
Đơn giản hóa alignment bằng cách mở rộng phạm vi
Một lợi thế phi trực quan cho những người tốt

Tôi vừa tóm tắt câu chuyện cho đến nay về phương pháp mà tôi đang trình bày để xây dựng trí tuệ nhân tạo đáng tin cậy, và giờ tôi muốn lùi lại một bước để giải thích thêm về các thành phần chính. Để sử dụng formal verification nhằm chứng minh bằng toán học rằng các chương trình hoạt động như chúng ta mong muốn, trước tiên chúng ta cần giải thích những gì chúng ta muốn một cách cực kỳ chi tiết. Những lời giải thích như vậy được gọi là specifications.
Thách thức trong việc xây dựng specifications chính xác có liên quan chặt chẽ đến một vấn đề nổi bật trong AI safety, đó là alignment. Nói một cách đại khái, cả hai vấn đề đều là các biến thể của mối nguy hiểm cổ điển khi yêu cầu một genie thực hiện một điều ước. Nếu một linh hồn tội nghiệp nào đó đưa ra một điều ước không chính xác, genie có thể sẽ mang lại cho anh ta một điều gì đó tồi tệ nhưng lại khớp chính xác với nghĩa đen của điều ước. AI alignment đặc biệt quan tâm đến các recursively self-improving systems có khả năng tự sửa đổi mã nguồn của chính chúng, có lẽ phải tuân theo các ràng buộc từ các specifications được cung cấp trước – điều này chẳng mang lại mấy sự an tâm nếu các specifications không phản ánh chính xác ý định thực sự của chúng ta, theo những cách mở ra cánh cửa dẫn đến thảm họa. Nếu một superintelligence tự tìm cách khai thác các lỗ hổng trong specifications của chúng ta, chúng ta có thể sẽ gặp rắc rối lớn.
Tuy nhiên, tình hình của nhiều thập kỷ trước đã khá rủi ro theo những cách điển hình. Thứ nhất, các software engineers là con người có thể mắc sai lầm. Quan trọng hơn, ai đó cung cấp một phần mềm hấp dẫn thực chất có thể đang muốn hãm hại chúng ta. Sẽ không thực tế nếu tự viết tất cả phần mềm của chúng ta từ đầu, thế nhưng việc phân chia công việc lại khiến chúng ta có nguy cơ bị phá hoại bởi các tác giả viết code. (Và trước khi ai đó phản đối rằng các AI coding assistants giờ đây giúp việc tự viết tất cả phần mềm từ đầu trở nên khả thi, thì chế độ sử dụng đó chỉ làm tăng nguy cơ sai sót hoặc phá hoại từ chính các tác nhân đó!) Tôi đã viết trước đây về cách các agents sharing code with each other buộc phải có giải pháp cho vấn đề này, điều mà may mắn thay đã được nghiên cứu trong bối cảnh truyền thống trước đây.
Chủ đề của bài viết này là một tin vui về việc alignment, hay việc thiết lập specifications chính xác, thực ra dễ dàng hơn những gì chúng ta tưởng. Dù ở mức độ quen thuộc nào với chủ đề này, hầu hết mọi người có lẽ đều đồng ý rằng chúng ta kỳ vọng alignment sẽ ngày càng thách thức hơn khi các hệ thống tăng độ phức tạp. Càng nhiều bộ phận chuyển động có nghĩa là càng nhiều bộ phận có thể dẫn đến kết quả xấu, và việc bỏ qua việc viết specification cẩn thận cho bất kỳ bộ phận nào bằng cách tin tưởng vô căn cứ dường như sẽ mang lại hậu quả tai hại. May mắn thay, kỹ thuật lâu đời mang tên end-to-end formal verification cung cấp một cách phi trực quan để tận dụng phạm vi mở rộng nhằm giảm thiểu rủi ro sai sót trong specification.
End-to-End Formal Verification
Bài viết này sẽ đưa chúng ta qua một loạt các bước khai sáng trong việc xây dựng hệ thống. Chúng ta có thể bắt đầu bằng việc nhận thấy rằng phần mềm dường như cực kỳ khó để viết đúng hoàn toàn, vì vậy việc đầu tư vào các kỹ thuật kiểm định chất lượng có kỷ luật là rất xứng đáng. Formal verification, với trọng tâm là các chứng minh chặt chẽ rằng các bản cài đặt đáp ứng đúng specifications, là một kỹ thuật hấp dẫn một cách trực quan. Còn gì tuyệt vời hơn sự chắc chắn về mặt toán học rằng một hệ thống hoạt động đúng mực?
Chúng ta đã chuẩn bị sẵn sàng cho sự phản đối đầu tiên: chứng minh chỉ giúp ích khi nó chứng minh được định lý chính xác, tức là specification của một sản phẩm. Nếu chúng ta viết sai specification, thì chúng ta có thể rơi vào tình trạng tồi tệ hơn, do cảm giác an toàn giả tạo từ một chứng minh đầy đủ nhưng sai hướng. Tuy nhiên, vì mục đích lập luận, hãy giả định rằng chúng ta đã tạo ra một formal specification ghi lại tất cả các yêu cầu thực sự của chúng ta đối với một hệ thống.
Giả sử hệ thống đó là một phần mềm phức tạp. Người hoài nghi dần được khai sáng sẽ nhận ra rằng phần mềm không chỉ tự chạy độc lập. Luôn có một programming-language implementation bên dưới, và nếu thành phần đó có lỗi thì sao? Khi đó hành vi có thể bị thay đổi tùy ý, làm mất hiệu lực của toàn bộ công việc chứng minh ban đầu của chúng ta. Nhưng tại sao lại dừng lại ở đó? Còn phần cứng máy tính mà chương trình chạy trên đó thì sao? Sự suy diễn vô hạn này có thể tiếp diễn bao lâu tùy thích, thậm chí có thể kết thúc ở cơ học lượng tử.
Với end-to-end formal verification, chúng ta chọn dừng các câu hỏi "nếu thế thì sao" ở một cấp độ nào đó và sau đó chứng minh tất cả các thành phần liên quan như một khối thống nhất. Chi phí kỹ thuật thường hợp lý nhất khi việc xác minh này được thực hiện một cách modularly, nghĩa là mỗi thành phần tự nhiên đều có specification và chứng minh riêng, sau đó chúng ta tổng hợp chúng thành một specification và chứng minh của toàn bộ hệ thống. Dưới đây là sơ đồ phân rã hệ thống phân tầng tự nhiên, tuân theo mô hình phổ biến là dịch dần mã cấp cao sang mã cấp thấp hơn khi chúng ta đi xuống sơ đồ. (Chúng ta sẽ quay lại để thảo luận về các hộp intermediate specification trong phần tiếp theo.)
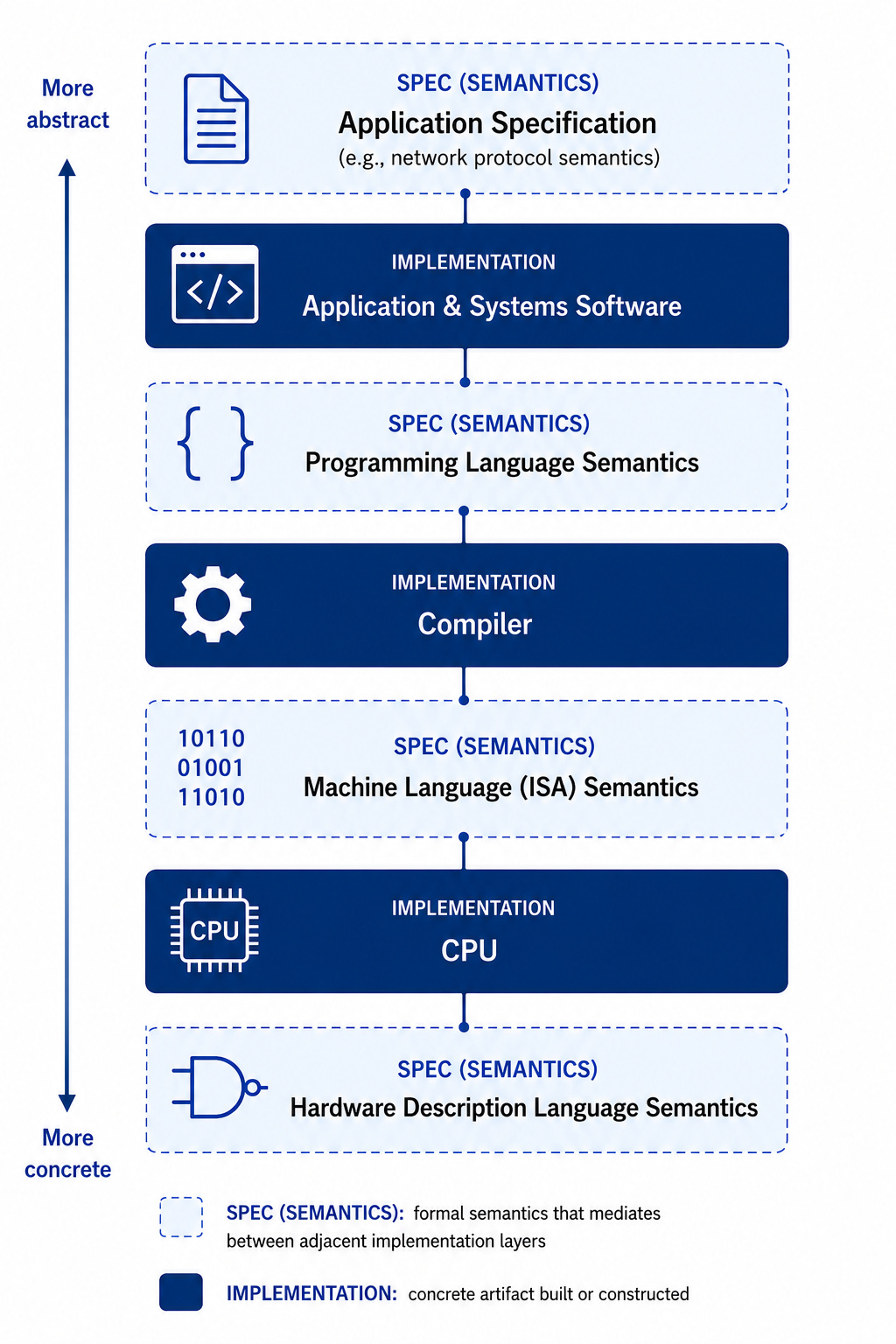
Trong khi việc suy nghĩ về việc align cho superintelligence bắt buộc phải gần như hoàn toàn mang tính lý thuyết và thậm chí là triết học, thì end-to-end formal verification đã khả thi một cách cụ thể trong nhiều thập kỷ, và chúng ta có thể tìm hiểu về các thách thức cũng như tiềm năng rộng lớn hơn bằng cách nghiên cứu các ví dụ thực tế. Một trong những dự án liên quan của riêng tôi là the verified IoT lightbulb, với một chứng minh thống nhất cho tất cả các phần kỹ thuật số của một hệ thống đơn giản để điều khiển một bóng đèn thông qua kết nối Internet. Góc dưới bên trái của bức ảnh sau đây cho thấy một field-programmable gate array (FPGA), một loại phần cứng có thể tái cấu hình thay thế cho việc chế tạo silicon tùy chỉnh, mặc dù dự án được cấu trúc để tương thích với việc sản xuất silicon vào một ngày nào đó. Hệ thống này bao gồm tất cả các tầng từ sơ đồ trước đó, được chứng minh cùng nhau như một khối thống nhất.

Một dự án tiếp nối chỉ giới hạn ở khĩa cạnh phần mềm nhưng bao gồm các chức năng toàn diện hơn, bao gồm một giao thức cryptographic phức tạp, dành cho the verified garage-door opener. Theo xu hướng mới nhất, hầm để xe bằng Lego này có một microcontroller trên mái, chạy giao thức cryptographic để đảm bảo rằng chỉ chủ sở hữu hợp pháp của hầm xe, người duy nhất giữ một private key nhất định, mới có thể mở và đóng cửa hầm xe qua Internet.

Những loại dự án này rất thỏa mãn trong việc theo đuổi end-to-end formal verification đủ xa để trả lời cho nhiều câu hỏi "nếu thế thì sao" như tôi đã chỉ ra ở trên. Tuy nhiên, người quan sát nhạy bén sẽ nhận ra một vấn đề có vẻ như là chí mạng lúc ban đầu.
Specifications cho các Tầng Trung gian
Bây giờ chúng ta hãy chuyển sang các tầng trong sơ đồ đầu tiên được gắn nhãn là specifications. Các specifications đó đóng vai trò là interfaces between layers. Mỗi cái thiết lập một cách hiệu quả một bản contract mà hai tầng hứa sẽ tuân theo khi hợp tác. Các ví dụ trong sơ đồ là:
Cái application specification làm trung gian giữa ý định của người dùng và hành vi của chương trình.
Cái programming-language semantics (nghĩa hình thức của các chương trình) làm trung gian giữa các chương trình và việc thực thi ngôn ngữ (ở đây là một compiler).
Cái machine-language semantics làm trung gian giữa software compiler và phần cứng.
Cái hardware-description-language semantics làm trung gian giữa việc triển khai phần cứng và ngôn ngữ mà nó được viết bằng.
Một specification ở tầng giữa điển hình loại này có hai đặc điểm mà khi kết hợp lại, có vẻ như cực kỳ đáng ngại. Thứ nhất, một lỗi trong một specification như vậy có thể phá hủy hoàn toàn hiệu lực của toàn bộ nỗ lực chứng minh. Thứ hai, các intermediate specifications này có thể dễ dàng dài hơn và phức tạp hơn nhiều so với specifications của các chương trình cấp cao nhất cụ thể. Hãy nghĩ về định nghĩa dài bằng cả cuốn sách của một ngôn ngữ lập trình phổ biến so với một bản mô tả dài một trang về một chương trình có phạm vi hạn chế nhưng quan trọng.
Còn một sự tinh tế đầy thách thức khác ở đây chứ không chỉ là khả năng "viết sai spec". Thông thường, các tầng của một hệ thống sẽ được formally verified bằng các phương pháp và công cụ khác nhau vốn không dùng chung một ngôn ngữ specification. Một specification cho trước có thể được viết riêng biệt bằng hai ngôn ngữ, làm dấy lên nỗi lo sợ về sự không nhất quán giữa hai cách thể hiện khác nhau của cùng một specification.
Sự không nhất quán có thể gây ra bao nhiêu tác hại? Hãy lấy một ví dụ phổ biến về undefined behavior trong các ngôn ngữ lập trình. Ý tưởng ở đây là một ngôn ngữ có các quy tắc mà tất cả các lập trình viên phải tuân theo, và việc vi phạm các quy tắc đó sẽ "làm mất hiệu lực bảo hành" và cho phép việc thực thi ngôn ngữ hoạt động theo bất kỳ cách nào nó muốn. Làm thế nào một điều khoản mang tính trừng phạt như vậy lại có thể là một ý tưởng hay? Vấn đề là những người triển khai ngôn ngữ muốn tích hợp việc tự động sử dụng các tối ưu hóa thay cho các lập trình viên, nhưng việc tối ưu hóa có an toàn để áp dụng hay không thường phụ thuộc vào các khía cạnh hành vi của chương trình vốn là undecidable, vì vậy việc triển khai ngôn ngữ không thể kiểm tra thuộc tính đó mà không vô tình chặn các chương trình thực sự đáp ứng các yêu cầu. Cách khắc phục là tuyên bố các hành vi chương trình đặc biệt phức tạp là undefined behavior, do đó việc triển khai ngôn ngữ không còn cần phải xem xét chúng nữa.
Ví dụ, nếu một chương trình bao gồm một chuỗi gồm 100 phần tử và chương trình cố gắng đọc phần tử thứ 101, thao tác đó sẽ được coi là undefined behavior trong C và các ngôn ngữ liên quan. Điểm mấu chốt là các lập trình viên hợp lý nên đồng ý rằng việc đọc ngoài phạm vi (out-of-bounds) trong một chuỗi là một lỗi, và tại sao việc triển khai ngôn ngữ lại phải được tạo ra để giải quyết các lỗi của lập trình viên? Tất nhiên, lời đáp trả điển hình của các lập trình viên là việc tránh các lỗi rất khó, và các rào chắn bảo vệ luôn được trân quý! Tuy nhiên, các ngôn ngữ như C được thiết kế cho những nhóm người cuồng hiệu năng đến mức họ chấp nhận rủi ro của undefined behavior.

Undefined behavior liên quan thế nào đến rủi ro không nhất quán specification giữa hai tầng liền kề? Rắc rối sẽ xảy ra nếu compiler và phần mềm phía trên nó được chứng minh dựa trên các định nghĩa khác nhau về những gì cấu thành undefined behavior. Khi đó phần mềm phía trên có thể tuân thủ hành vi đã được định nghĩa theo tiêu chuẩn riêng của nó, nhưng một số hành vi đó có thể bị coi là undefined bởi compiler, cho phép nó hoạt động sai một cách tùy ý. Ví dụ, ứng dụng có thể giả định rằng việc đọc phần tử thứ 101 của một chuỗi có độ dài 100 sẽ trả về một giá trị mặc định an toàn nào đó, trong khi compiler lại coi hành vi đó là undefined và cho phép mình thực hiện các thay đổi tùy ý đối với bất kỳ mã nào phía sau lượt truy cập ngoài phạm vi đó – bao gồm cả việc loại bỏ các kiểm tra an toàn rõ ràng xuất hiện trong mã ứng dụng. Hơn nữa, chúng ta càng thêm nhiều tầng, chúng ta càng có nhiều cơ hội mắc phải các lỗi tương tự với interface inconsistency. Xem xét rằng việc tích lũy các tầng là một kỹ thuật then chốt để quản lý độ phức tạp trong kỹ thuật, sẽ thật đáng tiếc nếu tạo ra một rào cản chống lại nó.
Liệu những rủi ro này có làm tiêu tan toàn bộ dự án phối hợp formal verification giữa các phần khác nhau của một hệ thống?
End-to-End Verification Mang lại Hiệu quả
Không! Trên thực tế, việc thêm các tầng bổ sung ở cấp độ cao hơn hoặc thấp hơn thậm chí có thể giảm thiểu cơ hội xảy ra các sai sót specification không được phát hiện. Mức độ khai sáng tiếp theo là nhận ra rằng việc tích hợp các chứng minh của tất cả các tầng trong một hệ thống sẽ giúp chúng ta phát hiện ra tất cả các sự bất đồng specification có tính hệ quả. Vẫn có thể có lỗi trong các intermediate specifications, nhưng nếu chúng ta chứng minh được toàn bộ hệ thống, thì những lỗi còn sót lại đó hóa ra không ảnh hưởng đến các mục tiêu cấp cao nhất của chúng ta. Nếu có sự bất đồng specification đủ nghiêm trọng, thì hoặc là chứng minh của bên provider của abstraction đó sẽ thất bại từ phía dưới (ví dụ: một cam kết hoàn toàn không thực tế không thực sự được thực hiện trong mã), hoặc chứng minh của bên consumer sẽ thất bại từ phía trên (ví dụ: một giả định về tầng bên dưới quá yếu để cho phép chứng minh specification của tầng này). Một sơ đồ có thể giúp giải thích những gì xảy ra.

Các tầng trung gian của hệ thống đã trở thành untrusted theo nghĩa bảo mật máy tính, có nghĩa là các lỗi còn sót lại không thể làm hỏng các đảm bảo chính mà chúng ta hướng tới. Chúng ta không chỉ không tin tưởng vào các sản phẩm triển khai như compiler và CPU, mà chúng ta còn tránh tin tưởng vào specifications của ngôn ngữ lập trình hoặc tập lệnh phần cứng. Theo thuật ngữ toán học, chúng chỉ xuất hiện trong các lemmas được sử dụng để chứng minh định lý chính về toàn bộ stack. Nếu định lý đó được thông qua, chúng không có lỗi chí mạng trong các khía cạnh mà nó theo dõi (nhưng có thể ở các khía cạnh khác). Một kiểm toán viên hoài nghi thậm chí không cần phải đọc các specifications đó để bảo vệ chống lại việc vi phạm định lý cấp cao nhất.
Thông điệp quy trình rút ra ở đây là, khi thực hiện end-to-end verification cho một system stack trong một hệ thống chứng minh duy nhất, chỉ có các tầng specification trên cùng và dưới cùng là vẫn đáng tin cậy (trusted). Bằng cách này, chúng ta thường có thể formally verify các hệ thống toàn diện hơn với ít rủi ro misspecification hơn nhiều so với các hệ thống ít toàn diện hơn. Nhân tiện, quan điểm này được trình bày chi tiết hơn trong a position paper từ một dự án rộng lớn hơn mà tôi đã tham gia. Một khía cạnh quan trọng khác được đề cập trong bài báo đó, và tôi sẽ quay lại trong các bài viết sau, là giá trị của việc thực hiện tất cả các chứng minh trong một hệ thống hình thức và hệ sinh thái công cụ chung.
Những bài học này có thể khái quát hóa cho các vấn đề về recursively self-improving superintelligences. Thách thức trong việc xây dựng các top-level specifications chính xác cho các hệ thống vẫn sẽ tồn tại, nhưng chúng ta có thể tránh việc lo lắng về các phần nội bộ được đóng gói đúng cách. Bài viết tiếp theo sẽ chuyển sang một phản đối tiềm năng quan trọng: các computing stacks đã được formally verified với giả định có kiến thức hoàn hảo về các abstraction cấp thấp hơn mà chúng chạy trên đó, trong khi các tác nhân AI trong thế giới thực sẽ cần phải đối phó với sự không chắc chắn và thậm chí cả các nền tảng thù địch (adversarial platforms) mà chúng phải chạy trên đó.
This is definitely a post that's slightly easier for a 'layperson' to understand when compared to some of your other posts (at least for me, as I consider myself a layperson, who's only just starting to dip my toes into this entire field). The comparison to defining specifications being similar to asking a genie for a wish definitely captures the frustration of not getting things "just right".
I also find the use of lawyers fighting over undefined behavior particularly entertaining as well- I'd always thought of it as a grey area in uncharted territory where anything can happen, it's just up for the computer to decide what happens, which can include crashing your system (similar to your robot waiter crashing the dinner party).
Also, including your hardware/research projects in this context really gives it the appreciation that it deserves!