
Tại sao "Deep" thường có nghĩa là "Slow"
Sự cộng dồn cấp số nhân của latency với generative AI

Hãy để tôi tiếp tục mô tả các ưu và nhược điểm của deep learning, nhằm giúp quyết định cách phân chia công việc của trí tuệ tương lai với các yếu tố khác như formal verification. Bài viết trước của tôi đã trình bày deep learning như một công cụ tìm kiếm tối thượng, dùng để tìm kiếm các tài liệu liên quan trước đó (prior art) đối với các mục tiêu mới, xem xét các tập dữ liệu khổng lồ có thể chứa các ý tưởng liên quan vì những lý do không rõ ràng. Bây giờ tôi sẽ dành hai bài viết để nói về các điểm yếu của deep learning, bắt đầu với lượng thời gian cần thiết để nhận được câu trả lời, đặc biệt là với loại LLM-based tool điển hình đang được xây dựng ngày nay.
Thông điệp cốt lõi của chúng ta sẽ là các hệ thống dựa trên deep learning tạo ra sequentiality (các bước tính toán nhất định phải xảy ra sau các bước khác) thường không vốn có trong các câu hỏi mà chúng ta yêu cầu chúng trả lời. Thay vào đó, nó phát sinh từ cách chúng ta chọn tổ chức tính toán để trả lời chúng. Kết quả là sự chậm trễ cơ bản trong việc nhận lại các câu trả lời đó.
Latency và Throughput trong các Parallel Systems
Chúng ta cần suy nghĩ một cách tổng quát về hiệu năng của các hệ thống máy tính. Hãy để tôi giải thích những điều cơ bản bằng cách sử dụng một ví dụ về các khóa học và các điều kiện tiên quyết của chúng.
Hãy tưởng tượng rằng mỗi sinh viên trong một khoa nhất định cần phải học mọi khóa học được hiển thị dưới dạng hình chữ nhật trong sơ đồ này. Một mũi tên từ hộp này sang hộp khác biểu thị điều kiện tiên quyết: khóa học ở gốc mũi tên phải được học trước khóa học ở ngọn mũi tên. Một longest path trong sơ đồ này được highlight dọc theo phía trên, với các khóa học không bị làm mờ.
Ngay cả khi chỉ xét từ góc nhìn của một sinh viên, quá trình hoàn thành các yêu cầu khóa học là parallel: nhiều hoạt động có thể diễn ra cùng một lúc, ở đây là học nhiều khóa học. Theo thuật ngữ từ running-time analysis of parallel algorithms, chúng ta sẽ gọi con đường dài nhất trong sơ đồ như vậy là critical path. Chúng ta sử dụng depth để chỉ độ dài critical path của một parallel workload, và chúng ta sử dụng work để chỉ tổng số bước (các khóa học trong ví dụ này), trong một phân loại được giới thiệu bởi Blelloch và các cộng sự vài thập kỷ trước
Một định lý quan trọng trong lĩnh vực này là một parallel workload cho trước phải chạy trong một số bước ít nhất bằng depth của nó. Kết luận này trực quan sau khi hiểu rõ thuật ngữ: một chuỗi điều kiện tiên quyết dài trong các yêu cầu cấp bằng thực sự ngụ ý số học kỳ tối thiểu để hoàn thành bằng cấp.
Nói chung, chúng ta chạy nhiều phiên bản (instances) của một parallel workload cùng một lúc. Đối với ví dụ về các khóa học của chúng ta, hiện tượng này tương ứng với việc có nhiều sinh viên đăng ký học cùng lúc. Thời gian từ khi bắt đầu một lần thực thi workload đến khi hoàn thành hoàn toàn được gọi là latency. Số lượng instances của workload hoàn thành trên mỗi bước được gọi là throughput. Ví dụ của chúng ta kết nối latency với khoảng thời gian để một sinh viên tốt nghiệp và throughput với số lượng sinh viên tốt nghiệp mỗi kỳ học.
Rõ ràng cả latency và throughput đều quan trọng trong ví dụ đang chạy, nhưng latency quan trọng hơn từ góc nhìn của sinh viên. Không có gì an ủi khi biết rằng hàng ngàn sinh viên tốt nghiệp mỗi kỳ nếu bản thân phải mất 100 kỳ mới tốt nghiệp.
Critical Paths của Deep Neural Networks
Hầu hết mọi người khi gặp thuật ngữ “deep learning” đều tự nhiên cho rằng “deep” chỉ là tin tốt: neural network đang làm điều gì đó khó khăn và phức tạp. Thuật ngữ này đề cập cụ thể hơn đến việc một neural network có bao nhiêu layers. Sơ đồ này cho thấy đại khái cấu trúc của một deep neural network, với các layers được sắp xếp theo chiều ngang, mỗi layer bao gồm nhiều artificial neurons, trải rộng theo chiều dọc.
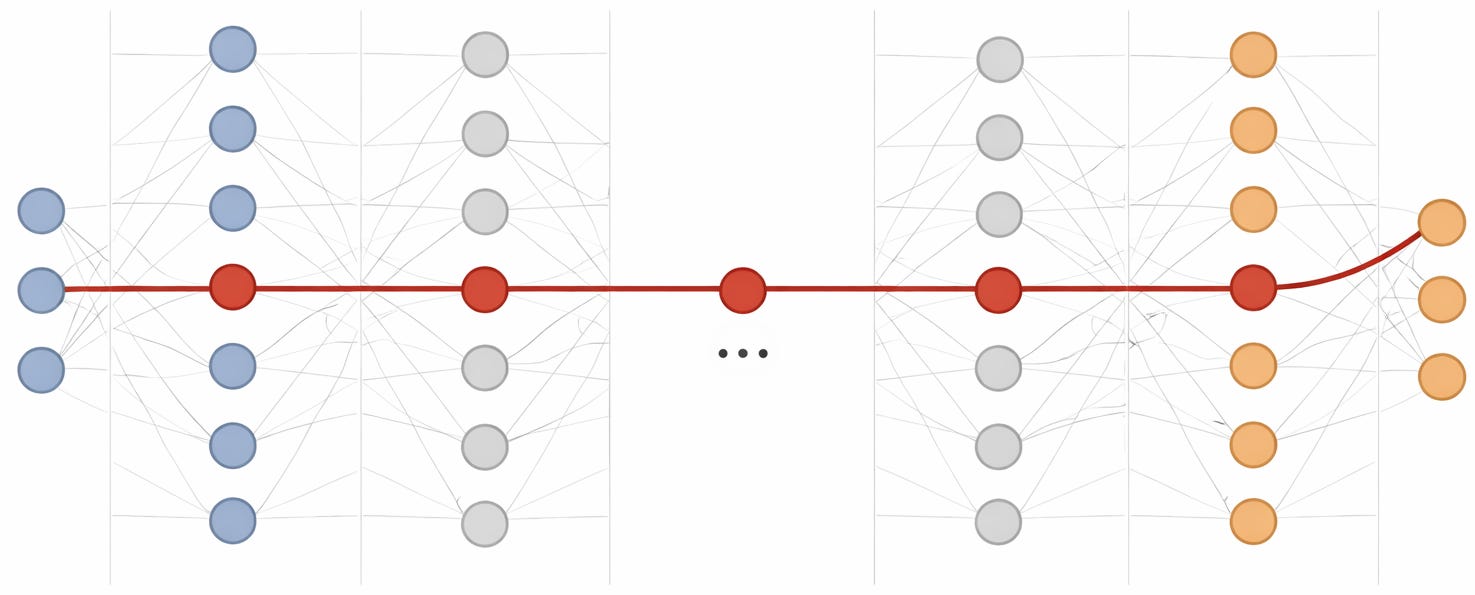
Mỗi neuron có các đầu vào đến từ (nói chung) nhiều neuron khác từ layer trước. Mỗi neuron giống như một khóa học trong ví dụ trước của chúng ta: một đơn vị công việc cần được thực hiện cuối cùng, để tạo ra câu trả lời hoàn chỉnh cho một câu hỏi, với các ràng buộc phụ thuộc vào một số bước trước đó (ở đây là từ layer trước). Lưu ý rằng, như đường dẫn được highlight cho thấy, critical path hiện chạy qua tất cả các layers, vì vậy depth và do đó latency tỷ lệ thuận với layer count. Vì “deep” dùng để chỉ số lượng layers, nên ở đây chúng ta có minh họa về việc “deep” có thể có nghĩa là “slow” như thế nào. Có nhiều cách để một deep neural network có thể được đánh giá như một parallel workload, nhưng nếu không có một số sự sắp xếp lại tính toán ở cấp độ cao hơn, việc tạo ra câu trả lời sẽ mất thời gian ít nhất là tỷ lệ thuận với layer count.
Tất nhiên, vẫn có đủ loại thủ thuật để tăng throughput. Rõ ràng nhất là chúng ta mong đợi rằng hầu hết tất cả các neuron trong một layer đơn lẻ có thể được đánh giá cùng một lúc. Kỹ thuật hệ thống máy tính tiêu chuẩn là pipelining cũng được sử dụng, giống như chúng ta mong đợi từ ví dụ trước về các khóa học: nhiều lần thực thi neural network có thể chạy đồng thời, trong đó tại bất kỳ thời điểm nào, mỗi layer đều đang làm việc trên một yêu cầu người dùng khác nhau. Tuy nhiên, các tối ưu hóa này chỉ thúc đẩy throughput và trên thực tế có thể tạo ra sự phối hợp bổ sung giữa các bước mà thậm chí còn làm tăng latency (ví dụ: pipelining chia nhỏ một phép tính thành các phần gây thêm overhead truyền thông với nhau qua các hàng đợi - queues). Trong khi các công ty AI có động lực kiểm soát chi phí bằng cách cải thiện throughput, thì trải nghiệm của một người dùng cuối cá nhân phụ thuộc nhiều hơn vào latency, ngay cả khi có các tối ưu hóa như batching (thực thi đồng thời các yêu cầu từ các người dùng khác nhau). Người dùng đó có thể trả phí thấp hơn nhờ chia sẻ tài nguyên giúp cải thiện throughput, nhưng khó có thể không nhận thấy rằng, ví dụ, một chatbot mất nhiều thời gian để hoàn thành việc trả lại câu trả lời chấp nhận được, và latency có thể còn quan trọng hơn đối với các ca sử dụng mới nổi.
Cũng có thể lập luận rằng sơ đồ trên bị đơn giản hóa quá mức. Các neural networks tiên tiến không thực sự cấp dữ liệu cho các neuron chỉ bằng đầu ra từ các layers ngay trước đó. Một kỹ thuật đặc biệt phổ biến là KV caching, kỹ thuật này cung cấp cho mỗi neuron một bản tóm tắt tương đối phức tạp về các bước trong quá khứ. Tuy nhiên, các biến thể này không làm thay đổi thực tế về các mối phụ thuộc tuần tự dài (critical paths), với độ dài tỷ lệ thuận với layer counts. Hai kỹ thuật phổ biến khác đáng nhắc đến là attention, kỹ thuật này thao tác các phụ thuộc trong các layers nhưng về cơ bản vẫn duy trì cấu trúc critical-path qua các layers; và residual connections, kỹ thuật này cho phép một số kết nối giữa các layers không kề nhau nhưng cũng duy trì loại kết nối bình thường, tạo ra các critical paths tương tự.
Tóm lại, do cách deep learning được tổ chức với các critical paths dài, việc một số bước cần phải xảy ra sau các bước khác là không thể tránh khỏi, và trên thực tế, các chuỗi phụ thuộc dài như vậy sẽ hình thành, buộc phải có sự chậm trễ trước khi câu trả lời cuối cùng có thể được đưa ra.
Deep trên toàn bộ hệ thống, nhân số Latency
Bây giờ hãy xem xét các yếu tố khác trong các hệ thống agentic đang được xây dựng trên nền tảng LLMs ngày nay.
Đầu tiên, một LLM tạo ra câu trả lời đầy đủ bằng cách gọi một neural network nhiều lần, mỗi lần để tạo ra một token (đại khái là một từ đơn lẻ). Đầu vào của neural network là biểu diễn của các tokens đã được tạo ra trước đó, điều này dẫn đến một critical path dài di chuyển tuần tự qua tất cả các lệnh gọi neural network. Nói cách khác, khi neural network có depth d và chúng ta đang tạo phản hồi LLM gồm t tokens, critical path ở mức độ chi tiết hệ thống này có độ dài tỷ lệ thuận với dt.
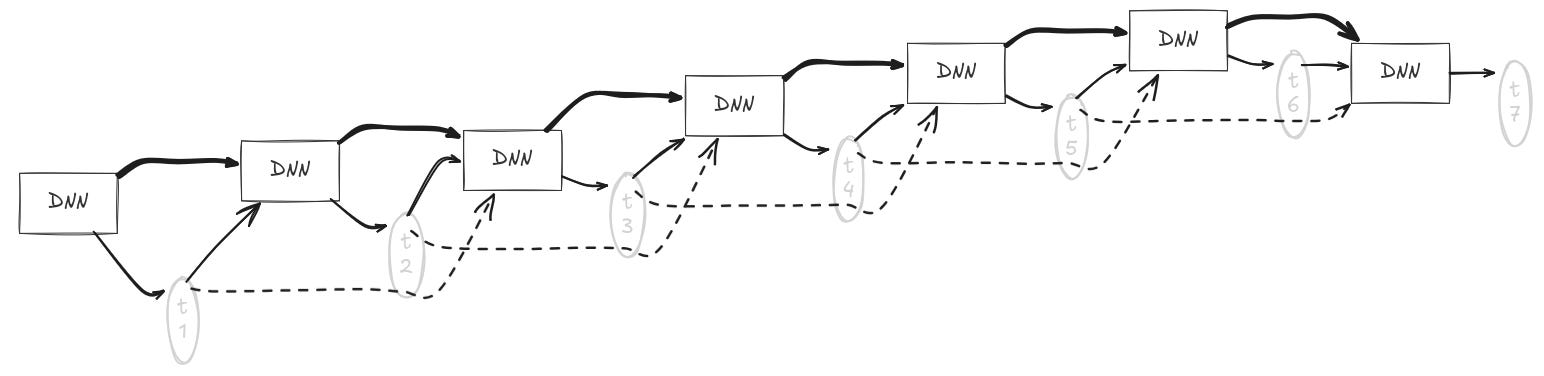
Làm thế nào để chúng ta có được depth khoảng dt? Ở mức độ chi tiết trong sơ đồ cuối cùng này, chúng ta dễ dàng vạch ra một critical path có độ dài t, bắt đầu bằng lệnh gọi neural-network đầu tiên, có đầu ra chảy vào lệnh gọi tiếp theo, v.v. cho đến lệnh gọi neural-network cuối cùng. Tuy nhiên, mỗi hộp được gắn nhãn “DNN” (đại diện cho deep neural network) là một bản sao của sơ đồ trước đó, nơi chúng ta đã vạch ra critical path có độ dài d. Đưa các bản sao đó vào, các phân đoạn đường dẫn kết nối với nhau để đạt được độ dài tỷ lệ thuận với dt. Trực quan là hệ thống thực hiện tuần tự t truy vấn tới DNN, và đối với mỗi truy vấn, chúng ta phải tạm dừng và chờ d bước tuần tự của DNN.
Một vài kỹ thuật cho phép sai lệch so với loại sơ đồ workload này. Ví dụ, speculative decoding sử dụng các neural networks rẻ hơn để đoán các lô câu trả lời, sau đó chúng được kiểm tra trong một lượt duy nhất bằng các neural networks đắt tiền hơn. Tuy nhiên, kỹ thuật này chỉ cải thiện latency một hệ số hằng số nhỏ – không đủ để bù đắp cho sự cộng dồn cấp số nhân của latency. Kết quả là, latency vẫn tỷ lệ thuận với depth của neural network và độ dài đầu ra của LLM.
Bây giờ hãy xem xét cách hoạt động của một coding assistant như Claude Code. Nó có thể đảm nhận nhiều tác vụ song song, nhưng một số mục tiêu vẫn phụ thuộc vào các chuỗi bước tương đối dài – trong đó nhiều bước riêng lẻ là bản sao của toàn bộ luồng LLM mà chúng ta vừa đề cập. Ngoài ra, một số bước thực hiện các tool calls tùy ý đến các chương trình bên ngoài, vốn tự tạo ra latency của riêng chúng. Sơ đồ này cho thấy coding agent gọi một compiler để nhận phản hồi về các vấn đề tương đối nông mà nó tìm thấy trong mã nguồn, cũng như gọi một test runner để xem đầu vào nào từ một test suite mà chương trình không tạo ra câu trả lời đúng.

Đến bây giờ, bạn có thể đã quen với việc phát hiện ra vấn đề đối với latency: mỗi nút LLM trong sơ đồ này có độ dài critical path tỷ lệ thuận với dt. Bây giờ hãy xem xét chuỗi các bước cấp cao dài nhất trong sơ đồ mới, có độ dài s. Chúng ta đạt tới depth ít nhất là dts, trước cả khi tính đến latency của các tool calls. Thời gian cần thiết để có được câu trả lời hoàn chỉnh cho một câu hỏi cấp cao nhất đang bị nhân thêm một hệ số cho mỗi cấp độ phức tạp bổ sung mà chúng ta đưa vào. Lý do lại là vì mỗi hộp LLM mở rộng thành một bản sao đầy đủ của sơ đồ trước đó, và các phân đoạn đường dẫn hiển thị trực tiếp trong hình này kết nối với s bản sao của critical path có độ dài khoảng dt từ trước. Latency đã được cộng dồn qua tất cả các layers của hệ thống, từ neural network đến dự đoán next-token lặp đi lặp lại cho đến agentic workflow cấp cao hơn. Việc thêm chức năng không cộng thêm vào latency mà thay vào đó là nhân nó lên.
Kết luận
Cách mà các hệ thống generative-AI chính thống đang được thiết kế ngày nay thể hiện một hiện tượng cơ bản là sự cộng dồn cấp số nhân của latency, với cường độ tỷ lệ thuận với số lượng cấp độ chức năng bổ sung được thêm vào. Latency không phải là tất cả, nhưng nhận được câu trả lời đầy đủ cho các câu hỏi sớm hơn rõ ràng là tốt hơn. Ví dụ, lập trình viên sử dụng một AI coding assistant thường phải chờ đợi toàn bộ latency trước khi thực hiện code review và chạy thử nghiệm (testing) để hoàn thành một đóng góp mã nguồn (code contribution).
Lời phản biện tốt nhất đối với những quan sát này về các hệ thống generative-AI hiện tại là chúng ta dường như chưa nghĩ ra những cách khác để giải quyết cùng một vấn đề với chất lượng giải pháp gần như tương đương. Có lẽ hình phạt latency là không thể tránh khỏi đối với những vấn đề đó. Hai bài viết sau bài viết này, tôi sẽ trình bày một khung làm việc giải quyết phản hồi đó từ một góc nhìn bất thường. Phóng tầm mắt ra xa hơn những gì bài viết này đề cập, với các thay đổi kiến trúc khác, chúng ta có thể tránh được latency cao như vậy bằng cách rút ngắn các critical paths.
Tuy nhiên, trước tiên, trong bài viết tiếp theo, tôi muốn trình bày thách thức về tính explainability đối với machine learning, đối lập với một phong cách trí tuệ nhân tạo cũ hơn.