
Codesign cho AI và Programming
Một trường hợp rõ ràng nơi sức mạnh của sự đơn giản hóa nằm trong tay chúng ta

Chúng ta đã xem xét hai lĩnh vực ví dụ về các thách thức đối với AI: natural language, gắn liền mật thiết với phần cứng tinh thần tiến hóa của chúng ta; và autonomous driving, liên quan đến các phần quan trọng của cơ sở hạ tầng nhân tạo. Ngay cả autonomous driving cũng phụ thuộc rất nhiều vào các định luật vật lý nằm ngoài tầm kiểm soát của chúng ta. Giờ đây, hãy để tôi xem xét một lĩnh vực mà chúng ta có quyền kiểm soát cực kỳ lớn đối với bối cảnh bài toán: software programming. Mặc dù các software engineer mới phải đối mặt với một loạt các programming language và tool gây hoang mang, tất cả chúng đều do con người thiết kế và chúng ta có thể quyết định thiết kế lại chúng. Vấn đề là có quá nhiều công việc liên quan đến AI code generation đang diễn ra với giả định rằng các programming tool đã bị đóng băng từ năm 2022.
Có rất nhiều sự phấn khích trong không khí về việc generative AI mang lại những thay đổi to lớn cho khả năng của chúng ta với tư cách là một xã hội, có lẽ đỉnh điểm là superintelligence mà chúng ta thậm chí không thể hiểu được. Tại sao chúng ta lại cho rằng một superintelligence sẽ xây dựng software giống như chúng ta vẫn quen dùng ngày nay? Tuy nhiên, các AI coding agent đang tăng vọt độ phổ biến một cách xứng đáng lại có một điểm yếu cơ bản: chúng được train trên nhiều ví dụ về software mà mọi người muốn write ngày nay. Các coding mistake xuất hiện ở đủ mọi nơi trên mạng sẽ truyền vào danh mục của các AI coding tool. Tiếp tục đi theo quỹ đạo này có thể đưa chúng ta đến một số nơi khá nực cười.

Xin lỗi vì đây là một trò đùa nội bộ của các programmer ngoài kia. Những nhà thám hiểm dũng cảm trong bức tranh hoạt hình đã sử dụng một cuộc tấn công SQL-injection attack để chống lại superintelligence. Đó là một ví dụ điển hình về một coding mistake phổ biến có thể dễ dàng tiếp diễn bởi AI vốn chỉ học từ việc crawling web. Các SQL injection cho phép user đánh lừa hệ thống chạy các instruction tùy ý, điều này đủ nghiêm trọng để nó luôn nằm trong danh sách các danh mục hàng đầu về các vấn đề security. Bỏ qua các security vulnerability thảm khốc, có nhiều cơ hội hơn từ việc tư duy lại về programming và cách AI có thể trợ giúp.
Cách các AI Coding Tool hoạt động (Góc nhìn hoạt họa)
Tính đến thời điểm viết bài này, các AI programming assistant như Claude Code đang làm mưa làm gió trong thế giới software-development. Chúng được xây dựng dựa trên các LLM tổng quát được train trên nhiều ví dụ tìm thấy trực tuyến. Hãy suy nghĩ về ý nghĩa của quá trình đó như một workflow để tạo ra các coding insight và áp dụng chúng vào các bài toán programming cụ thể.
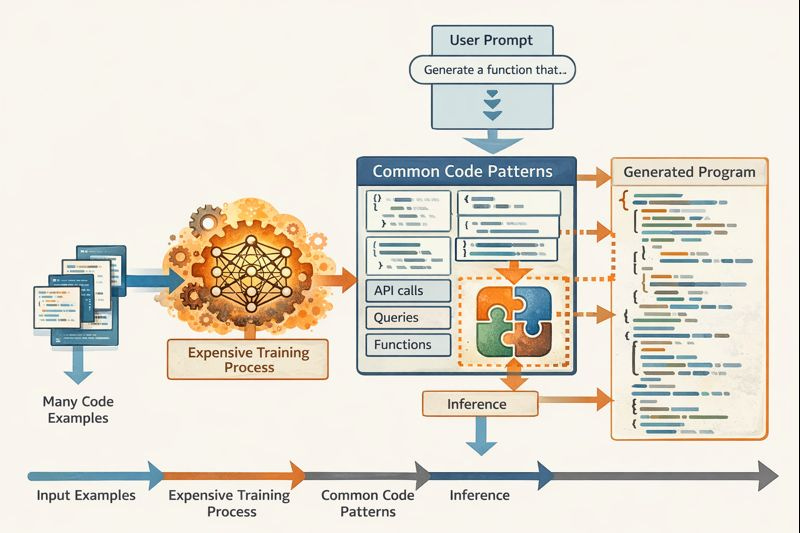
Mọi thứ bắt đầu từ một tập hợp lớn các file code ví dụ, có thể lấy được bằng cách crawling web. Chúng được đưa vào một quá trình training tốn kém. Một bài viết tóm tắt mô tả một bức tranh rõ ràng về chi phí từ hàng chục triệu đô la trở lên cho mỗi lần training một model tiên tiến – và ví dụ về DeepSeek được đưa ra với chi phí thấp chỉ 5,6 triệu đô la đến mức một số nhà phân tích đang tranh cãi về tính xác thực của nó! Tuy nhiên, hãy giả định rằng nỗ lực này là xứng đáng cho tất cả những lợi ích mà nó mang lại. Có lẽ đến giờ, chỉ riêng các ứng dụng trong programming cũng đủ để bù đắp chi phí.
Điều quan trọng cần lưu ý là các LLM, và deep neural networks nói chung, có xu hướng khó hiểu đối với các quan sát viên con người. Nghiên cứu vẫn tiếp tục trong lĩnh vực interpretability, nhưng nhìn chung chúng ta có rất ít hiểu biết về lý do tại sao một neural network có thể hoàn thành một số tác vụ nhất định hoặc nó được tổ chức như thế nào to hỗ trợ chúng. Chúng ta có thể giả định rằng các frontier model chứa đựng bên trong chúng một số representation của nhiều coding pattern hữu ích, mỗi cái được tổng quát hóa từ nhiều ví dụ.
Bây giờ hãy xem xét điều gì xảy ra khi một programmer đưa ra một yêu cầu functionality cụ thể bằng tiếng Anh. Yêu cầu đó có thể được đưa vào LLM như một prompt, và LLM có thể xác định coding pattern nào là phù hợp nhất cho functionality đó. Bây giờ, đây là nơi chúng ta chạm đến phần mà tôi muốn lập luận là có vấn đề sâu sắc: sau đó LLM sẽ khâu các code fragment đại diện cho các pattern khác nhau lại với nhau. Chúng kết thúc bằng cách kết hợp thành một mớ hỗn độn không hề dễ đọc ngay cả đối với các expert programmer. Có lẽ có một số structure, ít nhất là ngầm định, bên trong LLM để nắm bắt vocabulary của các coding pattern cần được áp dụng, but structure này sẽ bị mất trong quá trình generation các program cụ thể.
Tuy nhiên, thật đáng chú ý khi các tool này đã đạt được nhiều thành tựu đến thế. Tôi đã đưa cho Claude Sonnet 4.5 prompt sau.
Tạo một web app để hỗ trợ một đội ngũ tinh nhuệ phản ứng với các báo cáo về LLM hoạt động ngoài tầm kiểm soát. Công chúng có thể gửi các báo cáo về sự cố LLM, và sau đó các thành viên của đội ngũ có thể triage các sự cố này, quyết định phản ứng với sự cố nào. Sẽ rất tốt nếu có một dashboard tóm tắt các xu hướng trong báo cáo. Vì chúng ta chỉ đang làm prototype, nên việc sử dụng dummy authentication là OK, mặc dù sau này chúng ta sẽ muốn kết nối vào hệ thống SSO system của công ty.
Sau khi tôi làm rõ rằng tôi muốn sử dụng một SQL database, nó đã hoàn thành nhiệm vụ. Tôi chưa chạy thử nghiệm kỹ lưỡng phần code kết quả, nhưng có khoảng 1200 dòng code được chia ra 12 file, chiếm khoảng 75 kilobyte. Claude cần khoảng một phút để code tất cả, điều này tương phản cực kỳ thuận lợi so với những ngày tồi tệ của programming trước khi chúng ta có AI. Tuy nhiên, 75 kilobyte code là rất nhiều để tiếp thu (các dự án gieo mầm bằng AI như vậy thường bắt đầu với các bug, bao gồm cả các security vulnerability, đòi hỏi sự chú ý của chuyên gia để tìm ra), và nó mới chỉ dành cho functionality tương đối đơn giản mà khó có thể coi là cutting-edge. Không chỉ code này lặp lại nhiều ví dụ trực tuyến đã truyền cảm hứng cho nó, mà còn có rất nhiều sự lặp lại của các pattern boilerplate chỉ trong chính codebase nhỏ này.
Cơ hội từ Structure
Có những lý do chính đáng khiến các AI coding tool bắt đầu hoạt động theo cách tôi vừa phác thảo. Các hệ thống deep-learning phụ thuộc vào lượng lớn training data, điều đó có nghĩa là chúng hiệu quả nhất trên các programming language được sử dụng rộng rãi, bất kể ưu điểm hay nhược điểm vốn có của chúng. Cũng có những áp lực signaling đáng kể hướng tới các thách thức programming phức tạp. Những người tạo ra LLM luôn tìm kiếm các benchmark để chứng minh các model của họ có khả năng thế nào, điều đó có nghĩa là, đối với họ, độ khó của programming là một feature, không phải là một bug. Bản thân các programmer đánh giá cao sự đảm bảo công việc đến từ khả năng xử lý các tác vụ khó khăn.
Tuy nhiên, chúng ta có thể lùi lại một bước và cố gắng đơn giản hóa. Điều gì sẽ xảy ra nếu workflow của AI code generation trông giống như sau, nơi chúng ta thực sự để LLM có ít việc phải làm hơn?
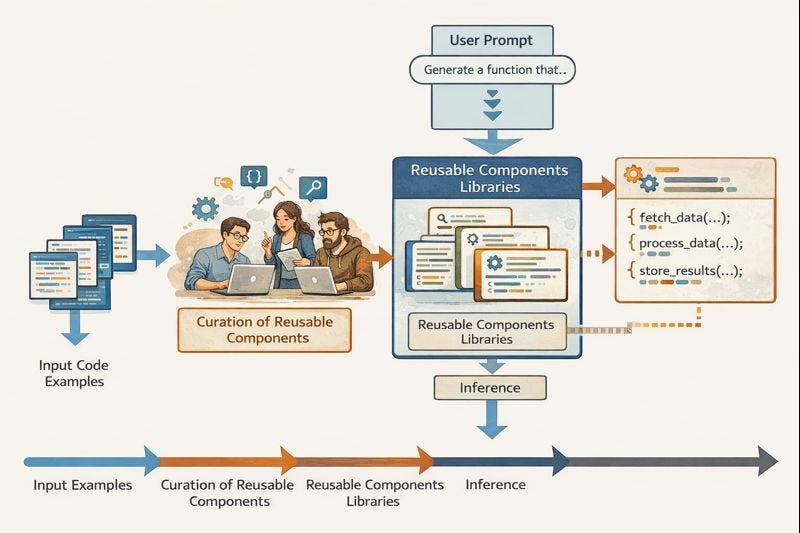
Theo một nghĩa nào đó, chúng ta vẫn đang bắt đầu với nhiều ví dụ code, nhưng bây giờ chúng có ý nghĩa trong việc ảnh hưởng đến các programmer có gu thẩm mỹ tốt, những người tự tay curate một library gồm các coding pattern có giá trị. Các programmer này vẫn có thể đang sử dụng AI để tăng tốc công việc của họ, nhưng điều quan trọng là mỗi pattern phải được thể hiện trong một first-class reusable software component. Các programmer đã được yêu cầu ít nhất là phải đồng ý trên danh nghĩa với việc tái sử dụng software dựa trên component trong nhiều thập kỷ, mặc dù mức độ cam kết và thành công rất khác nhau giữa các dự án. Hãy giả định rằng chúng ta tìm thấy một đội ngũ tốt có khả năng curate một library gồm các component đại diện cho các tính năng phổ biến.
Bây giờ chúng ta có thể prompt một LLM với cùng các yêu cầu functionality như trong kịch bản trước, nhưng nó hoạt động khá khác biệt. Nó vẫn cần tìm các component phù hợp nhất cho tác vụ, điều này có thể hoạt động tương tự như cách tiếp cận chính thống. Tuy nhiên, thay vì đưa vào software program của chúng ta một đống code cho mỗi component và trộn tất cả chúng lại với nhau thành một mớ hỗn độn nơi các component có thể trở nên không thể nhận diện được, program được tạo ra chỉ cần tham chiếu đến các component bằng name. Kết quả là, nó có thể ngắn hơn và đơn giản hơn nhiều.
Hãy để tôi cụ thể hơn một chút bằng cách sử dụng ví dụ về một hệ thống mà tôi đã làm việc cùng, Nectry, một tool để tạo enterprise software với giao diện chatbot. Tôi đã đưa cho Nectry cùng prompt như trên, và nó tạo ra dưới 250 dòng code hoặc khoảng 7,5 kilobyte – nghĩa là tiết kiệm khoảng 5 lần về số dòng code và 10 lần về tổng dung lượng code. Bí quyết là mọi thứ đều được thể hiện trong ngôn ngữ declarative, domain-specific language mới của chúng tôi là NectryCore, vốn bỏ qua hầu hết các tính năng phức tạp của programming, chỉ cho phép mô tả cách cấu hình các component và cắm chúng lại với nhau.
Các component trong Nectry cũng đặc biệt high-level. Ví dụ, ví dụ ở đây sử dụng một component có tên là “Approval Flow Table,” đại diện cho ý tưởng hiển thị cho user một bảng các yêu cầu với các nút để nhấp vào nhằm phê duyệt hoặc từ chối chúng. Bây giờ, không có phần code nào giải thích một tính năng như vậy từ các nguyên lý cơ bản cần phải được đưa vào program. Thay vào đó, program chỉ cần đề cập đến “Approval Flow Table” và giải thích cách specialize nó cho một kịch bản cụ thể.
Cơ hội cho các Guarantee
Hãy tưởng tượng rằng, bằng cách này hay cách khác, một AI assistant đã tạo ra một program cho chúng ta. Chúng ta có thể bắt nó trải qua quá trình testing, nhưng chỉ testing thôi là không đủ để biết rằng code sẽ không hoạt động sai trong một kịch bản mà chúng ta không lường trước được. Chi phí của hành vi sai trái có thể cao đến mức gần như vô hạn. Đây là một ví dụ: chúng ta đang xây dựng software để hỗ trợ một bệnh viện, và nó xử lý cả hồ sơ y tế nhạy cảm của bệnh nhân lẫn các email gửi hàng loạt hàng nguyên để gây quỹ từ thiện. Sẽ thật đáng tiếc nếu bệnh án của ai đó bị lọt vào email gây quỹ. Đó sẽ là loại tin đáng tiếc xuất hiện trên trang nhất của tờ báo địa phương. Như một thuộc tính đơn giản hơn, chúng ta cũng hãy nghĩ về ý định của mình rằng phần software này không thể tắt hệ thống điện của bệnh viện.
Rắc rối là việc kiểm tra xem software có tuân thủ các formal requirement hay không là cực kỳ khó khăn. Trường hợp tốt nhất sẽ là một software program khác kiểm tra program do AI tạo ra. Thật không may, các kết quả nổi tiếng của khoa học máy tính cho chúng ta biết điều đó là không thể (với một lưu ý quan trọng sẽ sớm được trình bày). Có nhiều programming language, nhưng hóa ra hầu hết tất cả các ngôn ngữ được sử dụng rộng rãi đều tương đương theo nghĩa là Turing-complete: bất kỳ program nào được viết bằng một trong số chúng đều có thể được dịch thành một program tương đương về mặt chức năng trong bất kỳ ngôn ngữ nào khác. Sự tương đương này nghe có vẻ như một sự giải thoát: trong khi các programmer được biết đến là hay tham gia vào các cuộc tranh luận nảy lửa về programming language 'tốt nhất', sự lựa chọn dường như không quan trọng đối với những gì có thể đạt được.
Tuy nhiên, có một điểm vướng mắc. Turing completeness không đơn thuần là một câu lạc bộ đáng mơ ước mà một ngôn ngữ cần gia nhập. Theo nghĩa hình thức, việc tự động trả lời các câu hỏi về hành vi của program trong các ngôn ngữ này là không thể. Alan Turing đã chứng minh rằng không có program nào có thể nhận đầu vào là các program tùy ý trong một ngôn ngữ Turing-complete và cho chúng ta biết một cách đáng tin cậy liệu chúng kết thúc hay chạy mãi mãi. Bài toán đó chính thức là undecidable. Trên thực tế, bắt đầu từ tính undecidability của bài toán dừng halting problem, chúng ta có thể suy ra rằng hầu hết các câu hỏi thú vị khác về hành vi của program cũng là undecidable.
Hãy lấy ví dụ về bệnh viện của chúng ta, trong trường hợp đơn giản hơn khi chúng ta muốn biết liệu một program có thể tắt điện của tòa nhà hay không. Giả định rằng chúng ta có một cách tiếp cận hệ thống để trả lời câu hỏi đó, đối với các phiên bản program tùy ý được viết bằng một ngôn ngữ Turing-complete nào đó.

Hóa ra chúng ta đang gặp rắc rối lớn. Một solver cho halting problem có thể được xây dựng từ solver cho bài toán có-thể-tắt-điện của chúng ta. Sự formal reduction không quan trọng đối với lập luận hiện tại. Những gì chúng ta cần nhớ là việc tự động trả lời các câu hỏi về hành vi tiềm ẩn của các program trong các ngôn ngữ Turing-complete là cực kỳ khó, thậm chí không thể theo một nghĩa hình thức nhất định. Và khi AI cung cấp một program theo đặc tả của chúng ta, việc có thể kiểm tra xem kết quả có đáp ứng các yêu cầu hay không sẽ cực kỳ có giá trị.
Một giải pháp, đang được tích cực khám phá bởi một số đội ngũ ngày nay, là yêu cầu AI viết không chỉ một program mà còn cả một mathematical proof về tính chính xác của nó. Sau đó, một thuật toán đáng tin cậy có thể validate chứng minh đó mà không cần giả định bất kỳ năng lực nào của AI. Tôi đã dành phần lớn sự nghiệp của mình để phát triển các tool tốt cho con người viết các loại chứng minh chặt chẽ này. Tuy nhiên, thực sự không có bữa trưa nào miễn phí khi nói đến tính undecidability của các thuộc tính thú vị của program trong các ngôn ngữ Turing-complete (chính thức là định lý Rice’s theorem). Kết quả của chứng minh tính chính xác của program là nó là một bài toán khó đầy sắc thái. Độ khó này tạo ra một mục tiêu hấp dẫn khác cho việc benchmarking các LLM, nhưng độ khó như vậy không tốt cho việc giúp chúng ta tạo ra các program thực tế mà chúng ta muốn. (Chúng ta vẫn sẽ quay lại trong các bài viết sau để thảo luận cách scale cách tiếp cận này; nó chỉ không phải là quả ngọt dễ hái.)
Chúng ta có thể né tránh những khó khăn này không? Luôn hữu ích khi kiểm tra các giả định dẫn đến một kết luận không mong muốn, trong trường hợp một giả định thực sự có thể tránh được. Ở đây, cơ hội của chúng ta là tránh các ngôn ngữ Turing-complete. Tôi đã đưa ra ví dụ ở trên về ngôn ngữ NectryCore, vốn tránh được hầu hết các tính năng phức tạp của programming, chuyển sang xây dựng các program từ các component có tính tái sử dụng high-level. Hóa ra là một loạt câu hỏi về hành vi của program trở nên decidable.
Ví dụ, ở trên tôi đã đưa ra một ví dụ về việc không muốn bất kỳ thông tin nào từ hồ sơ y tế bảo mật lọt vào các email gây quỹ. Bài toán này có thể được tổng quát hóa thành các information-flow properties, hạn chế ảnh hưởng của các thông tin đầu vào. Các bài toán như vậy hóa ra lại rất đơn giản để kiểm tra trên các program được thể hiện theo đúng cách high-level. Đại khái, lý do bài toán này khó đối với các ngôn ngữ Turing-complete là vì chúng bao gồm các tính năng như các loop và recursive function cho phép thực thi độ dài tùy ý, khiến việc khám phá tất cả các đường thực thi khả thi trở nên khó khăn – nhìn chung là có vô số! Các program NectryCore có thể được kiểm tra chéo với các thuộc tính luồng thông tin bằng cách liệt kê tất cả các đường dẫn giữa các component, vốn ẩn giấu trong phần implementation (do chuyên gia viết) của chúng tất cả công việc với loop và recursion cần thiết để mang lại các functionality high-level của chúng.
Bài học rút ra
Programming là một ví dụ tuyệt vời về một lĩnh vực nhân tạo cao. Chúng ta đã tạo ra tất cả các structure của nó và phát minh ra tất cả các rule của nó. Chúng ta nên tàn nhẫn thay đổi chúng để hạ thấp chi phí của software development. Tôi thừa nhận, các kỹ thuật tôi nhấn mạnh cũng là những kỹ thuật được ưa chuộng trong cộng đồng nghiên cứu của tôi, ngay cả trước khi các AI code assistant mang tính thực tiễn. Các program do con người viết vốn dĩ đã có nguy cơ quá khó hiểu và có quá nhiều bug. Tuy nhiên, trường hợp này thậm chí còn rõ ràng hơn bây giờ, khi code được viết bởi các hệ thống AI mờ đục vốn không thể chịu trách nhiệm cho các sai sót.
Trong cả hai trường hợp, chúng ta có thể lo lắng về các thực thể độc hại đang hoạt động tích cực, cho dù là các programmer con người hay các AI assistant, cố gắng hết sức để ẩn giấu các defect trong phần code họ viết cho chúng ta. Tôi sẽ có nhiều điều để nói hơn về các thách thức cybersecurity đó trong các bài viết sau, nhưng hiện tại, nguyên tắc cần lưu ý là chúng ta nợ chính mình việc đơn giản hóa structure của programming, một phần là để thiết lập các guarantee toán học.
Bài viết này kết thúc một chuỗi bốn bài, trình bày các thách thức khác nhau thường được đặt ra cho AI, phân tích các lý do khác nhau tại sao chúng ta có lẽ không muốn giải quyết chính xác các bài toán đó. Rốt cuộc, chúng ta có thể không cần xây dựng các AI conscious; việc né tránh cả hai thách thức về driving on today’s roads và sự phức tạp của natural language có thể là xứng đáng và khả thi; và bây giờ chúng ta bắt đầu suy nghĩ về cách thay đổi programming để đơn giản hóa công việc của các AI coding assistant. Trong chuỗi bốn bài viết sắp tới, tôi sẽ lùi lại và thảo luận tổng quát hơn về các quá trình tiến hóa đã tạo ra trí thông minh tự nhiên và một số tool từ khoa học máy tính vốn sẽ giúp chúng ta tăng tốc đáng kể việc khám phá các không gian thiết kế – với các guarantee toán học.
In regards to the cybersecurity challenges you've hinted at, I've learned that poetry and inaudible voice commands are starting to be used for injection attacks in AI systems. Poetry is highly contextual and can be used to essentially inject malicious prompts into an AI agent, while malicious voice commands can be sent over human-inaudible frequencies to inject malicious commands into voice recognizing AI agents. I'm not sure if there's a solution to such injection attacks, but they certainly present a cybersecurity challenge. ( https://medium.com/@albeeandrew/silent-sphinx-leveraging-adversarial-poetry-with-near-ultrasound-inaudible-trojan-nuit-attack-7c99980bfe53 )
I like how you're able to simplify how generative AI agents work, and it hadn't crossed my mind that these coding agents are also subject to the same mathematical proofs (and Turing completeness) as any other normal piece of software.
When ChatGPT started creating a buzz, I heard a lot of talk about how "programmers would be replaceable" given that it (and other AI agents) could just generate code. I'm glad to learn that not only will there always be a need for skilled programmers to 'check the work of an AI' (for lack of better phrasing), but there will also need to be proper computer scientists that can actually work on the 'theoretical aspect' of generative AI.
Despite the guarantee (heh) that computer scientists will always have a career, I can't help but think that the way computer science is taught may now become a bit challenging, and might have to change as a result. I'm sure it's simple enough to detect plagiarism amongst students, but now we'd have to detect plagiarism against a (or several) coding agents as well. Have there been any changes in computer science pedagogy that you've noticed since AI agents became easily accessible to students?