
Khả năng Kháng Lật đổ Miễn phí từ Formal Verification
Tại sao chúng ta không cần lo lắng về việc liệt kê các cuộc tấn công khả thi

Formal verification có tiềm năng dự đoán tương lai của các hệ thống phần mềm phức tạp và ngăn chặn các hành vi tiềm ẩn có vấn đề nhất của chúng thông qua chứng minh toán học. Nó có thể là biện pháp bảo vệ hiệu quả nhất chống lại hành vi sai trái của các hệ thống superintelligent, những hệ thống mà chúng ta không thể thấy trước các kế hoạch cuối cùng của chúng. Tuy nhiên, chúng ta chỉ được bảo vệ nếu viết ra được các formal specifications thực sự ngăn chặn được các hành vi xấu đó. Trước đây tôi đã viết về hai kỹ thuật chính để đơn giản hóa việc viết các specifications đó, cụ thể là end-to-end formal verification, nhằm phát hiện các lỗi trong kết nối giữa các thành phần; và việc đóng gói cẩn thận hầu hết các thành phần tránh xa thế giới con người và tự nhiên phức tạp. Bây giờ tôi muốn viết về một lợi ích chưa được đánh giá đúng mức của các phương pháp chính quy đối với bảo mật, vốn đã phù hợp với các hệ thống truyền thống nhưng có lẽ còn quan trọng hơn đối với artificial intelligence. Khái niệm này đã được biết đến trong cộng đồng phương pháp chính quy (ví dụ xem thảo luận xung quanh hệ điều hành đã được xác thực seL4) nhưng vẫn chưa được hiểu rộng rãi.
Cuộc chạy đua Vũ trang Cybersecurity
Cybersecurity thường được mô tả là về cơ bản có lợi cho những kẻ tấn công hơn là những người phòng thủ. Lý do là kẻ tấn công thường chỉ cần tìm một lỗ hổng trong hệ thống để lật đổ nó, trong khi người phòng thủ (hoặc tác giả của hệ thống) cần phải dự đoán tất cả các cuộc tấn công khả thi và xây dựng các biện pháp bảo vệ chống lại tất cả. Việc không nhận thấy chỉ một vector tấn công tiềm năng, hoặc đơn giản là trì hoãn quá lâu trong việc vá một lỗ hổng đã biết, có thể cho phép kẻ tấn công gây ra thiệt hại hiệu quả như thể hệ thống chứa đầy các vấn đề bảo mật rõ ràng.
Một trong những loại lỗ hổng bảo mật tồi tệ nhất thường được gọi là remote code execution: cách thức mà kẻ tấn công có quyền truy cập mạng vào hệ thống có thể đánh lừa hệ thống chạy mã chương trình mới do kẻ tấn công cung cấp. Bất kể những gì chúng ta nghĩ một hệ thống nên làm, kẻ tấn công sửa đổi code của nó có thể thay đổi kế hoạch một cách khá tùy ý. Danh mục này là một trường hợp đặc biệt của hiện tượng tổng quát hơn về việc lật đổ một hệ thống. Tôi đánh giá cao từ đồng nghĩa gợi mở perversion (sự biến tính/suy đồi) từ tác phẩm A Fire Upon the Deep, áp dụng cho các trí tuệ nhân tạo nổi loạn.
Có vô vàn các cuộc tấn công remote code execution khác nhau, và các kỹ sư cần đảm bảo chặn tất cả chúng, ngay cả khi những cuộc tấn công mới xuất hiện thường xuyên. Một trong những kiểu cổ điển là buffer-overflow attack, nơi một phân đoạn bộ nhớ được dự phòng để chứa đầu vào của người dùng, nhưng một lỗi lập trình khiến đầu vào của người dùng tràn ra ngoài vùng đó và đi vào các vùng lân cận. Nếu một vùng lân cận được sử dụng để chứa machine code cần thực thi, chúng ta đã cung cấp cho kẻ tấn công một cách để tiêm code của riêng hắn vào thực thi.
Hiện tượng code-injection attacks là một hiện tượng rộng lớn, và thông thường các biến thể khác nhau có những cái tên phổ biến che giấu sự tương đồng của chúng. Khi đầu vào của người dùng được phép cung cấp code bằng ngôn ngữ cơ sở dữ liệu SQL, chúng ta gọi đó là một SQL injection. Khi một tình huống tương tự xảy ra với ngôn ngữ lập trình JavaScript, điển hình nhất là trong trình duyệt web, chúng ta gọi đó là cross-site scripting. Thoạt nhìn, có vẻ như chúng ta với tư cách là các kỹ sư của các hệ thống bảo mật tiềm năng cần tiến hành kiểm toán cẩn thận tất cả các ngôn ngữ lập trình được sử dụng bên trong, đảm bảo không ngôn ngữ nào trong số chúng cung cấp các lỗ hổng code-injection.
Tuy nhiên, mọi chuyện còn tệ hơn. Chỉ liệt kê các ngôn ngữ lập trình là chưa đủ tốt, bởi vì những kẻ tấn công tìm thấy những cách mới để triển khai chức năng dạng injection-like trong các ngôn ngữ đã được thiết lập. Các cuộc tấn công buffer-overflow gây chú ý đầu tiên liên quan đến việc smashing the stack (phá hủy ngăn xếp) để ghi đè lên một số nơi được sử dụng để lưu trữ địa chỉ code cần thực thi. Khi các biện pháp giảm thiểu stack-smashing ngày càng hiệu quả (như address-space layout randomization, giúp việc đoán địa chỉ code nào chứa code nào trở nên khó khăn, do đó khó đoán được tác động của một cuộc tấn công) được triển khai, những kẻ tấn công đã phát triển các loại weird machines ngày càng tinh vi hơn, một cụm từ gợi lên việc tìm thấy các chức năng ẩn bên trong các chương trình tưởng chừng vô hại. Một ý tưởng gọi là return-oriented programming tạo ra các chuỗi thực thi tưởng chừng không thể bên trong code hợp lệ của một chương trình bằng cách khâu các phân đoạn code lại với nhau theo những cách đáng ngạc nhiên, tạo ra các hành vi mới nổi (emergent behaviors) từ các mảnh riêng lẻ vốn vô hại.
Và ở đây chúng ta dường như bị mắc kẹt với tư cách là những người phòng thủ siêng năng. Đã đủ tệ nếu chúng ta cần nhận biết mọi nơi bên trong một hệ thống phức tạp chứa một ngôn ngữ lập trình mà kẻ tấn công có thể sử dụng để tiêm và chạy code của riêng hắn. Chúng ta cũng cần tưởng tượng ra đủ loại cách thức gian xảo mà chức năng đó có thể được xây dựng trên đầu các ngôn ngữ cụ thể, bao gồm cả những cách chưa được phát minh vào thời điểm code được triển khai.
Các hệ thống AI trong tương lai, đặc biệt là các hệ thống superintelligent, sẽ làm trầm trọng thêm những lo ngại này. Để bắt đầu, các khả năng cơ bản của các hệ thống này để tác động đến thế giới này có thể quá cao đến mức việc để kẻ tấn công lật đổ một trong số chúng và quay lại chống lại chủ nhân của nó sẽ càng thảm khốc hơn. Tiếp theo, như được nhấn mạnh bởi việc sử dụng Mythos AI model gần đây để tìm các lỗ hổng bảo mật mới trong các phần mềm được sử dụng rộng rãi, AI có năng lực cao (highly capable AI) có thể đồng nghĩa với việc chấm dứt phương pháp security through obscurity (bảo mật thông qua sự mơ hồ) vốn đã bị phản đối. Các hệ thống Superintelligent có thể tìm ra các lỗ hổng lâu năm mà các hacker con người chưa bao giờ phát hiện ra.
Vì vậy, nơi một kỹ sư mới vào nghề có thể lo lắng rằng quá khó để dự đoán tất cả các cuộc tấn công chống lại một hệ thống quan trọng, nhưng nơi một người đang học về các phương pháp chính quy có thể hào hứng về tiềm năng loại bỏ các cuộc tấn công đó bằng toán học, chúng ta cũng thấy cách một kỹ sư hiểu biết hơn có thể lo lắng rằng việc thậm chí mô tả tất cả các cuộc tấn công trong một formal specification là không thực tế, chưa nói đến việc chứng minh rằng các biện pháp giảm thiểu cụ thể giải quyết được chúng.
Giải cứu: Functional Correctness ngụ ý Khả năng Kháng Lật đổ
May mắn thay, ở cấp độ giác ngộ tiếp theo, chúng ta thấy rằng việc sử dụng formal verification để chặn tất cả các cuộc tấn công trên là khá dễ dàng, nếu chúng ta chứng minh được hầu như bất kỳ điều gì.
Hãy nghĩ về một formal specification như việc vạch ra những điểm đến nào là hợp lệ trong không gian thực thi của một hệ thống, dựa trên các điểm xuất phát.
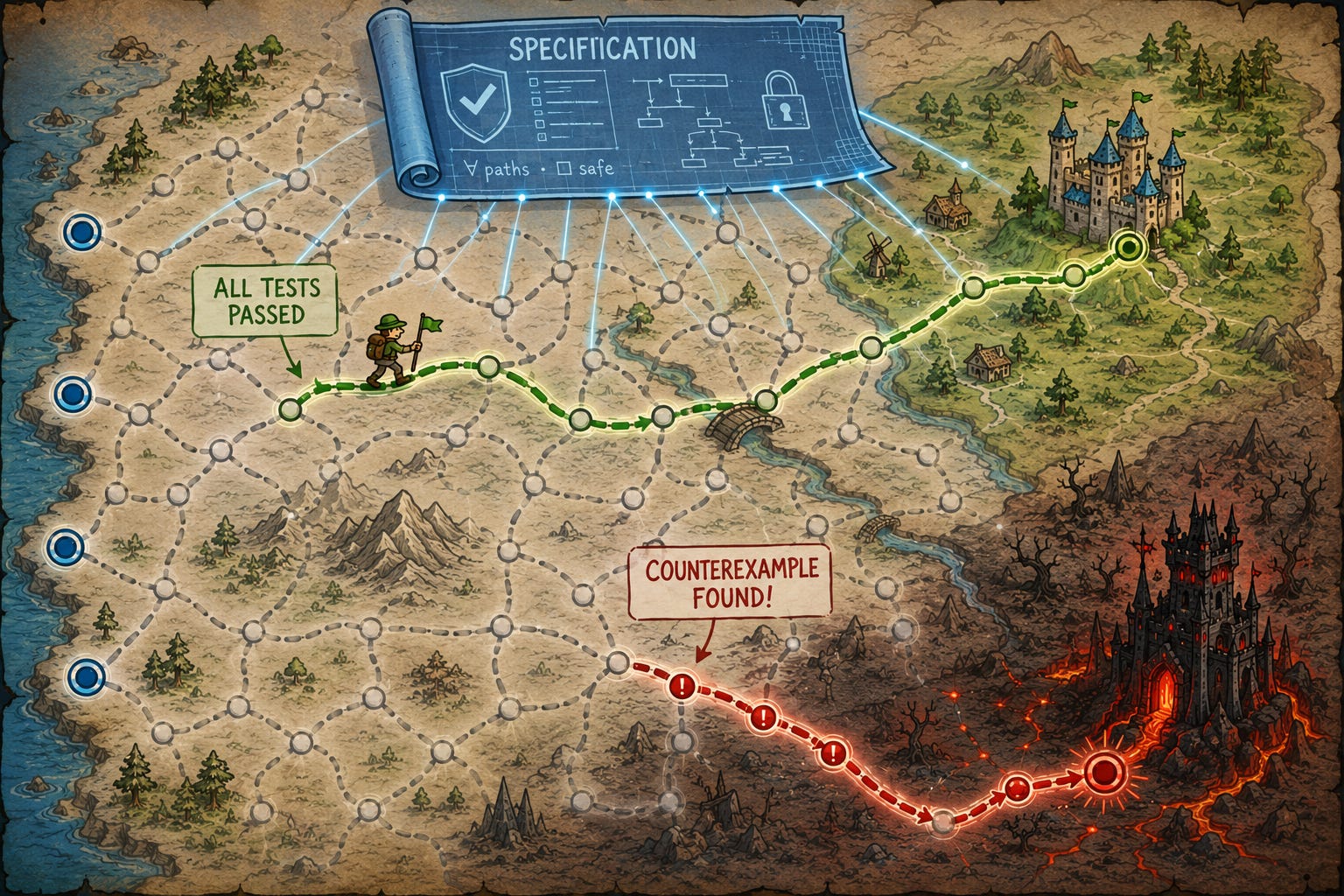
Rắc rối với việc chỉ thử nghiệm (test) một hệ thống là chúng ta có thể chạy nhiều ca thử nghiệm, thấy rằng mỗi ca đều đến một điểm đến được chấp nhận, và tuy nhiên hệ thống vẫn thể hiện hành vi thảm khốc trong vô số tình huống khác nhau mà chúng ta không nghĩ tới để thử nghiệm. Formal verification có thể chứng minh hành vi được chấp nhận trong tất cả các lần thực thi khả thi.
Bây giờ giả định rằng chúng ta đã đầu tư vào việc chứng minh functional correctness cho một chương trình, điều này có nghĩa đại khái là chúng ta chứng tỏ nó thực sự thực hiện đúng ý định của người tạo ra nó. Ví dụ, một chương trình có nhiệm vụ sắp xếp các danh sách số nguyên theo thứ tự tăng dần thực sự xuất ra phiên bản đã được sắp xếp của mỗi đầu vào. Cố gắng định nghĩa chính xác về mặt hình thức specifications nào được tính là functional correctness có thể là một cuộc chơi thất bại, nhưng chúng ta kỳ vọng rằng các specifications như vậy đủ chính xác để nhiều thay đổi nhỏ trong chương trình sẽ phá vỡ chúng. Hãy giữ từ trực giác này một yêu cầu thậm chí còn lỏng lẻo hơn: hãy tưởng tượng bất kỳ specification nào chấp nhận một số hành vi của hệ thống chứ không phải tất cả. Hãy để BAD là một số hành vi không được phép nhưng có thể được diễn đạt bằng ngôn ngữ lập trình cơ sở. Bây giờ chúng ta sẽ thực hiện một mánh khóe gợi nhớ đến cuộc thảo luận trước đây của chúng ta về các thuộc tính chương trình undecidable và Rice’s theorem.
Hãy tưởng tượng kẻ tấn công tìm ra cách tiêm code vào hệ thống và chạy code đó, mang lại sự tự do to lớn trong việc làm xáo trộn hành vi của hệ thống. Kẻ tấn công có thể sử dụng sự tự do đó chỉ để tải lên chương trình chứa hành vi BAD, tạo ra hành vi vi phạm specification, và do đó formal verification of the program phải thất bại, mặc dù không liệt kê bất kỳ yêu cầu nào về code injection. Trong hình ảnh tiếp theo này, tôi đang sử dụng phép ẩn dụ về việc một cuộc tấn công tiêm mã (injection attack) mở ra cánh cổng dẫn đến một thế giới cực kỳ linh hoạt cho kẻ tấn công, người được phép tải lên và chạy các chương trình tùy ý trong một ngôn ngữ diễn đạt tốt, đến mức về cơ bản đảm bảo rằng, một khi cánh cổng mở ra, kẻ tấn công có thể tìm thấy một cách nào đó (có thể là vô số cách) để gây ra thiệt hại nghiêm trọng.
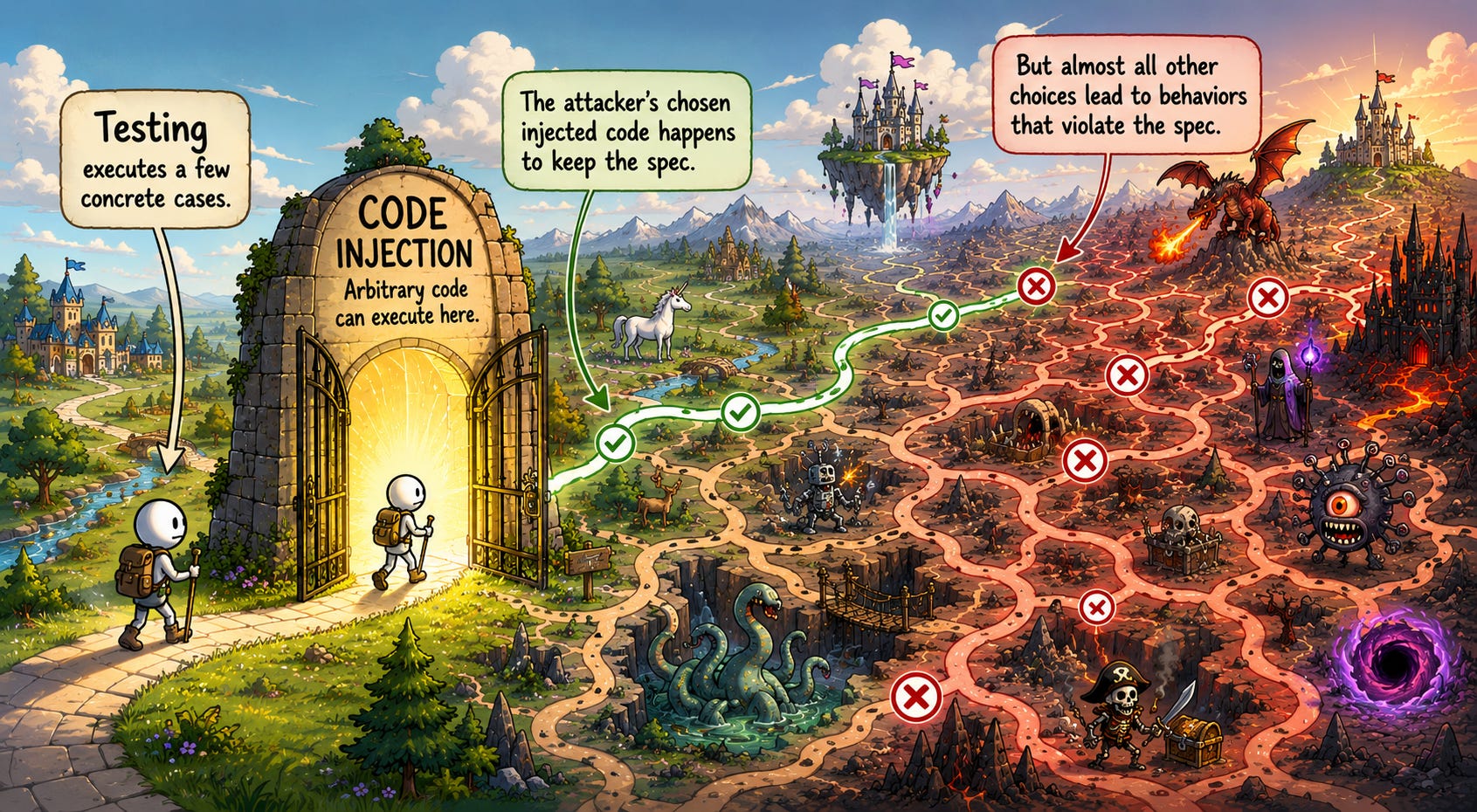
Ví dụ, có thể có một dịch vụ Internet dùng để cộng các số dương theo yêu cầu. Specification của nó có thể giải thích chính xác tổng số nào sẽ được tạo ra, tương ứng với yêu cầu nào. Or specification của nó có thể chỉ cần tuyên bố rằng dịch vụ chỉ xuất ra các số dương. Cả hai đều đủ để đảm bảo rằng không có cuộc tấn công injection attack nào cho phép cài đặt code tùy ý. Nếu lỗ hổng đó thực sự tồn tại, thì chúng ta có thể làm cho hệ thống trả về số không, điều này vi phạm cả hai specifications.
Trong thực tế, các tác giả của specifications hoàn toàn không cần phải nghĩ một cách rõ ràng về các code injections. Chỉ cần giải thích một cách tích cực những gì một chương trình phải làm, thay vì liệt kê một cách tiêu cực những gì nó phải bị ngăn chặn thực hiện. Chúng ta đã thấy một ví dụ trong end-to-end verification của một hệ thống IoT đơn giản, đặc tả của nó chỉ đơn giản giải thích cách một network protocol hoạt động, tuy nhiên vẫn loại bỏ khả năng hệ thống bị tiếp quản bởi một gói tin được thiết kế tinh vi và bị lừa tham gia vào một botnet.
Kết luận
Quan sát này chắc chắn không giải quyết được tất cả các thách thức của AI alignment. Chúng ta nên kỳ vọng superintelligence sẽ được trao quyền tự do rộng rãi trong việc lập kế hoạch và biến đổi thế giới đến mức không thể mô tả bằng một specification cô đọng. Tuy nhiên, có vẻ hợp lý khi giả định rằng bất kỳ specification hữu ích nào cũng loại trừ một số hành vi, từ đó vẫn suy ra rằng những kẻ tấn công không thể giành được quyền truy cập để chạy code tùy ý. Do đó, có một con đường tương đối rõ ràng hướng tới việc sử dụng formal verification để phát triển các hệ thống AI có năng lực cao sẽ kháng cự lại việc bị lật đổ.
Trên thực tế, nguyên tắc này khái quát hóa cho bất kỳ trường hợp nào liên quan đến các mục tiêu cấp cao nhất phải được hiện thực hóa bằng các chi tiết triển khai cấp thấp hơn mà chúng ta không cần nêu chi tiết trong các formal specifications. Ví dụ:
Nếu một kẻ tấn công tìm ra cách khéo léo để ghi đè lên trạng thái được lưu trữ của một hệ thống, thì có lẽ hoặc trạng thái đó không quan trọng, hoặc kẻ tấn công có một đòn bẩy đơn giản để làm xáo trộn hành vi lệch khỏi những gì được chỉ định.
Nếu một kẻ tấn công có thể can thiệp vào luồng thông tin từ các cảm biến vào quá trình ra quyết định, chẳng hạn bằng cách lợi dụng một điểm yếu tinh tế trong digital signal processing (xử lý tín hiệu số), thì hoặc các cảm biến đó không quan trọng, hoặc việc bóp méo giá trị của chúng một cách tùy ý có thể dễ dàng dẫn đến vi phạm specification.
Ngược lại, nếu kẻ tấn công có thể phá hỏng logic kiểm soát cách hệ thống thực hiện hành động trong thế giới thực, thì việc tạo ra các vi phạm specification sẽ càng dễ dàng hơn. Hãy tưởng tượng một ví dụ về một tác nhân mua sắm trực tuyến gặp lỗi lặp đi lặp lại đơn hàng cuối cùng nhiều lần, thay vì phản hồi các yêu cầu mới. Hành vi như vậy sẽ vi phạm các specifications trên dải phân giải từ “chỉ đặt các đơn hàng mà người dùng đồng ý một cách rõ ràng” đến “không đặt đơn hàng vượt quá hạn mức chi tiêu thẻ tín dụng của bạn” (bởi vì đơn hàng lặp lại có thể tình cờ là một đơn hàng khổng lồ, ngay cả khi các đơn hàng hợp lệ sau đó chỉ dành cho các mặt hàng giá rẻ; hãy nhớ rằng, với formal verification, chúng ta suy luận trước về tất cả các tình huống khả thi).
Ngay cả các ví dụ về việc làm độc dữ liệu huấn luyện của các hệ thống tự học cũng được bao quát, miễn là các thành phần học được là chi tiết triển khai không được đề cập trực tiếp trong các specifications. Hoặc thành phần học được là không liên quan đến nhiệm vụ cấp cao nhất, hoặc việc kiểm soát dữ liệu tùy ý cho phép phá vỡ specification mà không tốn quá nhiều công sức.
Tất nhiên, phần lớn cách tiếp cận deep learning-maximalist hiện tại được xây dựng xung quanh việc giả định rằng các hệ thống học được đóng vai trò trung tâm để đáp ứng các specifications, bất chấp việc thiếu các cách chứng minh trước rằng các thành phần học được không gây ngạc nhiên cho chúng ta, vì vậy sự trấn an của tôi ở đây trong viên đạn cuối cùng chỉ áp dụng cho các ví dụ mà các thành phần học được được phân tách rõ ràng và chỉ gây ra lo ngại về các chi tiết triển khai như dữ liệu huấn luyện đến từ đâu. Chúng ta nên nhớ rằng đôi khi chúng ta nhận ra mình đã bỏ qua các khía cạnh bổ sung của top-level specification, như trong trường hợp rò rỉ bí mật thông qua thời gian (timing) mà chúng ta đã thảo luận trước đó. Tuy nhiên, có sức mạnh to lớn trong việc chỉ cần xác định các yêu cầu cấp cao nhất của một hệ thống và không lo lắng về các lỗ hổng bị bỏ sót trong các chi tiết triển khai cấp thấp.
Các bài đăng tiếp theo sẽ đề cập đến hai cách khác mà chúng ta kỳ vọng việc viết specification sẽ trở nên đơn giản hơn khi nhiều bộ phận của nền kinh tế bị chi phối bởi các AI agents tương tác với nhau. Chúng ta sẽ bắt đầu bằng cách xem xét lại các user interfaces trong thế giới đó, nơi người dùng ngày càng không thuộc cùng một loài nữa.