
Deep Learning: Công cụ tìm kiếm tối thượng
Giá trị của việc tìm kiếm tài liệu liên quan trước đó (prior art)

Loạt bài viết gần đây của tôi đã nêu bật các công cụ để xây dựng một tương lai đáng tin cậy của các AI agents, đặc biệt là formal verification và cryptography. Ý tưởng cuối cùng tôi muốn định vị chính xác là deep learning, đây chắc chắn là điều mà một độc giả trung bình sẽ nghĩ đến đầu tiên. Hầu hết những gì tôi sắp nói sẽ áp dụng cho machine learning rộng hơn, mặc dù khó có thể bỏ qua thành công vang dội gần đây của riêng deep learning.
Bài viết này sẽ phát triển một cách tư duy về các thế mạnh và khả năng của deep learning. Các bài viết tiếp theo sẽ nêu bật các điểm yếu, chuẩn bị cho chúng ta một kế hoạch tốt về cách các hệ thống đáng tin cậy có thể phân chia trách nhiệm giữa deep learning và các kỹ thuật khác.
Một góc nhìn đơn giản về Deep Learning
Có lẽ tất cả chúng ta đều đã học trong lớp toán trung học cơ sở về cách một đường thẳng có thể được mô tả bằng phương trình y = mx + b. Nếu ai đó đưa cho chúng ta một tập hợp các điểm trong không gian hai chiều, chúng ta có thể giải để tìm đường thẳng mà chúng khớp vào, nghĩa là tìm m và b. Ý tưởng này được tổng quát hóa cho các điểm trong bất kỳ không gian nhiều chiều nào và cho cả các đường cong ngoài đường thẳng.
Tuy nhiên, dữ liệu trong thế giới thực rất lộn xộn. Chúng ta có thể tưởng tượng bằng cách nào đó biến toàn bộ nội dung của mạng web công cộng thành một tập hợp khổng lồ các điểm nhiều chiều. Khi đó, chúng ta có thể nghĩ về các LLMs như việc ánh xạ các prompts x thành các câu trả lời y. Tuy nhiên, dữ liệu huấn luyện (training data) sẽ không khớp với bất kỳ đường cong sạch sẽ nào; chúng ta cần xem xét tính mập mờ khi chúng chỉ khớp gần đúng. May mắn thay, lĩnh vực machine learning đã tìm ra cách thực hiện loại phân tích dữ liệu quy mô lớn đó. Các LLMs hàng đầu sử dụng hàng trăm tỷ parameters trở lên. Chúng ta có thể nghĩ một cách đại khái rằng “parameters” trong câu đó mô tả các giá trị cần tìm, giống như m và b in ví dụ trung học của chúng ta.
Tuy nhiên, không có gì ngạc nhiên khi các phương pháp toán học trung học cơ sở không đủ khả năng đáp ứng thách thức này! Một phần là vì việc huấn luyện các mô hình (training models) thường sử dụng rất nhiều tài nguyên tính toán (compute), phụ thuộc nặng nề vào phần cứng GPU. Nhưng chúng ta nên cấu trúc việc tính toán như thế nào? Việc giải các hệ phương trình tuyến tính kiểu cũ mà Gauss đã tìm ra vào khoảng năm 1800 sẽ không hoàn thành được công việc. Thay vào đó, ý tưởng lớn là gradient descent.
Tôi sẽ không đi sâu vào chi tiết toán học của gradient descent, nhưng ý tưởng cơ bản là bắt đầu từ một dự đoán về các giá trị parameter tốt. Chúng xác định một hàm toán học. Đánh giá hàm này trên một tập hợp các đầu vào mẫu tốt, nơi bạn thực sự biết câu trả lời đúng cho từng đầu vào. Kiểm tra các chi tiết xem hàm hiện tại của bạn sai ở mức độ nào và theo những cách nào. Với một chút kiến thức về calculus, chúng ta có thể chuyển phân tích đó thành một kế hoạch sửa đổi các giá trị parameter để tiến gần hơn đến kết quả đúng. Chúng ta lặp lại quá trình này, cải thiện các parameters cho đến khi hài lòng với mức độ hoạt động tốt của hàm đó.
Sơ đồ sau đây minh họa gradient descent cho machine learning ở cấp độ cao. Bề mặt ba chiều đại diện cho một loss function biểu thị mức độ sai lệch của hàm chính của chúng ta. Chúng ta muốn đẩy loss càng gần mức 0 càng tốt. Giả sử cấu trúc của loss function tương đối mượt mà, chúng ta chỉ cần trượt xuống dốc từng bước một, luôn chọn độ dốc lớn nhất để khám phá tiếp theo. Mỗi bước di chuyển tương ứng với việc sửa đổi các parameters.
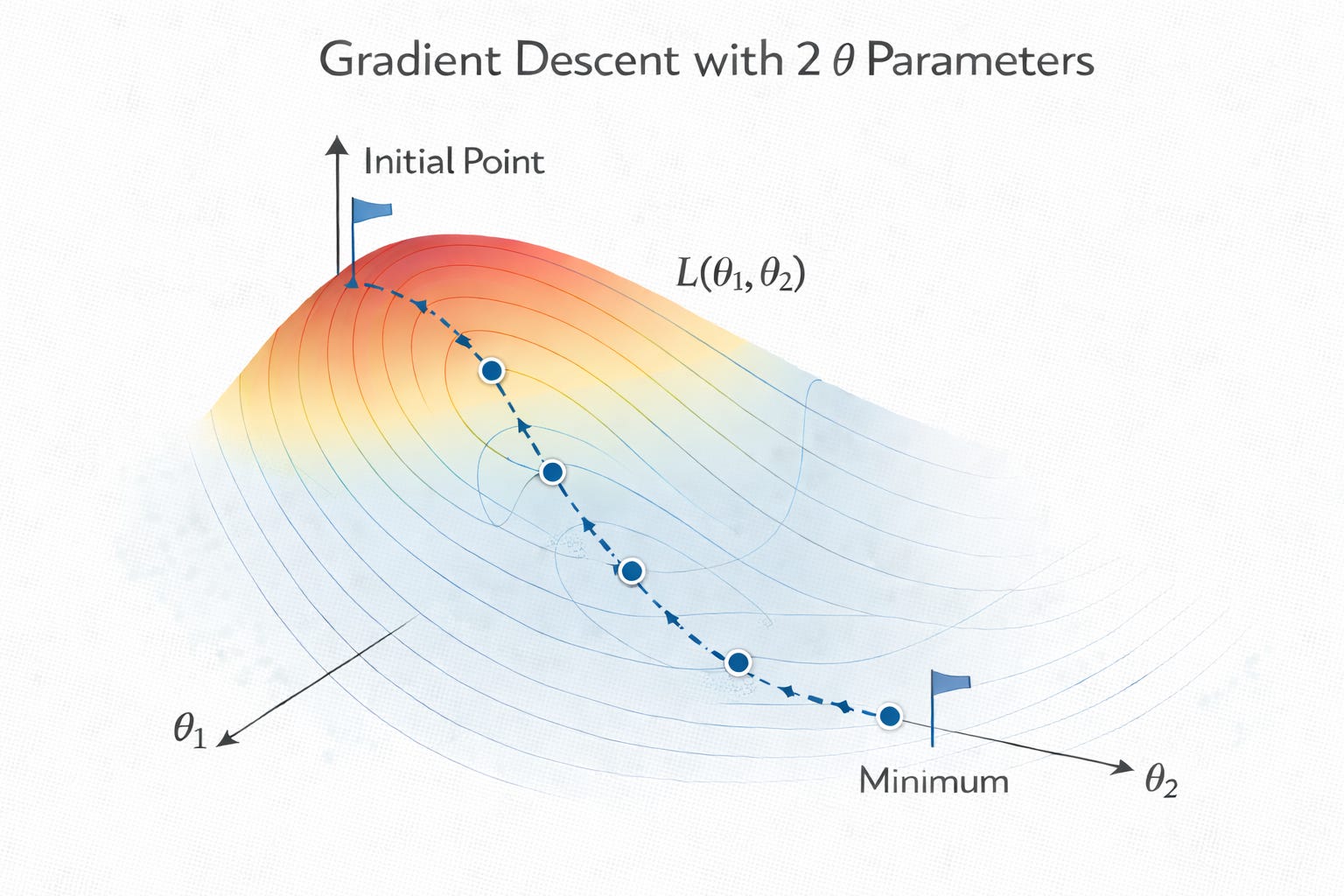
Như vậy, ở một góc độ nào đó, bức tranh đơn giản này giúp giải thích toàn bộ sức mạnh của các LLMs và generative AI liên quan. Một prompt đưa vào LLM thực sự được chia nhỏ thành nhiều lần thực thi của hàm mà chúng ta đã tìm ra các parameters của nó, nhằm tạo ra một chuỗi các tokens (các khối ký tự nhỏ nhất được hỗ trợ) để tạo thành một câu trả lời đầy đủ, với phản hồi từ các câu trả lời phụ (subanswers) trước đó đưa vào đầu vào của các lần thực thi hàm sau đó. Một số ứng dụng ấn tượng nhất cũng phụ thuộc vào các reasoning models, các mô hình này xây dựng toàn bộ tài liệu nội bộ trình bày cách giải quyết vấn đề từng bước một, sau đó chỉ hiển thị câu trả lời cuối cùng cho người dùng. Ví dụ, một chứng minh toán học có thể được phát triển theo từng bước suy luận nghiêm túc, bao gồm cả những lần thử sai cần phải quay lui (undo) khi AI không thể nghĩ ra nên thử gì tiếp theo. Tất cả các bước đó hoạt động về cơ bản bằng cùng một cách gọi lặp đi lặp lại một hàm có các parameters mà chúng ta đã học.
Tại sao Generative AI lại hoạt động tốt đến thế
Nhiều người thấy thật phản trực quan khi cách tiếp cận trả lời câu hỏi này lại hoạt động tốt như vậy. Đối với tôi, kết quả thực nghiệm liên quan là trí nhớ chiếm một phần lớn hơn nhiều trong trí thông minh so với những gì chúng ta nhận ra. Một LLM đang thực hiện một việc rất giống như ghi nhớ toàn bộ mạng web, sẵn sàng tái hiện lại các sự thật hữu ích khi cần thiết, mặc dù cấu trúc nội bộ thực tế của nó phức tạp hơn. Thay vì hạ thấp LLM như một stochastic parrot, tôi muốn mô tả công nghệ này như việc hỗ trợ các search engines hiệu quả đến kinh ngạc, giống như Google phiên bản cực mạnh. Vào năm 2020, tôi sẽ không dự đoán được rằng một search engine hàng đầu lại có thể cung cấp nhiều thứ mà chúng ta gọi là trí thông minh đến thế, nhưng nó đã làm được! Một phần khiến kỹ thuật này hiệu quả là nó không thực sự là một search engine theo nghĩa cũ, dựa vào cấu trúc bí ẩn được phát hiện từ dữ liệu phi cấu trúc, nhưng tôi nghĩ phép ẩn dụ này vẫn chứng minh được giá trị của nó.
Trên thực tế, các LLMs sử dụng một quy trình bên trong rất liên quan đến các search engines. Để hiểu được toàn bộ mạng lưới thông tin, chúng nén các đơn vị thông tin thành các chuỗi số có độ dài cố định nhất định, mà chúng ta gọi là một vector embedding. Một phần quan trọng trong việc thực thi LLM là tìm kiếm các góc trong không gian ý tưởng có các vector tương tự với vector của prompt.
Vì vậy, có vẻ như trên thực tế, việc tra cứu ký ức và làm tốt việc chắp nối chúng lại với nhau có thể bao hàm rất nhiều thứ mà chúng ta coi là trí thông minh, khi bạn có nhiều dữ liệu huấn luyện để làm việc cùng. Một LLM có lợi thế hơn hầu hết mọi chuyên gia hàng đầu trong bất kỳ câu hỏi nào, bởi vì nó có nhiều “ký ức” hơn để rút ra.
Ngoài ra còn có một lý do về evolutionary-psychology giải thích tại sao con người lại ngạc nhiên đến vậy trước hiệu quả hoạt động của các phương pháp này. Về mặt di truyền, chúng ta vẫn còn khá gần gũi với tổ tiên hunter-gatherer của hàng trăm nghìn năm trước. Họ sống trong các bộ lạc khoảng 100 người. Mỗi bộ lạc duy trì một cơ sở kiến thức chung về các kỹ năng sống một cách tương đối độc lập, được truyền miệng. Mỗi trưởng bối trong bộ lạc có thể lưu giữ trong ký ức cá nhân một phần khá lớn toàn bộ kiến thức sẽ trở nên liên quan đến cuộc sống của bất kỳ ai. Do đó, chúng ta nghĩ rằng mình hiểu việc đưa ra quyết định dựa trên một cơ sở kiến thức là như thế nào, mặc dù quy mô kiến thức của một LLM lớn hơn vô cùng so với những gì bất kỳ người nào từng biết, tạo ra những gì có vẻ như là một hiện tượng hoàn toàn khác biệt.
Kết quả là việc đánh giá thấp một cách có hệ thống về tần suất xảy ra việc một người trong chúng ta có một câu hỏi mà không ai chúng ta quen biết có thể trả lời, nhưng câu trả lời thực tế lại hiện diện ở đâu đó ngoài kia. Hãy nghĩ về các công ty 200 người và các câu hỏi khác nhau phát sinh trong hoạt động kinh doanh hàng ngày. Những biến thể tương đối nhỏ của các câu hỏi này có khả năng xuất hiện ở nhiều công ty khác nhau, và các biến thể này đủ nhỏ để việc tìm kiếm bằng cách sử dụng các vector embeddings có thể xác định các tài liệu liên quan trước đó (prior art) rất hiệu quả. Các lập trình viên thường đánh giá thấp mức độ giống nhau cực kỳ giữa các thử thách mới thú vị của họ với những thử thách khác đã được đăng trực tuyến. Mô hình này tiếp tục diễn ra trên nhiều lĩnh vực khác nhau.
Tuy nhiên, các khác biệt nhỏ vẫn xuất hiện trong một instance riêng lẻ của một danh mục câu hỏi đã được thiết lập sẵn. Câu trả lời thích hợp là sự kết hợp của các mẩu kiến thức (nuggets of wisdom) hiện có từ training data. Chúng ta ấn tượng và ngạc nhiên nhất khi những mẩu kiến thức đó đến từ các lĩnh vực khá khác nhau, đến mức có thể không có chuyên gia con người nào am hiểu về tất cả các lĩnh vực đó. LLM không bận tâm đến việc kết hợp tất cả các kiến thức chuyên môn đó, đôi khi mang lại các hiệu ứng hài hước như, chẳng hạn, các chatbot dịch vụ khách hàng sẵn lòng giải các bài tập hóa học nếu bạn yêu cầu một cách lịch sự. Trong khi một đội ngũ chuyên gia con người sẽ phải dành nhiều thời gian và tiền bạc cho sự phối hợp, thì một LLM có thể kết hợp các câu trả lời gần như ngay lập tức.
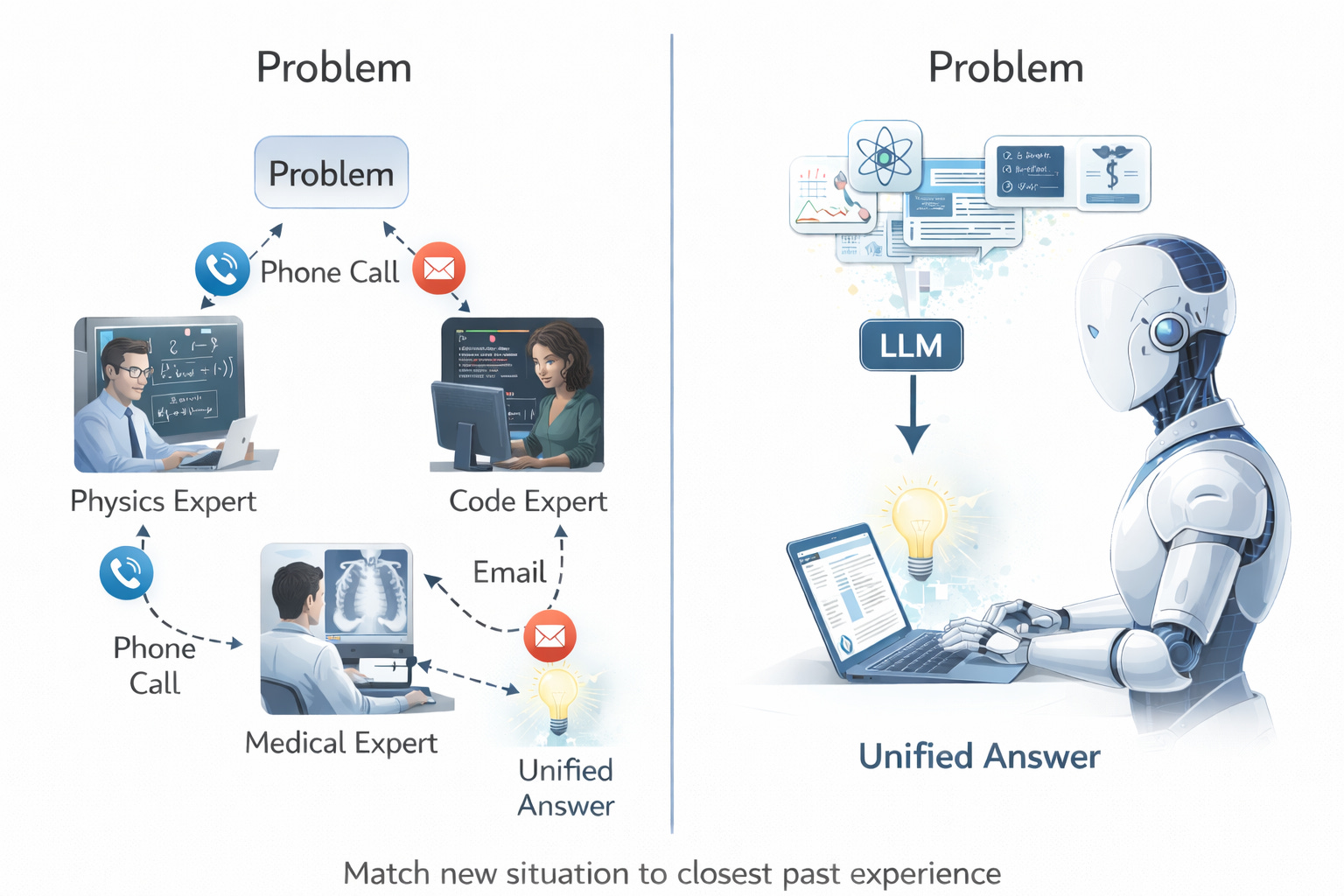
Kiểu luồng công việc này thực chất liên quan đến hai nghĩa khác nhau của từ “search”. Một mặt, có nghĩa từ information retrieval mà tôi đã nhấn mạnh đối với các LLMs: tìm kiếm các sự thật từ một cơ sở dữ liệu có liên quan nhất đến một câu hỏi. Mặt khác, chúng ta có nghĩa từ các tác vụ AI cổ điển như planning hoặc automated theorem proving, nơi chúng ta khám phá những cách khác nhau để kết hợp các thành phần cố định. Phong cách sau này tôi đã trình bày trước đây như a way to think about human work advancing the frontiers of knowledge, bao gồm cả an interesting role for formal verification in grading candidate solutions.
Bất kể các kỹ thuật cụ thể là gì, chúng ta đều đi đến mô hình sau để giải quyết các vấn đề mới (ở mức độ vừa phải). Ý tưởng là hai loại search này lần lượt tìm ra các ingredients (nguyên liệu) và toàn bộ recipes (công thức), được hiển thị trong sơ đồ tiếp theo, sơ đồ này có lẽ xứng đáng là “thứ cần ghi nhớ từ bài viết này”. Một vài ví dụ cụ thể của mô hình này là:
Để thiết kế một thiết bị cơ khí mới, tìm kiếm bản thiết kế cho một số thành phần vật lý liên quan và sau đó tạo ra một bản thiết kế mới liên kết chúng lại với nhau
Để viết một chương trình máy tính mới, tìm kiếm một tập hợp các thư viện mã nguồn liên quan và sau đó sử dụng chúng để viết chương trình một cách ngắn gọn
Để chứng minh một định lý toán học mới, tìm kiếm các định lý liên quan nhất từ các tài liệu học thuật và sau đó trích dẫn chúng trong một chứng minh mới
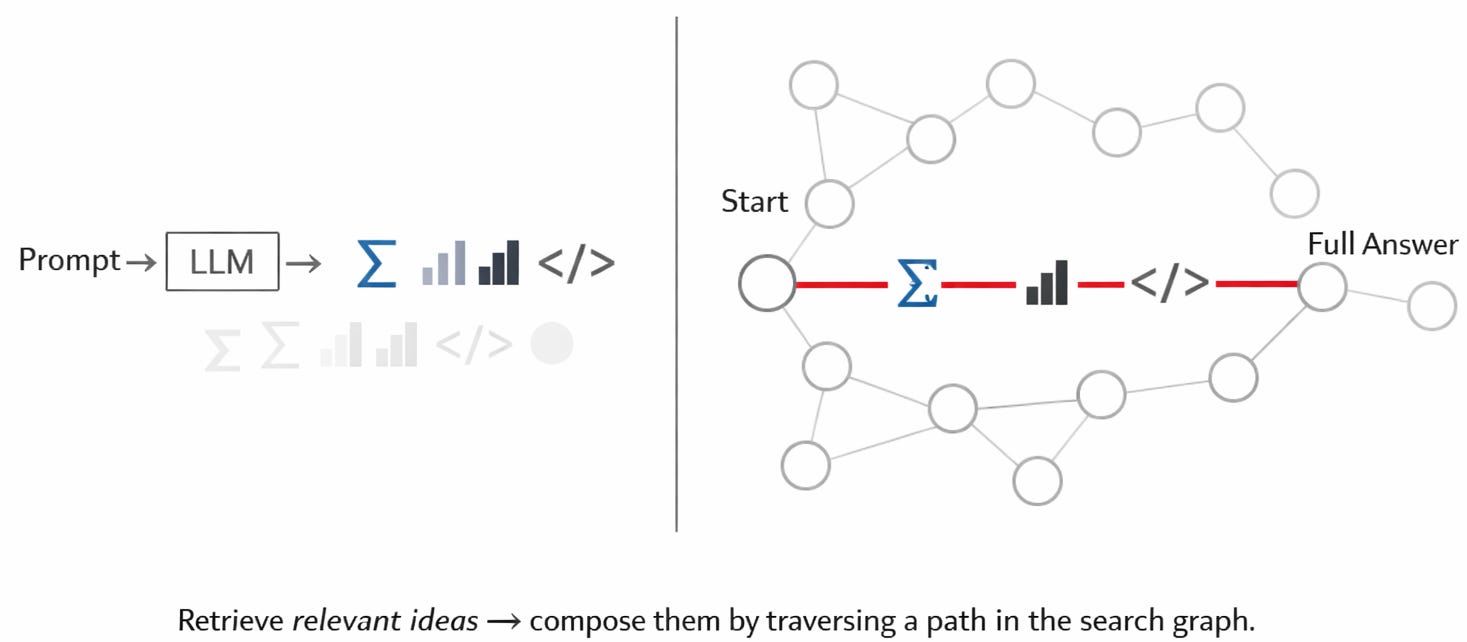
Các reasoning LLMs sử dụng cùng một quy trình information-retrieval để quyết định các bước trong việc search lắp ghép các ý tưởng thành các câu trả lời đầy đủ. Chúng có thể hoạt động hiệu quả nhất khi chính các quy trình kết hợp ý tưởng được thể hiện tốt trong training data. Tuy nhiên, chúng ta nên lường trước rằng các lĩnh vực như nghiên cứu tiên phong sẽ đặt ra các thách thức cho cả sự tồn tại của các ý tưởng tốt để phát triển lẫn các phương pháp để lắp ghép chúng.
Cũng đáng nhắc tới là cách đóng khung này có nhiều điểm chung với các ý tưởng từ AI cổ điển. Newell và Simon đã phát triển phương pháp tiếp cận heuristic-search bao gồm loại search thứ hai ở đây, và case-based reasoning sau đó được phát triển như một cách tiếp cận để tìm kiếm tiền lệ hữu ích và lắp ráp nó. Hofstadter đã thúc đẩy ý tưởng liên quan về analogy đóng vai trò cốt lõi trong giải quyết vấn đề.
Các bước tiếp theo
Deep learning cực kỳ hiệu quả trong việc tìm kiếm kiến thức liên quan nhất từ các tập dữ liệu lớn. Tuy nhiên, nó yếu hơn nhiều trong việc khám phá một cách có hệ thống cách thức kết hợp các ý tưởng, một phần thiết yếu của công việc tri thức tiên phong. Một vài bài viết tiếp theo sẽ chứng minh điều đó. Lý do đầu tiên tôi sẽ đề cập là một nút thắt hiệu năng (performance bottleneck) được hé lộ ngay từ cái tên “deep learning” – chúng ta nên lường trước rằng kiểu information retrieval này vốn dĩ đắt đỏ và chậm chạp. Sau đó, tôi sẽ thảo luận về mức độ khó khăn để đạt được bất kỳ hình thức cam kết mạnh mẽ nào về chất lượng câu trả lời từ deep learning, đối lập với một phong cách đã được thiết lập khác. Ngày nay nhiều người tin rằng nhiều vấn đề quan trọng quá thách thức đến nỗi chúng ta không có công cụ nào tốt hơn, và tôi sẽ dành một bài viết về cách tiếp cận đột phá để thu hẹp tập hợp các vấn đề đó, mở rộng phương pháp tiếp cận mà tôi đã đề cập cho các AI coding assistants.
“An LLM has an advantage over all but the top specialists in any given question, because it has so many more ‘memories’ to draw on.”
I actually like this comparison, because by comparing it to what we know as a ‘memory’ actually implies that these memories can be ‘encoded incorrectly’ in an LLM similar to how it could in a human. There are plenty of instances of false memories in human brains, where we might recall a situation incorrectly or recall a situation that may have never happened. I can imagine that an LLM equivalent would be hallucinations, or just incorrectly recalling certain facts from its training data.