
Formal Verification: Fitness Function tối thượng
Cách tăng tốc evolutionary search đồng thời xây dựng lòng tin vào kết quả của nó

Ba bài viết trước đã thiết lập một lộ trình nhằm hiểu cách thế giới tự nhiên tiến hóa hoạt động dưới góc nhìn máy tính, từ đó chúng ta có thể hướng tới việc chủ động thiết kế một cấu trúc thay thế tận dụng tối đa AI. Một trong những quan sát quan trọng ở cuối chuỗi bài đó là các AI agent khác biệt đáng kể so với các nhà khoa học và kỹ sư con người: một AI agent có source code mà chúng ta có thể phân tích theo nhiều cách khác nhau. Một phân tích tốn kém nhưng đáng tin cậy bởi một bên đáng tin có thể được phân phối tới nhiều bên ra quyết định bằng cách sử dụng cryptography, nhưng làm thế nào chúng ta có thể thực hiện một phân tích như vậy một cách thực tế đối với các agent có source code phức tạp?
Bài viết này là màn ra mắt chính thức cho kỹ thuật formal verification, một trong những thành phần phổ biến nhất trong nghiên cứu của riêng tôi, hóa ra lại là một giải pháp tuyệt vời cho câu đố cuối cùng đó. Nó đưa các "Guarantees" (Đảm bảo) vào tên của blog này. Tôi sẽ lập luận rằng, khi chúng ta có cái nhìn dài hạn về sự tiến hóa của sự sống thông minh, formal verification có thể đóng một vai trò quan trọng, nơi việc tích hợp nó vào quá trình chuyển dịch sang phụ thuộc nhiều hơn vào AI có thể mang lại cho chúng ta một kết quả đôi bên cùng có lợi (win-win) khó tin: chúng ta có thể làm cho quá trình tiến hóa nhanh hơn trong việc phát triển các đổi mới kỹ thuật, đồng thời đạt được sự tự tin (confidence) cao hơn rằng quy trình đó liên kết (align) với các mục tiêu của chúng ta.
Nói một cách đại khái, formal verification là việc sử dụng mathematical proof để chứng minh hành vi chính xác của các chương trình. Trái ngược với testing, một proof có thể bao quát tất cả các tình huống có thể xảy ra mà một chương trình gặp phải. Điểm mấu chốt là chúng ta phải quyết định định lý hoặc specification nào cần chứng minh về chương trình đó. Nếu chúng ta chứng minh nó tuân theo một quy tắc nào đó nhưng thực tế lại không khớp với các mục tiêu thực sự của mình, thì chúng ta thậm chí có thể tồi tệ hơn trước, với một cảm giác an toàn giả tạo.
Giới thiệu formal verification tới đông đảo công chúng trước đây từng đòi hỏi khá nhiều sự chuẩn bị thiết lập, nhưng ngày nay tôi có thể nói "nó giống như cách những người sáng tạo ra các foundation model đang benchmark chúng bằng việc tự động viết các mathematical proof (ví dụ như với AlphaProof), ngoại trừ việc tôi đang nói về việc chỉ ra tính chính xác của các chương trình thay vì các định lý trong toán học thuần túy." Tôi có lẽ không phải là chuyên gia duy nhất về formal methods cảm thấy ngạc nhiên khi việc trích dẫn các công trình toán học thuần túy lại hữu ích để chứng minh sự quan tâm và tính khả thi của nó đối với phần mềm thực tế; thông thường chiến lược marketing sẽ đi theo hướng ngược lại!
Tôi sẽ dành các chi tiết kỹ thuật sâu hơn (trong đó có nhiều danh mục liên quan) cho các bài viết trong tương lai. Mục tiêu của tôi trong bài viết này là giải thích vai trò then chốt mà formal verification có thể đảm nhận trong evolutionary search. Tôi sẽ bắt đầu bằng một ví dụ cụ thể được sử dụng trong code production mà bạn có thể đang chạy để đọc bài viết này. Sau đó, tôi sẽ lùi lại để triết lý về cách quá trình tiến hóa kéo dài hàng tỷ năm có thể có một nâng cấp nền tảng nhờ sử dụng các phương pháp như vậy. Hai bài viết tiếp theo sẽ cụ thể hơn về việc sử dụng những ý tưởng này để giải quyết các biến thể của các vấn đề quan trọng trong AI safety. Một bản xem trước của khẳng định chính là formal verification mở khóa một loại fitness function mới cho evolutionary search, mang lại các chu kỳ phản hồi ngắn hơn đáng kể so với những gì natural selection từng tìm thấy hoặc thậm chí so với những gì ngành kỹ nghệ chính thống (mainstream engineering) ngày nay có thể thực hiện được.
CryptOpt: Tìm kiếm Cryptographic Code tốc độ cao
Hãy để tôi sử dụng một ví dụ cụ thể kết hợp giữa evolutionary search và formal verification để viết code tốt hơn. Hai dự án nghiên cứu và nguồn mở mà tôi từng tham gia là Fiat Cryptography (research paper, GitHub) và CryptOpt (research paper, GitHub). Fiat Cryptography là một domain-specific compiler: nó chuyển đổi các chương trình viết bằng ngôn ngữ lập trình bậc cao, dễ đọc hơn đối với con người thành code hiệu quả mà CPU có thể hiểu trực tiếp hơn. Nó được chuyên biệt hóa cho lĩnh vực cryptography. Điều thú vị về compiler này là nó được formally verified: chúng tôi đã xây dựng một proof có thể kiểm chứng bằng máy rằng nó chỉ tạo ra code tính toán các hàm toán học chính xác. Code chạy nhanh hơn thông thường được viết thủ công bởi con người, những người đôi khi mắc phải các sai sót dẫn đến hậu quả bảo mật. Ý tưởng tự động hóa quy trình đó với các đảm bảo toán học mạnh mẽ nhất đã đủ thuyết phục đến mức hiện tại tất cả các trình duyệt web lớn đều sử dụng Fiat Cryptography để xây dựng các phần trong thư viện của họ cho việc duyệt web an toàn.
Tuy nhiên, các phiên bản đầu tiên của Fiat Cryptography được xuất ra dưới dạng các ngôn ngữ lập trình phổ biến như C rồi sau đó gọi các compiler tiêu chuẩn để hoàn tất công việc, tạo ra assembly code (một số loại code máy tính cấp thấp nhất, dài dòng và dễ sai sót) vốn chậm hơn đáng kể so với những gì các chuyên gia giỏi nhất viết tay. Quan sát đó đã thúc đẩy chúng tôi, những tác giả ban đầu của Fiat Cryptography, tham gia cùng các cộng tác viên mới để xây dựng CryptOpt, sử dụng random program search để đánh giá nhiều chương trình tiềm năng và giữ lại chương trình nhanh nhất.
Chúng ta đã quen thuộc với việc tiến hóa hoạt động trên gia phả của các loài động vật. Chỉ những động vật thành công trong việc sinh tồn và sinh sản mới truyền lại gene của chúng cho các thế hệ sau. Các cá thể mới tiếp nhận sự pha trộn các gene từ cha mẹ thành công của chúng.

Evolutionary search thông qua các chương trình có thể hoạt động tương tự, ngoại trừ việc quần thể ở đây, trong trường hợp của CryptOpt, là các chương trình assembly. Chúng ta đo lường fitness bằng cách chạy các chương trình trên phần cứng mục tiêu thực tế và đo lường hiệu suất (performance) của chúng. Chỉ các biến thể nhanh nhất được biết đến tại bất kỳ thời điểm nào mới "sống sót". Các biến thể chương trình mới được tạo ra bằng cách thử các tinh chỉnh đơn giản trên các chương trình vô địch trước đó, chẳng hạn như sắp xếp lại các instruction của chúng.
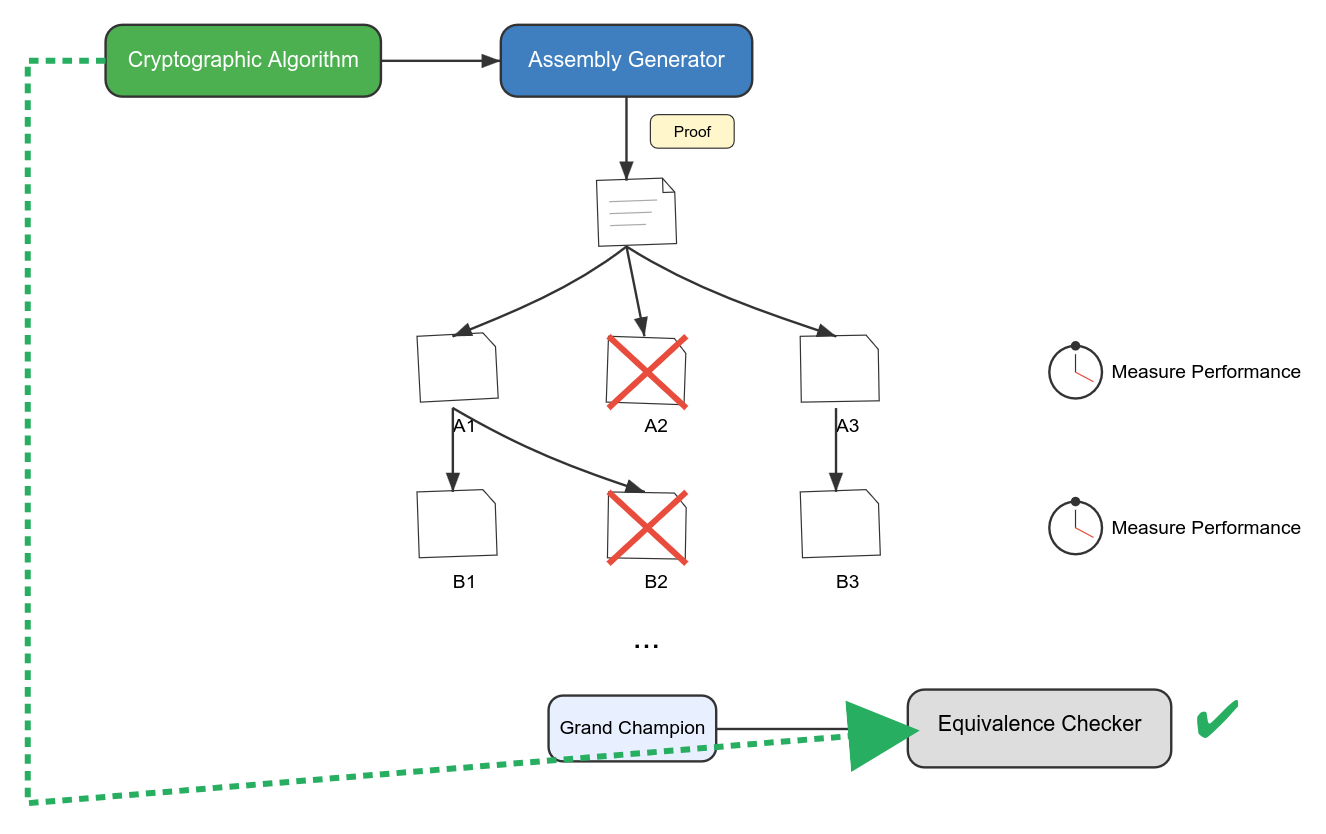
Chúng ta có một fitness function rất hiệu quả cho evolutionary search, dựa trên việc đo kiểm hiệu năng (performance benchmarking) nhanh chóng và tập trung. (Nhân tiện, việc đánh giá hiệu năng hóa ra lại dễ dàng hơn trong lĩnh vực này so với kỹ nghệ phần mềm nói chung, nhờ vào việc áp dụng rộng rãi well-motivated coding guidelines.) Tuy nhiên, chạy nhanh chỉ là một phần của câu chuyện: chúng ta cũng muốn các chương trình đưa ra kết quả chính xác.
CryptOpt được thiết kế để chỉ áp dụng các chuyển đổi bảo toàn hành vi (behavior-preserving) cho các biến thể chương trình, nhưng những chuyển đổi đó vẫn có thể chứa lỗi. Để duy trì các tiêu chuẩn cao về các đảm bảo hình thức (formal guarantees) từ Fiat Cryptography, chúng tôi đã mở rộng dự án sau với một program-equivalence checker mới. Được cung cấp chương trình dạng C ban đầu do Fiat Cryptography tạo ra cùng với chương trình assembly vô địch do CryptOpt tạo ra, bộ kiểm tra này có thể xác định rằng cả hai tính toán cùng một hàm toán học. Mặc dù chúng ta lo ngại rằng việc kiểm tra tương đương (equivalence checking) nói chung là undecidable (về mặt hình thức, không có phần mềm nào có thể trả lời chính xác mọi câu hỏi tương đương), equivalence checker trong trường hợp này đã được codesigned cẩn thận với quy trình tìm kiếm, sao cho các chương trình hợp lệ không bao giờ trượt kiểm tra. Ngoài ra, bản thân equivalence checker cũng đã được formally verified (thông qua nỗ lực viết proof không hề đơn giản của con người), vì vậy không có gì trong quy trình evolutionary search cần phải được tin tưởng một cách mù quáng. Lỗi trong các compiler C tiêu chuẩn cũng không còn khả năng đe dọa tính chính xác nữa: toàn bộ đường dẫn tạo mã (generation path), từ toán học trên bảng trắng đến assembly language, được bao quát bởi một proof tích hợp trong Rocq, và đường dẫn đó hiệu quả đến mức chúng tôi thậm chí đã thiết lập một số kỷ lục hiệu năng mới cho các thuật toán cryptographic cụ thể trên phần cứng cụ thể.
Chúng tôi bắt đầu dự án CryptOpt ngay trước khi ChatGPT giới thiệu với thế giới về tiềm năng của generative AI. Tôi nghĩ chưa có ai thử nghiệm điều này, nhưng có một biến thể tự nhiên của CryptOpt sẽ sử dụng một LLM để đề xuất các biến thể chương trình. Nếu chúng ta sử dụng cùng một loại equivalence checker đã được formally verified để thẩm định mọi đề xuất, thì chúng ta không cần phải tin tưởng LLM, trong khi vẫn tận dụng được tính sáng tạo của nó. Bất kể ý tưởng điên rồ nào mà LLM nghĩ ra, formal verification đảm bảo rằng những ý tưởng được chấp nhận là chính xác. Kết quả là một sự phân công lao động hấp dẫn, giữa một bên (LLM) sáng tạo nhưng không đáng tin cậy và một bên khác (formal verification) làm việc theo nguyên tắc và không bỏ sót bất kỳ chi tiết nào.
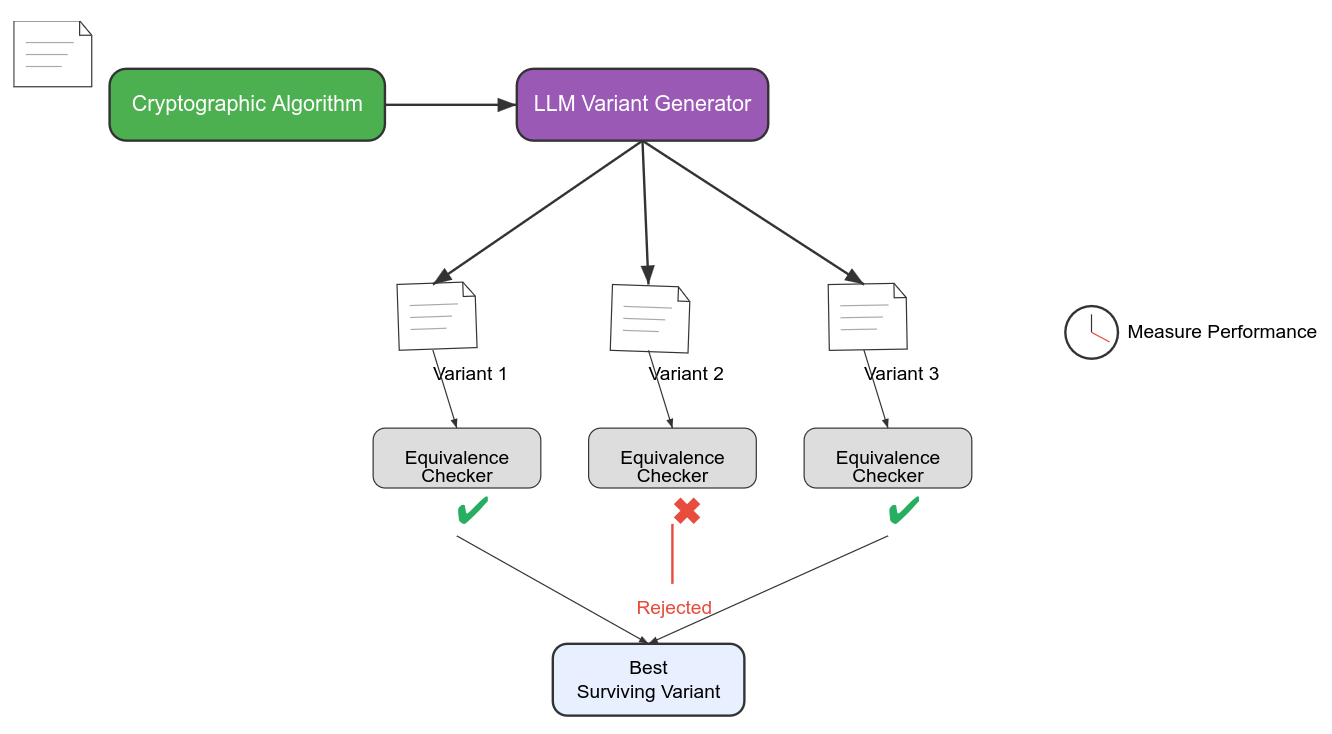
Công thức này là một công thức tổng quát cho evolutionary search được tăng tốc nhằm tìm kiếm các artifact tốt hơn có thể được biểu diễn chính xác trên máy tính. Nó kết nối với các lĩnh vực nghiên cứu đã được thiết lập là superoptimization và program synthesis. Điểm mấu chốt là trong khi tiến hóa tự nhiên (natural evolution) có thể mất cả cuộc đời của một động vật để đánh giá fitness của nó, các formal method cho phép đánh giá trước (up-front evaluation) các cá thể, xem xét mức độ chúng đáp ứng các yêu cầu trong vô số "cuộc đời" mà chúng có thể trải qua. Bây giờ hãy để tôi lùi lại một bước và đặt lợi thế đó vào bối cảnh, trong tiến trình từ vật chất vô tri đến con người có trí tuệ.
Các giai đoạn tiến hóa
Chúng ta hãy xem xét năm giai đoạn tiến hóa như một dạng bậc thang, dẫn đến một giai đoạn phụ thuộc rất nhiều vào phương pháp tôi vừa giải thích. Việc nền tảng kiến thức nằm ngoài khoa học máy tính chuẩn bị cho chúng ta thấy lợi thế thuật toán (algorithmic advantage) cơ bản nào mà formal verification có thể mang lại cho các quy trình tìm kiếm, với các ứng dụng cho các lĩnh vực mang tính thời sự như AI safety. Trình tự này tương tự như các kỷ nguyên của Kurzweil trong cuốn The Singularity is Near, nhưng tôi sẽ đi sâu hơn vào các chi tiết triển khai mang tính kỹ thuật.
Giai đoạn 1: Vật chất vô tri
Vũ trụ ở trong một trạng thái mà chúng ta thấy rất ngẫu nhiên. Mọi thứ thay đổi theo từng khoảnh khắc, nhưng vẫn chưa có các mô hình rõ ràng. Chúng ta không thấy bất kỳ điều gì đang diễn ra có thể được gọi là trí thông minh (intelligence).
Giai đoạn 2: Natural Selection
Một số mô hình có khả năng tự duy trì đã phát triển và bắt đầu một chu kỳ tích cực, thông qua các replicator như gene. Bản thiết kế cho các sinh vật được sao chép và tái tổ hợp qua các thế hệ, với những đột biến tương đối nhỏ. Những cá thể ít có khả năng sinh tồn hoặc sinh sản tự nhiên hơn sẽ có gene ít ảnh hưởng đến các thế hệ tương lai hơn. Tuy nhiên, có một quy trình phản hồi rất chậm đối với distributed evolutionary algorithm mà chúng ta có thể hình dung là đang chạy. Sự thật khách quan (ground truth) có thể là một cá thể tương đối không thích nghi (unfit) trong môi trường của nó, nhưng cá thể đó vẫn lết đi được một thời gian khá dài. Chúng ta chỉ có thể kỳ vọng một lượng tìm kiếm hiệu quả có giới hạn với một "trọng tài" đánh giá fitness (sự sinh tồn và sinh sản chênh lệch) mà hầu hết chúng ta không coi là thông minh.
Giai đoạn 3: Sexual Selection và Signaling
Các cá thể bắt đầu đánh giá lẫn nhau thông qua sexual selection và signaling. Bộ não có thể đánh giá fitness của các bộ não và cơ thể khác, đưa ra những quyết định ảnh hưởng đến sự sinh tồn và sinh sản của những cá thể mà chúng đánh giá. Các quy tắc đánh giá thậm chí có thể được "lập trình" thông qua văn hóa, để thích ứng khi bối cảnh tiến hóa thay đổi. Các cá thể học cách thể hiện các tín hiệu tốn kém (costly signals) để khiến bản thân dễ được đánh giá hơn. Những tín hiệu này cho phép một vòng phản hồi nhanh hơn nhiều đối với distributed algorithm để đo lường fitness và hành động tương ứng, vì thời điểm mà một cá thể có thể tạo ra tín hiệu phù hợp có thể sớm hơn nhiều bậc so với thời điểm nó gặp phải một "tình huống thực tế" đòi hỏi kỹ năng cần được báo hiệu đó. Tuy nhiên, tương tự như trong software testing, một sự kết hợp tín hiệu cụ thể vẫn có thể che giấu những lỗi nghiêm trọng, nhưng thật khó để làm tốt hơn nếu không có một cách tốt để nội soi (introspect) vào "code" của một cá thể.
Giai đoạn 4: Con người triển khai các AI Agent
Bây giờ chúng ta đến với một bước chuyển dịch nền tảng trong trí thông minh vốn đã diễn ra. Việc thiết kế rõ ràng bởi những bộ óc tốt nhất có thể tạo ra những ý tưởng tốt hơn so với một quy trình tiến hóa phần lớn là "brute-force" (dựa trên sức mạnh thô bạo), ngay cả khi quy trình sau có xuất phát điểm trước hàng tỷ năm, là điều có vẻ trực quan hợp lý. Chúng ta thậm chí có thể xem việc thiết kế rõ ràng trí thông minh bởi một trí thông minh khác là một cột mốc vũ trụ quan trọng giúp tăng tốc dòng chảy lịch sử. Tuy nhiên, chúng ta nên thừa nhận rằng trí thông minh có tính toán của chúng ta nằm trong một bối cảnh tiến hóa, bao gồm cả lựa chọn cá thể và group selection. Mô tả về hai giai đoạn tiếp theo nên được diễn giải dưới góc nhìn đó.
Đây là nơi trạng thái thực hành ngày nay đang đứng (dĩ nhiên là bên cạnh các chế độ tiến hóa trước đó). Các lập trình viên (thường có sự trợ giúp từ các AI coding agent) phát triển các AI agent mới, suy nghĩ cẩn thận về những năng lực mà các agent đó nên có. Testing vẫn có thể được sử dụng (và thực sự là phương pháp thống trị) để xác nhận mức độ hoạt động hiệu quả của các agent mới so với mục tiêu của người tạo ra chúng. Về mặt lý thuyết, chúng ta cũng có thể phân tích mã của các agent để đưa ra các lập luận chặt chẽ về hành vi tương lai của chúng. Tuy nhiên, việc thực hiện phân tích này trên các code base phức tạp là rất khó khăn.
Nó rất khó khăn ngay cả trong một đội ngũ kỹ sư tích hợp chặt chẽ, nhưng một khía cạnh khác của đổi mới công nghệ ngày nay là các đội ngũ vừa cạnh tranh vừa lấy cảm hứng từ công việc của nhau. Chi phí để áp dụng một ý tưởng từ đối thủ cạnh tranh là rất cao, vì bạn cần một người có chuyên môn không kém nhà phát minh là bao để đi qua toàn bộ lập luận ủng hộ ý tưởng đó. Chúng ta thậm chí có thể hình dung các nhóm thiếu trung thực xuất bản các ý tưởng mà họ biết là tồi tệ nhưng được thiết kế để thu hút đối thủ cạnh tranh áp dụng chúng. Việc tận dụng lợi thế của low-cost cloning để tạo ra bao nhiêu bản sao của một agent tùy thích là rất hấp dẫn, nhưng việc thẩm định (due diligence) lại rất tốn kém với các phương pháp chính thống hiện nay.
Giai đoạn 5: Automated Search được hỗ trợ bởi Formal Verification
Formal verification cung cấp thành phần còn thiếu. Khi quy trình tìm kiếm tinh chỉnh các agent, nó có thể tạo ra các mathematical proof rằng chúng đáp ứng các specification phù hợp. Những proof này có thể bao quát tất cả các kịch bản khả thi. Chúng cũng tương đối dễ dàng để các bên thứ ba hoài nghi kiểm tra lại, ngay cả khi các proof đó rất khó tìm. Những bên thứ ba đó cũng có thể ủy thác việc kiểm tra proof cho các bên đánh giá có nguồn lực tốt thông qua cryptography. Kết quả thu được là một công cụ mới mẻ trong lịch sử: một fitness function có thể được đánh giá gần như lập tức (thông qua việc kiểm tra proof) nhưng lại bao quát mọi tình huống mà một agent có thể được yêu cầu xử lý.
Để làm cho nó hoạt động, chúng ta cần vượt qua một số rào cản kỹ thuật có vẻ rất thách thức, chẳng hạn như thiết kế đúng đắn các specification (tính chính xác hoặc độ an toàn thực sự có nghĩa là gì đối với các AI agent mạnh mẽ?) và việc mở rộng quy mô (scaling) của các công cụ tìm kiếm proof. Tôi tin rằng triển vọng giải quyết toàn bộ vấn đề là rất tốt, nhưng các chi tiết sẽ phải chờ đợi những gì tôi hứa là sẽ trình bày sâu rộng trong các bài viết tương lai. Ngoài ra, hãy để tôi đề cập ở đây rằng lĩnh vực nghiên cứu đang phát triển mạnh mẽ về xác minh cho các neural network có liên quan nhưng bao gồm một phạm vi nhỏ hơn, vừa (1) vì chúng ta có thể muốn có sự đảm bảo trong phần mềm không sử dụng neural network hoặc vẫn chứa các thành phần quan trọng khác, và vừa (2) vì một phương pháp rất liên quan là correct-by-construction software generation, nơi chúng ta biết một chương trình là chính xác nhờ vào cách nó được viết, mà không cần phân tích mã nguồn cuối cùng sau đó.
Kết luận
Lập luận của tôi đại khái là formal verification có thể cung cấp sức mạnh cho một bước tiến "vẹn cả đôi đường" (have-your-cake-and-eat-it-too) trong tiến trình công nghệ. Các cuộc tranh luận xung quanh tương lai của AI thường đối lập giữa công việc phát triển năng lực (capabilities) và safety. Evolutionary search kết nối với các formal method có thể nâng cao capabilities bằng cách giảm thiểu đáng kể chu kỳ phản hồi để đánh giá fitness của các biến thể mới, ngay cả trong các distributed system nơi các ý tưởng được trao đổi giữa các bên không tin tưởng lẫn nhau. Tuy nhiên, kỹ thuật này cũng có thể tăng cường safety thông qua việc kiểm tra chi phí thấp và đáng tin cậy rằng tất cả các biến thể đều đáp ứng các specification phù hợp. Không chỉ có tiềm năng khám phá ra các cấp độ trí thông minh mới trong thời gian ngắn hơn nhiều so với thời gian natural evolution phát hiện ra chúng ta, mà chúng ta thậm chí còn có thể thực hiện điều đó theo cách đảm bảo các trí thông minh mới đó đồng thuận với chúng ta trong các khía cạnh quan trọng.
Có rất nhiều chi tiết cần phải giải quyết đúng đắn để đưa ý tưởng này vào thực tế. Tôi sẽ đề cập đến nhiều chi tiết trong số đó trong các bài viết tương lai. Để bắt đầu, hãy thực hiện một bước cụ thể hơn bằng cách xem xét (trong hai bài viết tiếp theo) hai mối quan ngại phổ biến trong AI safety và xem mô hình này có thể giúp giải quyết chúng như thế nào, bắt đầu với recursive self-improvement.
I’m experimenting with crossposting this one to LessWrong; you may find additional discussion there:
https://www.lesswrong.com/posts/yFtcb6TLBKA8ob63K/formal-verification-the-ultimate-fitness-function
The more I learn about formal verification, the more I start to understand it's usefulness especially when it comes to security. I can't help but think about it being used as a way to perform 'malicious compliance' through code. As in, exposing the flaws (or technically, proving that something is secure) of a specific program's algorithm by just writing a proof about it. "Well, if I can just prove that there's no bugs in my code, then obviously my code must be bug free!" is how I imagine that scenario.
But now I'm wondering if someone has tried to prove something absurd and just ended up with a program that takes an insane amount of processing power to execute. That's gotta be a thing somewhere. As always, these posts leave me with more questions than answers. Keep up the good work!