai khía cạnh thông qua việc áp dụng formal verification. Trong khi chọn lọc tự nhiên mất nhiều thời gian để “đánh giá” độ thích nghi (fitness) của các cá thể, chỉ đo lường cuộc sống cụ thể mà chúng trải qua, thì formal verification cho phép đánh giá trước trong tất cả các kịch bản khả thi, rút ngắn đáng kể chu kỳ phản hồi. Đồng thời, các loại chứng minh làm nền tảng cho formal verification có tiềm năng thiết lập các thuộc tính mà chúng ta muốn đảm bảo luôn đúng trong suốt quá trình tiến hóa (như các safety properties, theo cả nghĩa AI và, trong một phép chơi chữ thêm, nghĩa phương pháp hình thức kỹ thuật).
Có rất nhiều chi tiết cần làm đúng để thiết lập một khung làm việc sẵn sàng đảm bảo tính an toàn của các hệ thống AI mạnh mẽ. Hiện tượng kinh điển làm cho các đảm bảo an toàn trở nên khó khăn là recursive self-improvement, nơi các hệ thống AI tự thiết kế các hệ thống kế nhiệm của chúng. Một sự không đồng khớp (misalignment) “nhỏ” giữa các hệ thống AI ban đầu và những người tạo ra chúng là con người có thể bị khuếch đại, khi các AI xây dựng các năng lực ngày càng mạnh mẽ hơn, có lẽ ở tốc độ quá nhanh để con người có thể nhận thấy và phản ứng một cách hữu ích. Làm thế nào chúng ta có thể hy vọng lường trước được tất cả các “mẹo” mà một trí tuệ lớn hơn nhiều so với trí tuệ của chúng ta có thể sử dụng?
Tin tốt là cộng đồng nghiên cứu phương pháp hình thức (formal-methods) có khá nhiều kinh nghiệm cả về chiều rộng (chứng minh nhiều loại hệ thống) lẫn chiều sâu (chứng minh tích hợp của các hệ thống có nhiều bộ phận). Trong khi hầu hết các bài viết về AI safety sử dụng giọng điệu mang tính triết học hơn vì chúng ta chưa có các siêu trí tuệ để đánh giá các kỹ thuật thực tế, thì các phép loại suy với tài liệu nghiên cứu phương pháp hình thức sẽ giúp chúng ta tiếp cận vấn đề theo giọng điệu mang tính kỹ thuật hơn. Một sự thay thế tiện lợi cho các siêu trí tuệ bất hảo sẽ là các security vulnerabilities, những lỗ hổng cũng cho phép một hệ thống thực hiện các hành động hoàn toàn trái ngược với ý định của chúng ta. Thậm chí có cả những trí tuệ độc hại (“hackers”) ở đầu kia của các security vulnerabilities bị khai thác.
Thông điệp “đừng hoảng sợ” của tôi trong bài viết này và nhiều bài viết tiếp theo là cộng đồng phương pháp hình thức biết cách xây dựng các hệ thống phần cứng và phần mềm được chứng minh một cách thuyết phục là được bảo vệ khỏi các loại tấn công bảo mật phổ biến và quan trọng. Vẫn còn rất nhiều nghiên cứu và kỹ thuật cần thực hiện để mở rộng phạm vi của các đảm bảo đó. Sẽ cần nhiều công việc hơn nữa để mở rộng phạm vi bao phủ bao gồm toàn bộ AI safety. Nhưng chúng ta có thể chọn các điểm khởi đầu cụ thể với rủi ro lan rộng thành thảm họa thế việc thực ở mức tối thiểu, nơi chúng ta vẫn có cơ hội tìm hiểu về động lực kiểm soát các hệ thống tự cải tiến.
Tôi đề xuất một bài toán thách thức dựa trên một trong những chuyên ngành nghiên cứu của tôi. Một compiler là một chương trình phần mềm dịch giữa các ngôn ngữ lập trình. Ví dụ kinh điển là chuyển đổi một ngôn ngữ lập trình dễ viết cho con người thành machine language được hiểu tự nhiên bởi một CPU. Các compilers tạo thành một trong những mục tiêu ban đầu hấp dẫn nhất cho formal verification, bởi vì điều kiện chính xác là rất rõ ràng (về mặt kỹ thuật, tận dụng lợi thế của formal semantics của các ngôn ngữ lập trình). Các compilers được xác minh hình thức thực sự đang dần đi vào các hệ thống sản xuất thực tế, bao gồm cả hệ thống tôi đã đề cập trong bài viết trước, có mã nguồn được tạo ra mà có lẽ bạn đang sử dụng ngay lúc này để đọc văn bản này. Có cả các nền tảng lý thuyết trang nhã lẫn các kinh nghiệm thực tế về cách xây dựng và duy trì các verified compilers, tạo ra một sự chuẩn bị tốt cho một bài toán thách thức hấp dẫn.
Kết quả là, lĩnh vực này hoạt động hiệu quả một cách bất thường để nghiên cứu các câu hỏi được quan tâm rộng rãi trong AI safety. Trong nhiều thập kỷ qua, các compilers đã thực sự được sử dụng để tự cải thiện chính chúng, và hơn thế nữa cũng có các định nghĩa hình thức rõ ràng về điều gì làm cho một compiler trở nên safe.
Sẽ có cả tin tốt và tin xấu. Tôi sẽ bắt đầu bằng cách chứng minh tại sao bài toán thách thức này chiếm một vị trí lý tưởng để tìm hiểu về tự cải tiến đã được xác minh. Sau đó, tôi sẽ đưa ra một số lỗi bất ngờ (gotchas) kinh điển thường gặp trong xác minh compiler truyền thống, cùng với các giải pháp điển hình. Việc suy nghĩ về các lỗi bất ngờ này sẽ giúp chúng ta duy trì một mức độ cảnh giác lành mạnh về mức độ khó khăn để phát hiện ra tất cả các hành vi không mong muốn.
Lập luận cho tầm quan trọng và độ khó của vấn đề
Không phải ai đọc bài viết này cũng nhận ra tầm quan trọng của các compilers đối với sự tiến bộ gần đây của AI, chưa nói đến toàn bộ phạm vi của ngành công nghiệp công nghệ. Chúng ta biết rằng generative AI tốn kém về mặt tính toán đến mức nhiều công ty đang nhanh chóng xây dựng các trung tâm dữ liệu mới để chứa các máy móc vận hành nó. Mã nguồn cuối cùng chạy trên phần cứng được tạo ra bởi các compilers (các ví dụ nổi bật trong machine learning bao gồm XLA và Triton). Các compilers thực hiện việc tối ưu hóa mã nguồn càng tốt thì chúng ta càng cần ít phần cứng hơn, càng cần ít trung tâm dữ liệu mới hơn, và chi phí cho các công ty và khách hàng của họ càng thấp. Hơn nữa, các lỗi compiler có thể dẫn đến hành vi sai trái tùy ý của AI được triển khai, có khả năng kích hoạt các vụ vi phạm bảo mật. Tôi hy vọng bây giờ đã rõ ràng rằng tầm quan trọng kinh tế của các compilers là rất cao, do đó có động lực thực tế để sử dụng bất kỳ công cụ nào có sẵn nhằm giúp chúng hoạt động hiệu quả hơn, và các công cụ đó bao gồm cả recursive self-improvement.
Thực sự có một lịch sử lâu đời về việc suy nghĩ về các compilers tham gia vào tương lai của chính chúng. Bài phát biểu nhận giải thưởng Turing của Ken Thompson, có tiêu đề “Reflections on Trusting Trust”, đã giải quyết các mối nguy hại của các compilers lén lút. Hoàn toàn có thể xảy ra tình huống trong đó phần mềm được triển khai, mà chúng ta gọi là S, chứa một backdoor bảo mật quan trọng, nhưng source code của chương trình đó lại không chứa bằng chứng nào về backdoor đó, và source code của compiler được sử dụng cùng với nó, mà chúng ta gọi là C, cũng vậy.
Làm thế nào chúng ta rơi vào một trạng thái phản trực quan như vậy?
Sửa đổi source code của C để nó nhận biết khi nào nó đang biên dịch S, nhờ đó nó có thể âm thầm thêm vào backdoor.
Ngoài ra, sửa đổi source code C để nó nhận biết khi nào nó đang biên dịch chính nó (một phiên bản tương lai nào đó của C), để nó có thể thêm vào chính xác sửa đổi từ bước trước.
Biên dịch C bằng chính nó và cài đặt phiên bản lén lút mới này ở mọi nơi.
Hoàn tác (Undo) các thay đổi đối với mã nguồn của C từ hai bước trước đó, điều mà bạn luôn giữ cho riêng mình, để không ai có bằng chứng source-code về thủ thuật này.
Giờ đây chúng ta đang ở trạng thái ổn định nơi các backdoors luôn hiện diện trên hệ thống ban đầu nhận được compiler lắt léo, nhưng không có source code nào trên hành tinh chứa bằng chứng đó. Một nhà phân tích cần phải đào sâu vào machine code để nhận ra điều gì đó không ổn.
Có thể lập luận rằng tiền lệ từ năm 1984 này cho thấy một số động lực giống như những gì các nhà nghiên cứu về AI safety lo ngại, làm cho nó trở thành một bối cảnh tốt để giải quyết chúng bằng các công cụ có nguyên tắc. Có cơ hội chiếm lĩnh một vị trí trung gian bất thường trong phổ thảo luận về AI safety. Một mặt, chúng ta có công việc rất thực tế nhắm vào các hệ thống AI được sử dụng rộng rãi ngày nay, hầu hết trong số đó đặt phần lớn gánh nặng tính toán vào tay deep learning. Mặc dù các nghiên cứu hiện tại về các chủ đề như explainability vẫn đang tiếp diễn, tôi nghĩ vẫn chưa thể đưa ra kết luận chắc chắn liệu loại hệ thống này có tuân thủ các định nghĩa tốt về alignment trong tương lai hay không, và chúng ta cũng nên xem xét các khả năng từ việc codesigning các hệ thống thông minh để dễ đặc tả và chứng minh hơn. Cũng có nhiều suy nghĩ về alignment và safety cho các hệ thống AI có khả năng vượt trội hơn nhiều trong tương lai, nhưng vì chúng ta chưa có các hệ thống đó, thật khó để thực hiện các nghiên cứu thực nghiệm (empirical work) được thúc đẩy bởi việc xây dựng các nontrivial implementations. Tôi muốn khẳng định rằng các self-improving compilers rất hấp dẫn vì chúng đang tồn tại ngày nay trong khi lại phơi bày các thử thách bảo mật tương tự với những gì được thảo luận từ lâu cho AI alignment. Tuy nhiên, để hoàn toàn thuyết phục, chúng ta sẽ cần đảm bảo đưa vào một số tính năng kỹ thuật có thể không rõ ràng đối với một người từ cộng đồng nghiên cứu xung quanh việc xác minh compiler; tôi sẽ đề cập đến những tính năng đó ngay sau đây.
Functional Correctness của các Compilers
Bây giờ, hãy tưởng tượng một compiler biên dịch chính nó (ngoài các chương trình ứng dụng quan trọng cơ bản) lặp đi lặp lại. Những gì chúng ta hy vọng là nó thực hiện công việc tốt hơn sau mỗi lần, làm cho mã nguồn chạy nhanh hơn, giảm yêu cầu bộ nhớ, v.v. Đây là sơ đồ của kịch bản đó.
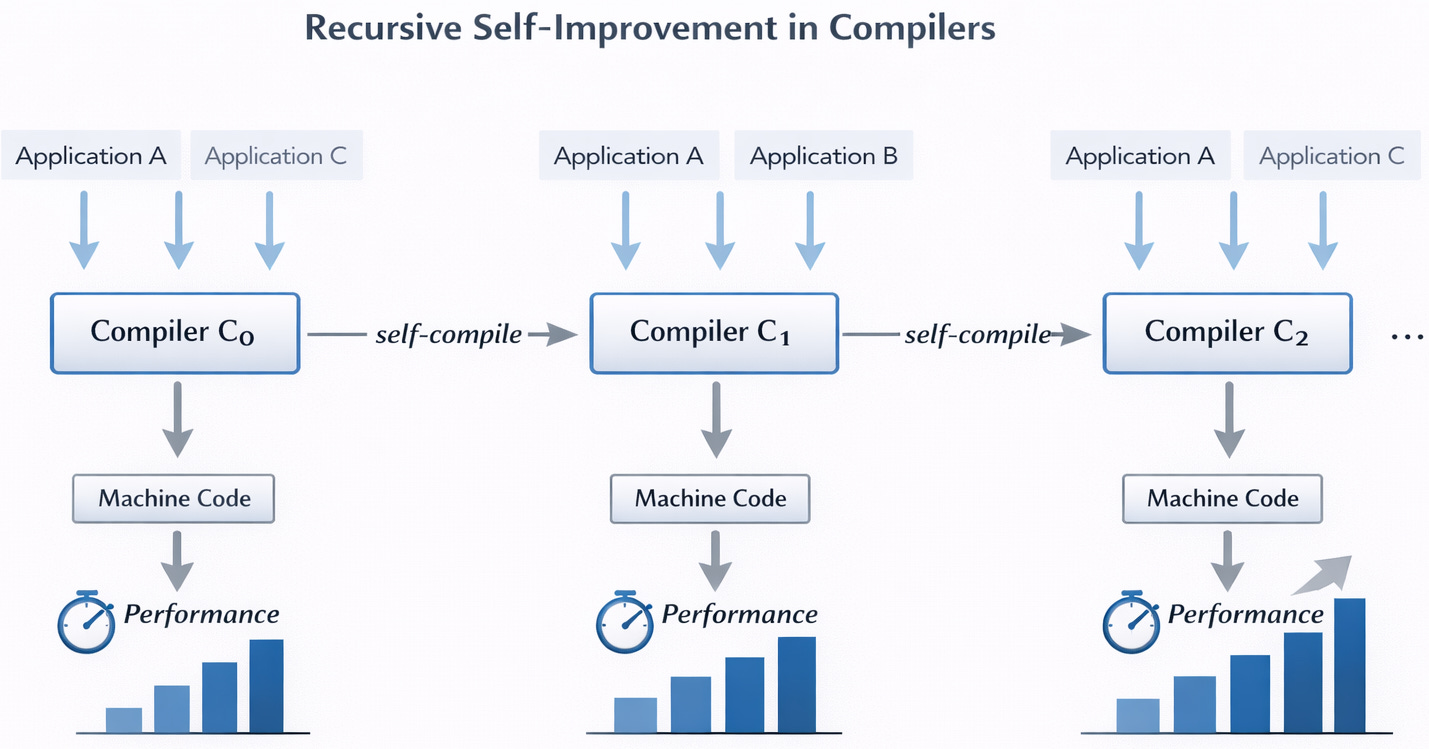
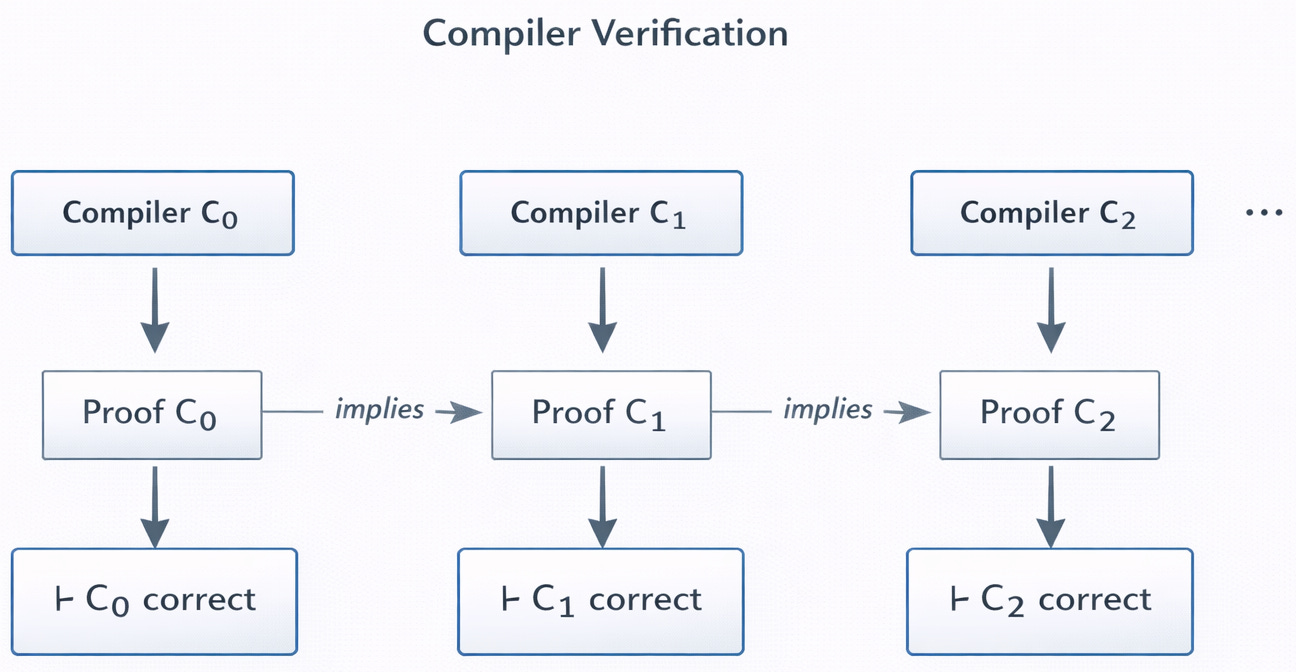
Để kết hợp phương pháp tiếp cận này với formal verification, chúng ta bắt đầu bằng cách thực hiện một chứng minh được kiểm tra bằng máy rằng compiler ban đầu là chính xác. Nghĩa là, chúng ta muốn biết rằng, bất kể chương trình nào chúng ta đưa vào compiler (source program), chương trình đầu ra kết quả (target program) đều thể hiện cùng một hành vi. Ví dụ, chúng ta có thể yêu cầu một target program, khi nhận bất kỳ đầu vào nào, đều tạo ra cùng một đầu ra như source program của nó. Tại thời điểm này, chúng ta nhận thấy một sự hội tụ đáng yêu: bản thân một compiler nhận đầu vào và tạo ra đầu ra, và giờ đây định lý của compiler được áp dụng cho việc biên dịch chính nó! Chứng minh compiler ban đầu có lẽ liên quan đến toán học chuyên ngành (xoay quanh formal semantics của các ngôn ngữ lập trình), nhưng giờ đây tất cả những gì chúng ta cần biết là compiler bảo toàn hành vi chức năng (functional behavior). Trên thực tế, đối với bất kỳ số lần lặp lại nào của vòng lặp recursive self-improvement này, tính chính xác của compiler cuối cùng tuân theo phép chứng minh quy nạp toán học mathematical induction (chuyển đổi các đảm bảo của từng bước đơn lẻ thành đảm bảo của toàn bộ đường đi từ điểm bắt đầu đến các bước sau). Chứng minh là sự kết hợp của định lý chính xác ban đầu với một số lượt cụ thể hóa (specializations) của chính nó cho các phiên bản kế tiếp của source code của chính nó.
Quá trình này là một ví dụ điển hình về cấu trúc đệ quy lắt léo trong khoa học máy tính mà bằng cách nào đó vẫn hoạt động tốt. Tuy nhiên, nó tương đối hiếm khi được thực hiện trong thực tế. Verified compiler nổi tiếng nhất hiện nay là CompCert, có ngôn ngữ nguồn (C) khác với ngôn ngữ triển khai của chính compiler (ngôn ngữ gốc của Rocq), vì vậy vì những lý do tương đối rõ ràng, CompCert không thể tự biên dịch chính nó. Dự án của riêng tôi Fiat Cryptography bao gồm một compiler được triển khai bằng Rocq và biên dịch một nhóm con (subset) của ngôn ngữ gốc Rocq, nhưng nhóm con đó không đủ sức biểu đạt để compiler được viết trên đó, dẫn đến cùng một trở ngại đối với recursive self-improvement. Có lẽ ví dụ nổi bật nhất hiện nay thực sự đạt được verified self-compilation là CakeML.
Bây giờ, hãy thử nghĩ về vòng lặp recursive self-improvement này giống như những gì chúng ta thấy đang diễn ra, hiện tại chủ yếu được thúc đẩy bởi nỗ lực kỹ thuật của con người, để tối ưu hóa các tech stacks cho huấn luyện (training) và suy luận (inference) AI. Một bài toán thách thức lý tưởng để lập luận về công việc đó được thực hiện một cách an toàn sẽ bao gồm các độ phức tạp kỹ thuật làm cho các hệ thống đó khó xây dựng và lập luận. Tôi đã xác định được hai độ phức tạp phần lớn còn thiếu trong cả hai hướng nghiên cứu trước đây về xác minh compiler lẫn các phương pháp tiếp cận hình thức đối với AI alignment. Tôi cũng nghĩ rằng có lý do để tin rằng (mặc dù tôi không thể trình bày hết trong một bài viết này) cả hai độ phức tạp này sẽ vẫn tồn tại cùng chúng ta – chúng được chứng minh rõ ràng là các công cụ để tạo ra các hệ sinh thái thông minh ngày càng có năng lực cao hơn.
Các verified compilers trong quá khứ liên quan đến việc tìm kiếm trong các không gian chương trình lớn ở mức tương đối đơn giản, điều này có lẽ là cần thiết nếu chúng ta hy vọng bắt chước cách con người đang đạt được tiến bộ trong việc cải thiện các tech stacks này. Trực giác cho sự tồn tại lâu dài của kỹ thuật này: chúng ta thường xuyên gặp phải các thách thức thiết kế đủ khó để không thể chỉ nhắm trực tiếp vào các giải pháp cạnh tranh.
Được thúc đẩy một phần bởi chi phí khám phá các không gian tìm kiếm đó, chúng ta gần như chắc chắn cần phải dựa vào tính song song rộng rãi (extensive parallelism), với nhiều luồng tính toán khác nhau diễn ra đồng thời trong chính compiler, chứ không chỉ trong các ứng dụng mà nó biên dịch. Thật vậy, các ứng dụng deep-learning trong thực tế phụ thuộc vào lượng lớn tính song song, và theo tôi, chúng ta chưa thấy cấu trúc tương tự gần như đủ trong các compilers, chưa nói đến các compilers đã được xác minh. Trực giác cho sự tồn tại lâu dài của kỹ thuật này: nhận được câu trả lời nhanh hơn hoặc với chi phí thấp hơn đã mang lại lợi ích to lớn trong nền kinh tế ngày nay, chưa kể đến những gì có thể xảy ra trong tương lai với siêu trí tuệ, và ngày nay hầu hết các nhà khoa học máy tính đều đồng ý rằng parallelism là yếu tố quan trọng để tiếp tục cải thiện hiệu năng sau khi định luật Moore kết thúc (xem thêm bài viết There’s Plenty of Room at the Top).
Đó là cách tôi định hình một bài toán thách thức mà tôi nghĩ có thể được khám phá một cách hiệu quả trong nghiên cứu ngắn hạn: recursive self-improvement thông qua một verified compiler tìm kiếm song song các không gian lớn của các chương trình thay thế. Các thách thức và giải pháp phát sinh trong nỗ lực đó có thể cung cấp thông tin cho suy nghĩ rộng hơn về AI safety. Hãy để tôi dự đoán một vài điều trong số đó bằng cách đưa ra các vấn đề xuất hiện lặp đi lặp lại trong formal verification truyền thống hơn, thường gắn liền với các mối lo ngại về bảo mật.
Lỗi bất ngờ số 1: Nondeterminism
Nondeterminism dường như là một thuộc tính vô hại của một chương trình: nó không phải lúc nào cũng đưa ra cùng một câu trả lời, và chúng ta cho phép nó tự do lựa chọn một câu trả lời khác nhau mỗi khi chúng ta gọi nó với cùng các đầu vào. Rắc rối xảy ra khi chúng ta tưởng tượng kẻ thù tồi tệ nhất của mình được quyền can thiệp để phá vỡ thế cân bằng và lựa chọn giữa các kết quả khả thi. Trong bối cảnh AI-safety, các quyết định có thể được đưa ra bởi một siêu trí tuệ khó hiểu, nhưng các rủi ro tương tự đã được nghiên cứu rộng rãi trong bảo mật máy tính, nơi cái gọi là đối thủ (adversary) theo quy ước là một con người.
Một thuộc tính bảo mật kinh điển tương tác kém với nondeterminism là secure information flow. Hãy xem xét ví dụ sau đây về một nhân viên truy cập hộp thư đến email công ty của anh ta, trong hai trạng thái khác nhau của thế giới.
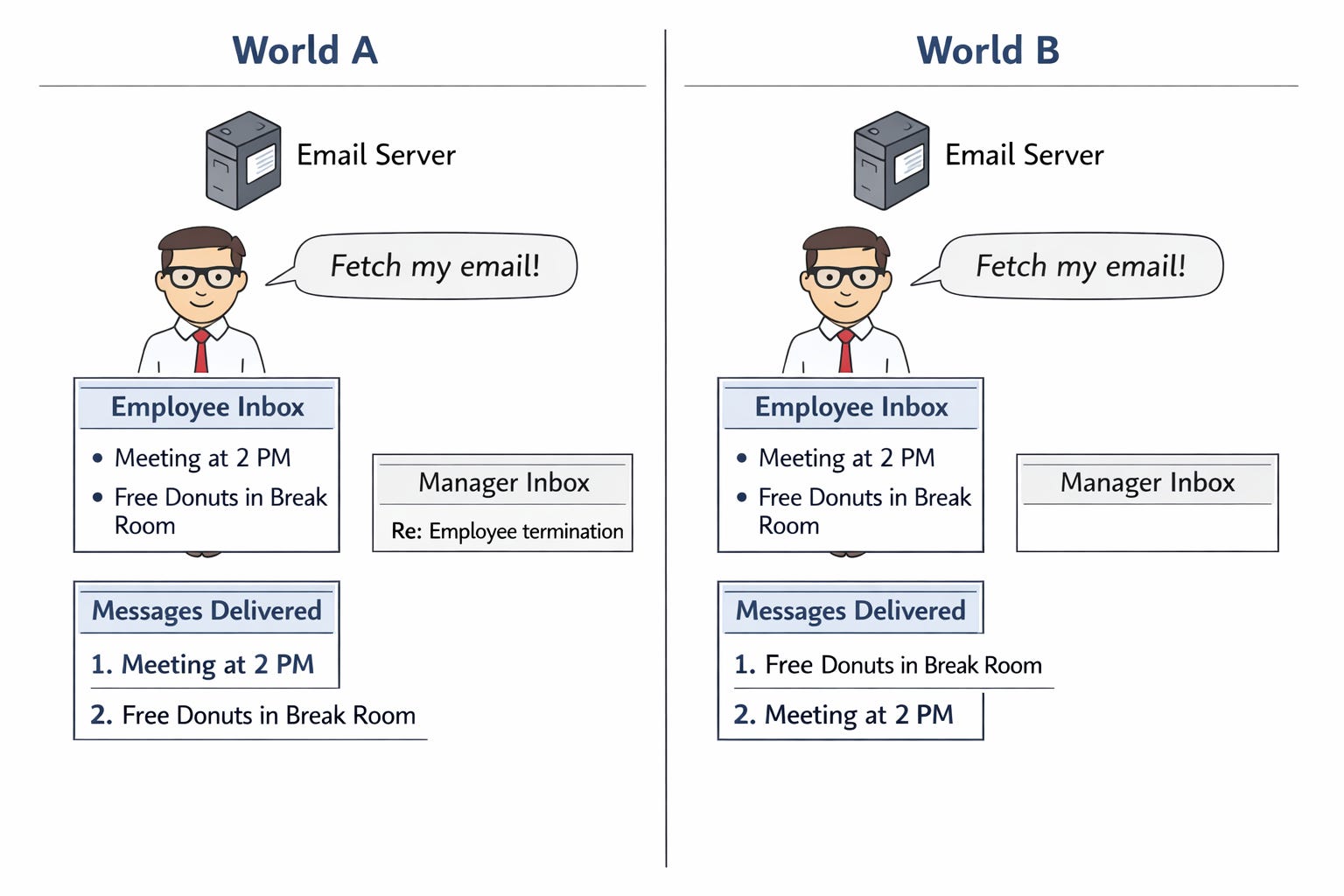
Mọi thứ trong máy chủ email mà nhân viên được phép biết đều như nhau giữa hai thế giới. Sự khác biệt duy nhất là ở hộp thư đến email của sếp anh ta. Giả sử chúng ta hào phóng với nondeterminism khi đặc tả máy chủ email. Khi người dùng yêu cầu danh sách tin nhắn, nó có thể được gửi theo bất kỳ thứ tự nào – ví dụ: thứ tự các bản ghi được lưu trữ trên đĩa, một tối ưu hóa hiệu năng tiện lợi. Tuy nhiên, nếu chúng ta cho phép hoàn toàn tự do trong lựa chọn này, chúng ta không ngăn được máy chủ email tham khảo bí mật của người dùng khác để chọn thứ tự đó. Và sự tự do hoàn toàn, ngay cả việc chọn các thứ tự lắt léo, chính là những gì đặc tả chức năng nondeterministic ngây thơ cho phép.
Thực sự không khó để tìm thấy các rủi ro tương tự trong ví dụ compiler của chúng ta. Giả sử compiler thực sự được cấu trúc như một máy chủ biên dịch chương trình cho nhiều người dùng. Người dùng coi source code của họ là bí mật, nhưng đặc tả nondeterministic rõ ràng của compiler lại cho phép các compiler giải quyết các lựa chọn ngẫu nhiên theo cách tiết lộ mã nguồn giữa các người dùng.
Thông điệp rút ra là nondeterminism và secure information flow không kết hợp tốt với nhau, và có lẽ thông điệp đó là đủ để giúp chúng ta viết đúng đặc tả cho một máy chủ email. Một compiler thì phức tạp hơn. Vấn đề là đặc tả tự nhiên của nó vốn dĩ mang tính chất nondeterministic, nhằm cung cấp cho người viết compiler sự tự do để phát minh ra các tối ưu hóa mới – điều mà chúng ta chắc chắn muốn vòng lặp recursive self-improvement của mình thực hiện. Một source program cho trước có nhiều target programs khả thi đáp ứng đặc tả (mỗi chương trình tính toán cùng một kết quả theo các cách khác nhau). Chúng ta phải khái quát hóa lời khuyên “tránh nondeterminism” sang bối cảnh phức tạp hơn của một compiler. Tôi sẽ phác thảo một giải pháp khả thi dưới đây, sau khi giới thiệu một thách thức khác.
Lỗi bất ngờ số 2: Side Channels
Hãy tưởng tượng chúng ta khóa chặt đặc tả của máy chủ email để bắt buộc trả về câu trả lời deterministic, nhưng ngay cả động thái đó cũng không đủ để bảo mật hệ thống.
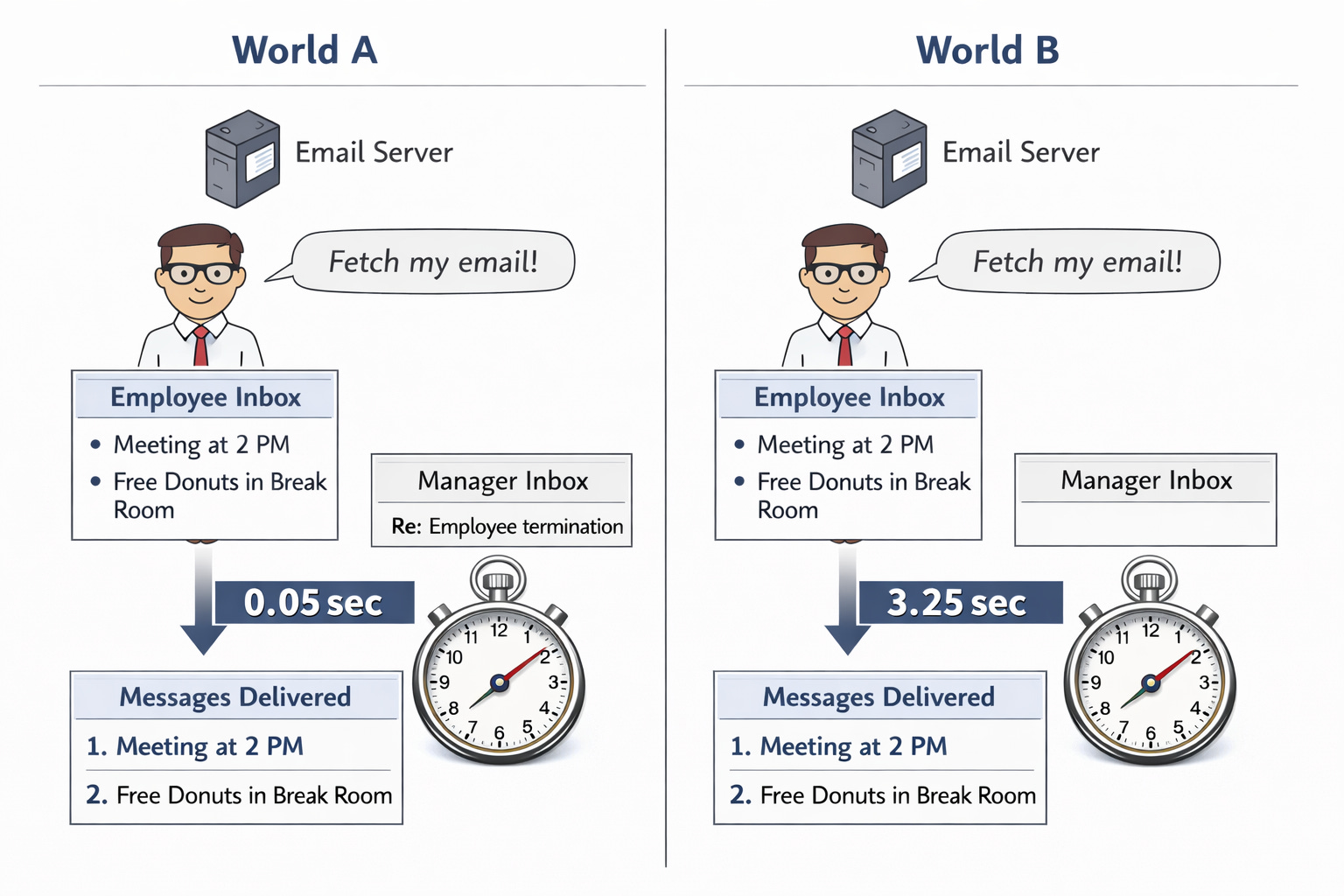
Nhân viên nhận được cùng một câu trả lời trên tất cả các kịch bản, nhưng giờ đây khoảng thời gian cần thiết để câu trả lời được trả về lại tiết lộ điều gì đó về hộp thư đến của sếp anh ta. Tác giả của đặc tả đã mắc một sai lầm kinh điển: quên tính đến một chiều kích phi chức năng (nonfunctional) quan trọng (không có nghĩa là hệ thống bị hỏng mà là chúng ta đang nghĩ về các khía cạnh nằm ngoài việc đưa ra câu trả lời chính xác!), trong trường hợp này là thời gian chạy.
Tin tốt là việc chỉ cần coi thời gian chạy như một chiều kích quan trọng cho phép chúng ta khóa chặt luồng thông tin xấu này, với một mô hình đặc tả tương đối tổng quát tuân theo kỹ thuật tiêu chuẩn của noninterference. Tin xấu là việc chỉ đo lường thời gian cho đến khi câu trả lời đầy đủ sẵn sàng là không đủ để xem xét tất cả các rủi ro về mặt thời gian (timing) trong thế giới thực. Đặc biệt khi chúng ta thêm các rủi ro đó vào, chúng ta thấy mình ở trong lĩnh vực của các side channels, những cách đáng ngạc nhiên và gián tiếp mà hệ thống rò rỉ thông tin. Hãy xem xét phần mở rộng dưới đây của ví dụ đang chạy của chúng ta.

Bây giờ, hai kịch bản tạo ra cùng một câu trả lời trong cùng tổng thời gian – nhưng chuỗi các hành động bên trong (ghi vào RAM) lại diễn ra theo một lịch trình khác nhau trong mỗi thế giới. Tại sao chúng ta lo lắng về một sự khác biệt nhỏ như vậy? Hãy tưởng tượng máy chủ email chạy trên cùng một dịch vụ đám mây với máy chủ của một điệp viên, và điệp viên đó định kỳ kiểm tra những gì đã thay đổi trong bộ nhớ. Tôi sẽ không đi sâu vào chi tiết hơn về các cuộc tấn công khả thi trong bài viết này, nhưng hãy xem các lỗ hổng nổi tiếng như Spectre và Meltdown để biết thêm chi tiết. Điểm mấu chốt là, vì dịch vụ đám mây có thể chia sẻ RAM giữa các dịch vụ của khách thuê, nên có khả năng rò rỉ thông tin qua tài nguyên dùng chung đó, bao gồm cả thông qua timing.
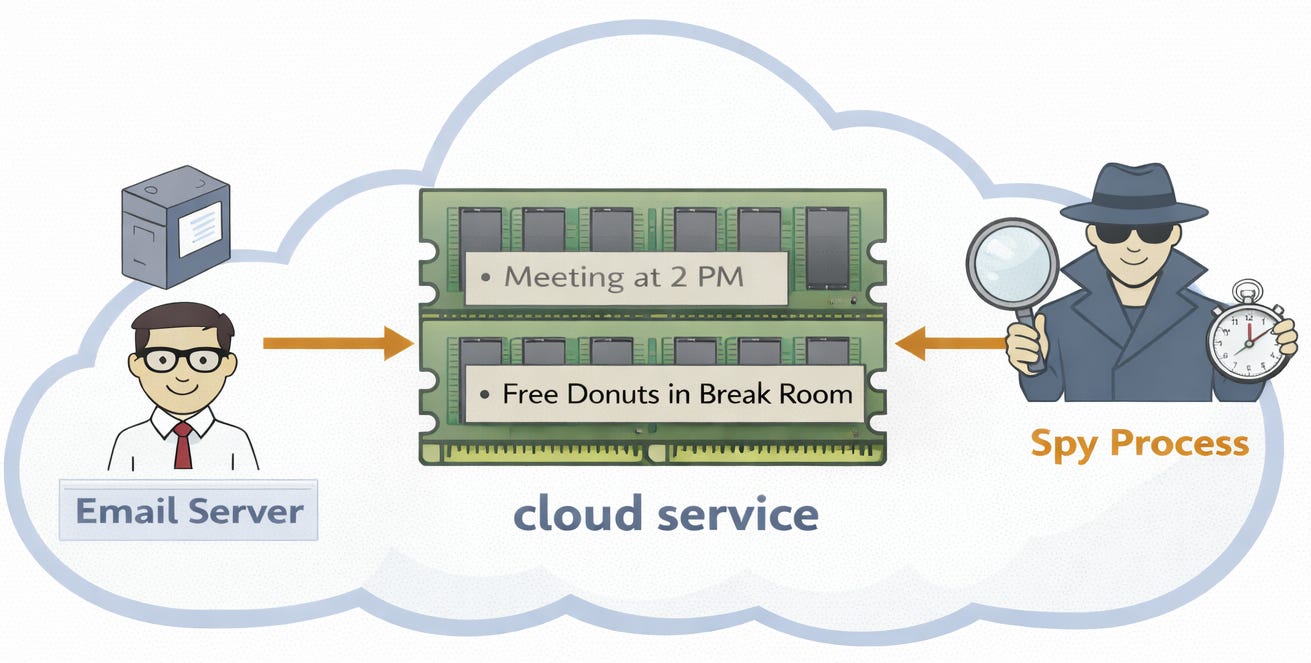
Đã có nhiều nghiên cứu gần đây về loại vấn đề này, xác minh hình thức việc không tồn tại các side channels không mong muốn. Một lớp giải pháp chung dựa trên ý tưởng tránh nondeterminism mà không đi đến cùng cực. Ví dụ, một trong những dự án gần đây của tôi chỉ ra cách chứng minh rằng các compilers tránh việc tạo ra timing side channels, bằng cách yêu cầu mỗi lượt chạy compiler riêng lẻ chọn một hành vi deterministic, chỉ bị ảnh hưởng bởi các phần của trạng thái chương trình không cần giữ bí mật. Chúng tôi đã áp dụng một cách tiếp cận tương tự để chứng minh rằng phần cứng giữ cho các máy chủ không tìm hiểu được bí mật của nhau.
Cuộc thảo luận này gợi ý một mô hình thiết kế mạnh mẽ: xác định một không gian của các hành vi được phép (hoặc các hàm hành vi), nơi bất kỳ hàm nào cho trước đều được “khóa chặt” một cách an toàn, và cho phép một hệ thống chọn chính xác một trong số chúng. Ví dụ, bằng cách nào đó chúng ta biết rằng mọi hàm đều tôn trọng quyền con người, nhưng các hàm khác nhau thiết kế các nhà máy tương lai theo những cách rất khác nhau. Mẹo có thể tái sử dụng là không đi đến bất kỳ thái cực nào của một đặc tả – hoặc là nondeterministic một cách mơ hồ hoặc là deterministic một cách cứng nhắc, thay vào đó hãy xây dựng cẩn thiện một menu các hàm deterministic có thể chấp nhận được và để hệ thống chọn một hàm. Nếu chúng ta thiết kế menu đúng cách, hệ thống “chỉ có thể làm chúng ta ngạc nhiên chính xác một lần,” sau đó hành vi của nó bị giới hạn trong một không gian cụ thể mà chúng ta xác định là an toàn. Bài viết này chủ yếu tập trung vào việc chỉ ra một vấn đề đáng nghiên cứu, mặc dù ý tưởng từ đoạn này là thứ gần nhất tôi có đối với một nguyên tắc giải pháp tái sử dụng được cho alignment để đề xuất ở thời điểm hiện tại; vấn đề dường như có cơ hội tốt để tạo ra nhiều giải pháp hơn nữa, nếu được giải quyết đúng cách.
Kết luận
Bài toán thách thức cụ thể là xây dựng một compiler có các khả năng
có thể tự biên dịch chính nó,
áp dụng tính toán song song quy mô lớn (parallel compute), theo phong cách quen thuộc của deep learning ngày nay, để đưa ra quyết định tốt hơn, và
được xác minh hình thức (formally verified) để đáp ứng không chỉ các yêu cầu chức năng mà còn cả bất kỳ yêu cầu phi chức năng nào rõ ràng là quan trọng.
Tôi đang cố gắng lập luận rằng vấn đề này ở mức độ khó “vừa tầm” và có khả năng ứng dụng vào các vấn đề AI-safety cốt lõi. Nhiều câu hỏi nền tảng đã được khám phá sâu rộng trong formal verification, đặc biệt là xung quanh bảo mật chống lại các đối thủ con người. Chúng ta có cả kỹ thuật lý thuyết lẫn các triển khai phi vụn vặt. Tôi sẽ phác thảo một số yếu tố thú vị nhất trong các bài viết sắp tới, bao gồm:
Các kỹ thuật viết các đặc tả để tránh các sai lầm nghiêm trọng
Tự động hóa có khả năng mở rộng của việc viết chứng minh cho các cơ sở mã nguồn phức tạp
Mở rộng phạm vi bao phủ của vòng lặp cải tiến mã nguồn để không chỉ bao gồm phần mềm mà còn cả phần cứng mà nó chạy trên đó
Làm thế nào để tránh việc biến bản thân bộ chứng minh định lý (theorem-prover) thành nguồn phát sinh các lỗi nguy hiểm
Cách cấu trúc các compilers và các phần quan trọng khác của hạ tầng để giúp xác minh dễ dàng hơn
Các kỹ thuật đầy hứa hẹn để kết hợp những gì tốt nhất của deep learning và các phương pháp dựa trên logic
Tuy nhiên, bài viết ngay tiếp theo sẽ xem xét một kịch bản khoa học viễn tưởng bổ sung thêm sự phức tạp của các tác tử cùng làm việc với nhau để xây dựng các hệ thống tốt hơn, ngay cả khi chúng không hoàn toàn tin tưởng nhau, ngược lại với ý tưởng của bài viết này về một trí tuệ tiêu tốn nhiều tài nguyên tính toán để tự cải thiện trong sự cô lập. Chúng ta sẽ thấy formal verification vẫn có thể giúp ích như thế nào.
I'm experimenting again with crossposting to LessWrong, and you may find additional discussion there.
https://www.lesswrong.com/posts/pnPDd8uo2NZqn2dtG/safe-recursive-self-improvement-with-verified-compilers
This is not quite the challenge you outline in this post, but seems fairly related, scoping out a smaller subset of the problem which seems out of the capabilities of current models: https://www.basis.ai/blog/verified-compiler/