
Thiết kế các hệ thống ra quyết định để hỗ trợ việc tin tưởng câu trả lời của chúng
Nhược điểm của deep learning so với một người họ hàng không mấy phổ biến

Bài viết này là phần cuối cùng trong bộ ba bài đăng định vị deep learning về mặt điểm mạnh và điểm yếu, có liên quan đến việc xây dựng các hệ thống đáng tin cậy nhất cho việc tự động ra quyết định. Đánh giá tích cực của tôi là deep learning là sự khái quát hóa tự nhiên và mạnh mẽ của các công cụ tìm kiếm, hoạt động hiệu quả nhất khi chúng ta sử dụng nó để tìm kiếm và kết hợp các ví dụ trước đó có liên quan đến một mục tiêu. Đánh giá tiêu cực lớn đầu tiên của tôi là deep learning vốn có tốc độ chậm, do các yêu cầu mà nó tạo ra đối với việc nhiều bước tính toán phải diễn ra theo thứ tự. Giờ tôi sẽ kết thúc bằng việc xem xét các thách thức trong việc tin tưởng rằng các hệ thống được xây dựng trên deep learning (và một loạt các phong cách khác của machine learning) sẽ tạo ra các câu trả lời đáng tin cậy.
Từ Dữ liệu Huấn luyện đến các Tham số (Parameters)
Trước đó tôi đã gợi ý rằng deep learning được hiểu rõ hơn khi so sánh với các công cụ tìm kiếm thay vì các công cụ suy luận. Nó thường thành công tương ứng với khả năng tìm thấy các ví dụ mà nó đã biết có liên quan đến một yêu cầu. Tuy nhiên, nó không chỉ ghi nhớ các ví dụ. Chúng ta đã đề cập đến cách nó khái quát hóa việc giải tìm m và b trong phương trình y = mx + b từ lớp học đại số. Điểm khác biệt là thay vị chỉ có hai tham số đó, các mô hình nền tảng có thể có tới hàng trăm tỷ tham số (parameters) ngày nay!
Con dao hai lưỡi ở đây là, mặc dù rất nhiều thông tin hoặc thậm chí hiểu biết sâu sắc có thể được mã hóa trong vô số tham số như vậy, việc trích xuất cấu trúc (structure) từ các tham số đã học lại là một cuộc chiến gian nan, một rào cản đối với việc rút ra các đảm bảo toán học (mathematical guarantees). Sự theo đuổi chung này cho AI được gọi là explainability. Một trực giác tốt là khi các phương pháp huấn luyện học tham số không được thiết kế xung quanh cấu trúc có chủ ý, việc tìm kiếm cấu trúc (và do đó là các lời giải thích thuyết phục) sau khi sự việc đã xảy ra đòi hỏi nhiều công sức hơn.
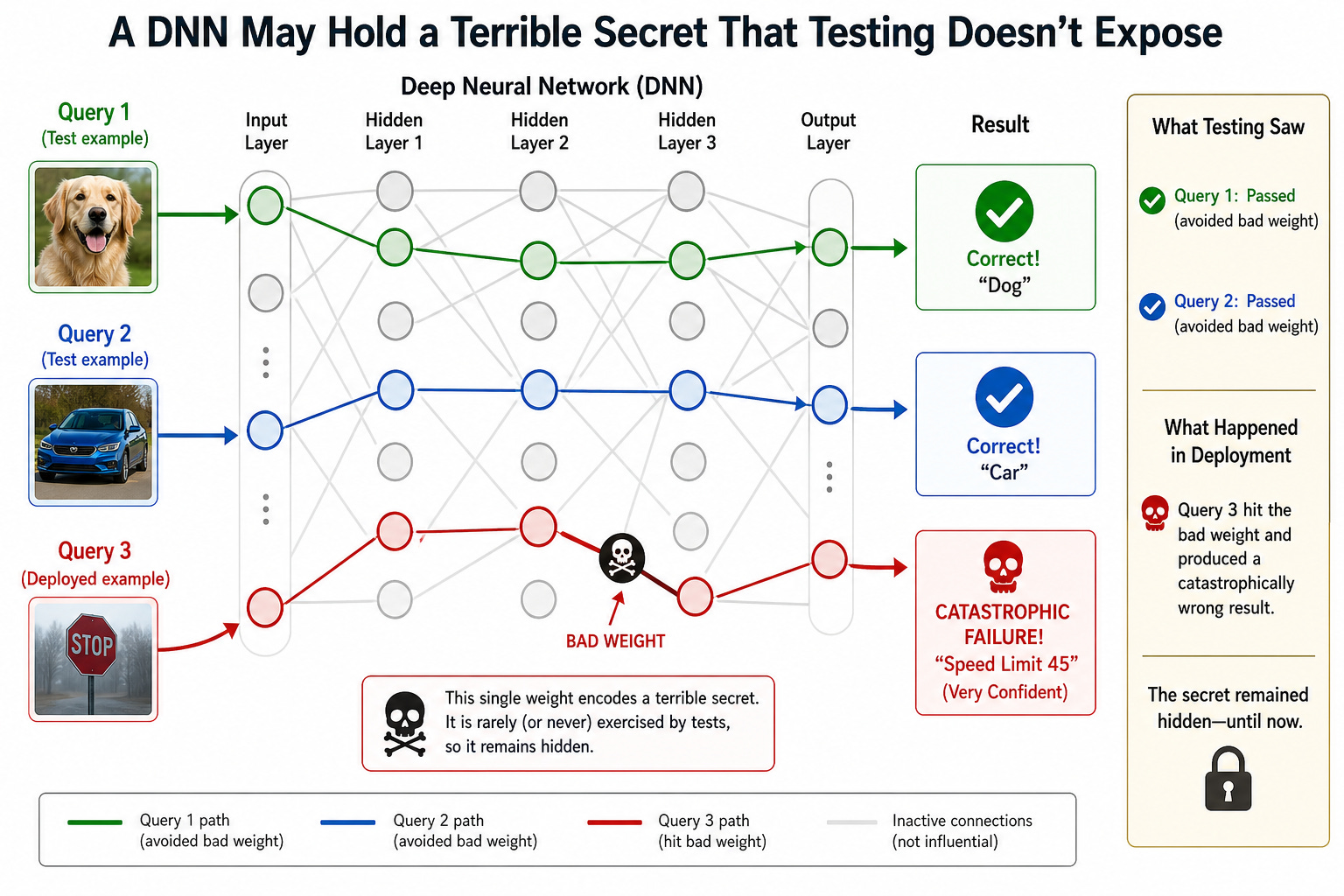
Một danh mục explainability cho deep learning phân tích xem phần nào của một prompt ảnh hưởng đáng kể đến câu trả lời cuối cùng. Loại phân tích này vốn không giải thích cách thức các phần có liên quan của câu hỏi cung cấp thông tin cho câu trả lời, nhưng nó là một điểm khởi đầu tốt. Tuy nhiên, phân tích như vậy phải chịu đựng các thách thức cổ điển của software testing: khi chúng ta chỉ đánh giá một chương trình trên một tập hợp đầu vào cụ thể, rất khó để xây dựng lòng tin về hành vi có thể xảy ra trên tất cả các đầu vào. Chúng ta có thể đã bỏ qua việc kiểm tra một corner case quan trọng trong một kịch bản quan trọng nào đó (hoặc thậm chí nhiều kịch bản thường xuyên xảy ra nằm ngoài trí tưởng tượng của chúng ta). Rủi ro đó đủ nghiêm trọng trong bối cảnh nơi tất cả người dùng đều có ý định tốt. Trong một bối cảnh cybersecurity nơi đối thủ đang cố gắng hết sức để thúc đẩy phần mềm thực hiện hành vi xấu, chúng ta phải giả định rằng đối thủ sẽ tìm thấy chính xác đầu vào kích hoạt hành vi tồi tệ nhất.
Trong một deep neural net, chúng ta có thể tưởng tượng các corner cases dưới dạng các trọng số (parameters) vốn ít ảnh hưởng đến các câu hỏi được đặt ra trong quá trình đánh giá nhưng lại hóa ra quan trọng đối với các câu hỏi quan trọng khác. Cho dù chúng ta có làm tốt việc giải thích phần nào của câu hỏi ảnh hưởng đến câu trả lời như thế nào đi nữa, chúng ta cũng không thể chắc chắn rằng các câu trả lời trong tương lai sẽ không có các lời giải thích có vấn đề và khá khác biệt. Ví dụ này được khơi nguồn cảm hứng bởi adversarial examples và backdoor attacks trong machine learning, nơi các thất bại thực tế sẽ liên quan đến việc nhiều trọng số bị lệch ở mức độ vừa phải, mặc dù trong sơ đồ tôi đơn giản hóa thành một trọng số có vấn đề duy nhất.
Tiếp tục tiến trình qua các kỹ thuật tương đương với các kỹ thuật chất lượng phần mềm cổ điển, chúng ta tìm thấy những tương đồng thú vị với compiler verification như tôi đã thảo luận trước đây. Với chủ đề về các compilers, tức các chương trình dịch thuật giữa các ngôn ngữ máy tính, mục tiêu là xác nhận rằng việc dịch thuật bảo toàn hành vi/ý nghĩa. Tôi đã giải thích rằng một phương pháp tiếp cận là certifying compilation, nơi mỗi lần chạy compiler không chỉ cho ra một chương trình dịch mà còn cả một chứng chỉ (certificate) thuộc loại nào đó chứng minh rằng việc dịch thuật đã được thực hiện chính xác. Một loại chứng chỉ rất linh hoạt là một chứng minh toán học (mathematical proof). Phong cách giải thích mang tính xác nhận (certifying explanation) đó hiện đang được nhiều nhóm nghiên cứu khám phá, không chỉ cho ứng dụng "hiển nhiên" của nó trong việc giúp AI làm toán mà còn trong việc giúp AI viết mã chính xác đi kèm với chứng minh tính chính xác. Nó vẫn là một phương pháp tiếp cận ngách ngày nay (ví dụ: không có cơ chế tương tự nào được áp dụng bởi LLMs để giải thích các phản hồi tùy ý), mặc dù một loạt các dự án có mục tiêu cụ thể hơn liên quan đến các khái niệm khác nhau về chứng chỉ và trình kiểm tra (checkers) của chúng.
Tôi có thể đưa ra một so sánh lấy nước Mỹ làm trung tâm cho bản chất của các chứng chỉ. Người đóng thuế ở Mỹ cần nộp tờ khai thuế (tax returns) hàng năm, nơi họ không chỉ tuyên bố họ nợ bao nhiêu tiền thuế mà còn trình bày, đôi khi cực kỳ chi tiết trên nhiều biểu mẫu, các tính toán chứng minh cho câu trả lời của họ. Một chứng chỉ giống như kiểu "thể hiện công việc của bạn" (showing your work) như vậy, tham chiếu đến các quy tắc cơ học thay vì luật thuế của Hoa Kỳ. Một tờ khai thuế nhất định chỉ tác động đến một phần rất nhỏ của toàn bộ luật thuế, cho phép kiểm toán tương đối rẻ đối với bất kỳ tờ khai thuế nào, mặc dù việc tìm kiếm chiến lược khai thuế lý tưởng của người đóng thuế có thể khám phá nhiều phần của luật mà hóa ra không liên quan (nghĩa là, một số có thể được sử dụng nhưng không theo những cách làm giảm số thuế phải nộp).
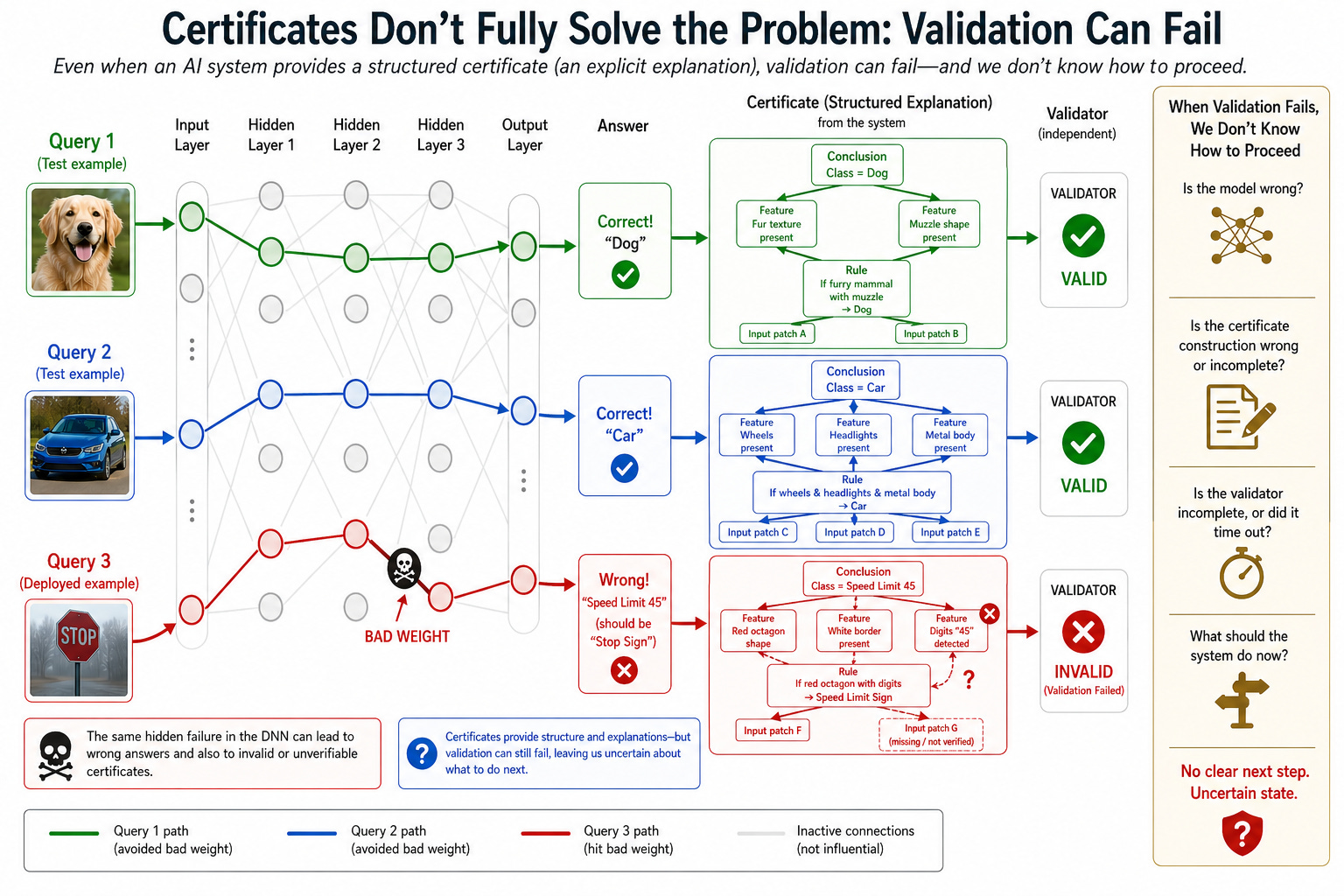
Sơ đồ sau đây cho thấy cách một khuyết tật duy nhất trong mô hình dẫn đến cả câu trả lời sai và lỗ hổng trong chứng chỉ. Trình kiểm tra (checker) gắn cờ lỗ hổng giúp chúng ta tránh tiếp tục với câu trả lời sai, mặc dù theo cách khiến chúng ta không có giải pháp thay thế rõ ràng.
Tôi cũng nên đề cập ngắn gọn đến các kỹ thuật liên quan đến LLM được gọi là chain-of-thought, nơi các mô hình được hướng dẫn thông qua việc trình bày chi tiết các bước trung gian để tìm ra câu trả lời của chúng; và self-consistency, tạo ra nhiều chuỗi suy nghĩ (chains of thought) và chọn câu trả lời xuất hiện thường xuyên nhất làm "người chiến thắng". Trong chừng mực các kỹ thuật này viết ngôn ngữ tự nhiên và vẫn phụ thuộc vào các biến số ngẫu nhiên của LLM, chúng vẫn không giúp tạo ra các đảm bảo mạnh mẽ. Các biến thể sử dụng ngôn ngữ hình thức hội tụ về phía tạo ra các chứng minh hình thức.
Các certifying algorithms (và chúng ta có thể xem chain-of-thought như một trường hợp đặc biệt) có những điểm mạnh và điểm yếu chung. Điểm mạnh chính là việc chứng minh một câu trả lời duy nhất là chính xác thường dễ dàng hơn nhiều so với việc chứng minh rằng một hệ thống chỉ luôn đưa ra các câu trả lời chính xác. Lợi ích này có thể chuyển dịch thành chi phí kỹ thuật thấp hơn để xây dựng một công cụ ra quyết định. Một điểm yếu đối trọng là khả năng cố hữu dẫn đến những bất ngờ không mong muốn: một lần chạy cụ thể của certifying algorithm cuối cùng có thể đưa ra một chứng chỉ không hợp lệ (invalid), vốn thất bại trong việc kiểm tra độc lập. Ví dụ, một chứng chỉ có thể là một chứng minh toán học được thực hiện qua một loạt các bước, và một trong các bước đó hóa ra không tuân theo các suy luận trước đó. Khi đó người dùng phải làm gì? Kết quả thực tế không khác gì việc chương trình ra quyết định chạy vô tận hoặc bị sập, cả hai điều này đều không mang lại trải nghiệm tốt cho người dùng. Hệ thống kết thúc ở một trạng thái không xác định, không thể đưa ra câu trả lời. Xem xét AI một cách rộng rãi, không phải lúc nào chúng ta cũng có một hành động mặc định an toàn để thực hiện khi một công cụ quyết định không đưa ra được đề xuất. Ví dụ, chúng ta có thể đang điều khiển một phương tiện hàng không trong thời tiết phức tạp, phụ thuộc vào việc ra quyết định thông minh liên tục để tránh việc thực sự rơi. Trong những bối cảnh đó, việc rơi vào trạng thái không xác định chính là một sự thất bại.
Đối với nhiều khái niệm hợp lý về chứng chỉ, vẫn chưa rõ liệu deep learning có phát triển để tạo ra chúng hay không, đối với các vấn đề đủ phức tạp và mới lạ. Đôi khi việc tìm kiếm chứng chỉ chính là phần khó nhất, ví dụ như tìm kiếm các chứng minh cho các giả thuyết toán học lâu đời. Ngay cả khi deep learning có thể được mở rộng quy mô để tạo ra một loại chứng chỉ nhất định, việc làm đó có thể mất nhiều thời gian đến mức không hợp lý. Ví dụ, một nâng cấp dễ dàng cho một công cụ như vậy là thêm một vòng lặp kiểm tra các chứng chỉ đầu ra, khởi động lại hệ thống mỗi khi quá trình kiểm tra thất bại (có lẽ với prompt mới về những gì đã xảy ra sai sót lần trước, để giúp tránh lặp lại). Trong trường hợp xấu nhất, một hệ thống như vậy sẽ chạy vô tận trên các đầu vào đủ khó. Ngay cả khi cuối cùng nó tìm thấy một câu trả lời có thể chứng thực, chi phí tính toán có thể dễ dàng tăng vọt với cách tiếp cận này, và các chi phí thử lại này nên được coi là một trường hợp đặc biệt của những gì tôi đã nhấn mạnh trong bài đăng trước về cách các "agentic loops" cấp cao có thể dẫn đến sự chậm trễ rất lớn trong việc đưa ra câu trả lời cuối cùng. Ví dụ trước đây của chúng ta về phần mềm điều khiển cho phương tiện hàng không là một ví dụ tốt, nơi chúng ta không thể chấp nhận sự chậm trễ kéo dài lẫn việc quay lại các cài đặt mặc định đơn giản; và không khó để tìm thấy các lĩnh vực khác nơi các câu trả lời chuyên biệt nhanh hơn ít nhất cũng cung cấp giá trị kinh tế rõ ràng.
Khái niệm đối ứng từ compiler verification là các certified compilers, nơi một chứng minh toán học chỉ ra rằng một compiler hoạt động đúng cách cho tất cả các đầu vào khả dĩ. Việc xây dựng một chứng minh như vậy có thể khó hơn nhiều, nhưng nó giúp chúng ta không phải lo lắng về những bất ngờ không mong muốn trên các đầu vào mới. Compiler verification có một sự tương đồng khá tốt với mechanistic interpretability cho AI, nghiên cứu đảo ngược (reverse-engineers) các mô hình machine-learning thành các lời giải thích có ý nghĩa với con người, nhưng các nền tảng của lĩnh vực này vẫn đang được thiết lập. Trong thời gian này, chúng ta cũng có thể tự hỏi về việc các phương pháp tiếp cận ra quyết định khác phù hợp hơn thế nào với các rào chắn bảo vệ đã được chứng minh.
Mục tiêu của chúng ta sẽ là tránh hoàn toàn nhu cầu phát hiện các lỗi suy luận sau khi chúng xảy ra. Thay vào đó, chúng ta muốn tận dụng cấu trúc hệ thống để làm cho các lỗi suy luận trở nên không thể xảy ra.
Good Old-Fashioned AI
Deep learning và những họ hàng gần nhất của nó đối lập với good old-fashioned AI (GOFAI), một cái tên vui nhộn dành cho symbolic AI. Bất kể chúng ta gọi nó là gì, phương pháp tiếp cận lâu đời này tập trung vào formal logic và các phương pháp symbolic khác để biểu diễn suy luận, giống như phong cách chúng ta thường dùng để giải các bài toán trên bảng đen. Một phong cách đặc biệt có tầm ảnh hưởng là expert systems, áp dụng các quy tắc logic đặc thù cho từng lĩnh vực (domain-specific logical rules) để giải quyết các bài toán mới. Hóa ra phong cách đó có thể tránh được các thách thức chúng ta vừa khảo sát xung quanh việc bị mắc kẹt trong các trạng thái không xác định hoặc phải đối mặt với việc kiểm tra câu trả lời tốn kém. Bạn có thể đã nghe nói về việc các hệ thống dựa trên quy tắc (rule-based systems) ngày nay đã lỗi thời đến mức nào, và chúng ta sẽ quay lại lịch sử tai tiếng đó, nhưng trước tiên hãy để tôi xem xét loại công nghệ mà chúng ta đang nói đến. Các bài đăng sau sẽ đi sâu vào các phát triển có liên quan và thú vị kể từ khi các expert systems không còn được ưa chuộng, bao gồm những tiến bộ trong công cụ lập trình và phần cứng, cộng với cơ hội tận dụng statistical machine learning ở những nơi mà điểm yếu của nó ít liên quan hơn.
Loại expert system này dựa trên các quy tắc suy luận ra các sự thật mới từ các sự thật đã biết. Ví dụ, dưới đây là một tập hợp các quy tắc có thể được áp dụng bởi các nhà đầu tư mạo hiểm (venture capitalists) để quyết định mức định giá cho các AI startups.
RULE: Add $1M to the valuation for every occurrence of the word "agentic" in the pitch deck.
RULE: If person P has a LinkedIn profile that lists employment at company C, then consider that P worked for C.
RULE: If a cofounder has worked at a major AI company, add $5M to the valuation.
RULE: If the product has probability R of destroying humanity, add $10M/(1 - R) to the valuation.Để chạy một logic program như vậy, chúng ta có thể bắt đầu với một tập hợp các sự thật đã biết (như nội dung hồ sơ LinkedIn của các nhà đồng sáng lập) và tiếp tục suy diễn các sự thật mới thông qua các quy tắc của chúng ta cho đến khi không còn sự thật nào được rút ra nữa. Cuối cùng, chúng ta cộng dồn tất cả số tiền lũy tiến đã được suy diễn ra.
Có thấy ngay cách một phương pháp tiếp cận explainability đơn giản hơn áp dụng cho loại hệ thống suy luận này. Mọi quy tắc đều có thể được xem xét kỹ lưỡng bởi các chuyên gia trước khi triển khai hệ thống. Trong thực tế, các quy tắc sẽ được viết bằng một ngôn ngữ lập trình nào đó thay vì tiếng Anh, để tránh tối đa sự mơ hồ tiềm ẩn. Các ký hiệu của formal logic thường được sử dụng. Tuy nhiên, phần mô tả ở trên về cách một người thực thi một logic program một cách "hiển nhiên" hoạt động khá tốt để giải thích cách thức hoạt động thực tế của nó.
Một cách để tin tưởng đầu ra của một rule-based system là làm theo cách của certifying compilers: yêu cầu mỗi lần thực thi xuất ra một vết (trace) về cách các quy tắc được sử dụng để đi đến kết luận. Ví dụ tôi đã sử dụng ở đây có phần phức tạp không cần thiết từ góc nhìn này, nhưng hãy đơn giản hóa bằng cách nói (1) mục tiêu của hệ thống là chứng thực một mức định giá tối thiểu cho một startup, và (2) giả định chúng ta không có quy tắc nào cộng thêm các khoản tiền âm vào bảng tổng sắp. Khi đó, một chứng chỉ là một danh sách các rule instances: mỗi phần tử là một quy tắc từ knowledge base, cùng với một trace bổ sung cho mỗi quy tắc, giải thích cách chúng ta suy diễn ra các tiền đề (premises) của nó. Ví dụ, chúng ta có thể chứng minh việc sử dụng quy tắc về nhà đồng sáng lập từ công ty AI lớn bằng cách đưa vào một trace chứng minh rằng nhà đồng sáng lập đó từng làm việc cho một công ty cụ thể. Trace lồng nhau đó tự nó có thể gọi một quy tắc khác và cần bao gồm các traces tiếp theo, nhưng cuối cùng quá trình này sẽ kết thúc bằng việc chỉ tham chiếu đến các sự thật mà chúng ta giả định là đúng. Điểm mấu chốt là, trong khi việc đưa ra kết luận và tạo ra trace của nó nói chung có thể phức tạp, thì việc kiểm tra một trace lại đơn giản và rẻ.
Câu chuyện khá tương tự với những gì chúng ta đã xem xét cho chuyên ngành của riêng tôi là formal verification và các ứng dụng của nó vào recursive self-improvement và code-sharing bởi các tác nhân (agents). Thật vậy, formal verification, bao gồm cả automated theorem proving, là một ví dụ về lĩnh vực đã thành công đến mức bị đưa ra khỏi quan niệm phổ biến về "AI", tuân theo câu châm ngôn cũ rằng danh mục "AI" chỉ bao gồm các nhiệm vụ suy luận có vẻ như chưa được giải quyết đầy đủ ở hiện tại.
Nghĩ lại cuộc thảo luận của chúng ta về các nút thắt cổ chai hiệu năng cố hữu của deep learning, chúng ta có thể thấy một lợi thế hấp dẫn cho các rule-based systems bên cạnh tính explainability. Một nguyên tắc chính mà chúng ta dựa vào là latency, hay thời gian để có được câu trả lời hoàn chỉnh cho một câu hỏi, tỷ lệ thuận với độ dài đường găng (critical path) của một hệ thống, đo lường chuỗi các bước dài nhất nhất thiết phải xảy ra theo thứ tự. Một số kết luận của một rule-based system có thể được chứng minh bằng các traces nông (shallow traces), nghĩa là chúng ta không cần sử dụng các quy tắc mà tiền đề của chúng được chứng minh bằng các quy tắc mà tiền đề của chúng lại kêu gọi các quy tắc... đến một độ sâu quá cực đoan. Về nguyên tắc, với một bản cài đặt song song tốt, critical path được quyết định bởi độ sâu của trace. Nói cách khác, các câu trả lời với các chứng minh nông sẽ có thể được tìm thấy nhanh chóng, đi kèm với bằng chứng thuyết phục cho tính đúng đắn của chúng. Cùng một expert system đó vẫn có thể sẵn sàng chạy lâu hơn cho các câu hỏi phức tạp hơn, tốn thời gian tỷ lệ thuận với độ phức tạp đó.
Một Phương pháp Bị Mất Uy tín?
Bây giờ tôi có thể quay lại đối mặt với việc các expert systems đã lỗi thời hoàn toàn như thế nào. Một giai đoạn mùa đông AI (AI winter) bắt đầu vào những năm 1980 tập trung vào sự vỡ mộng đối với các expert systems. Sau đó, chúng ta có một thời kỳ mà hầu như tất cả các phương pháp tiếp cận AI đều bị nhìn nhận với sự hoài nghi, tiếp theo là sự bùng nổ của deep learning vào những năm 2010, đưa các expert systems vào thế bất lợi tương đối lớn hơn nữa trong trí tưởng tượng phổ biến. Có lẽ tôi nên cảm thấy e ngại khi tiết lộ sự thật về blog này: một chủ đề chính sẽ là lập luận ngày càng thuyết phục cho việc quay trở lại phong cách ra quyết định tự động này (đôi khi có sự hợp tác với các kỹ thuật khác như deep learning). Có hai trở ngại lớn rõ ràng trên con đường đạt được kết quả tốt.
Thứ nhất, đã có sự đầu tư full-stack khổng lồ vào deep learning và các kỹ thuật liên quan, khiến các đối thủ cạnh tranh có khá nhiều việc phải làm để đuổi kịp. Hãy cân nhắc:
Công việc nền tảng về thuật toán trong lĩnh vực này
Các thiết bị tăng tốc phần cứng AI (AI hardware accelerators) như GPUs, cũng như các công cụ lập trình bổ sung cho chúng, cùng nhau cung cấp hiệu năng song song tuyệt vời
Sự phân bổ rộng rãi kiến thức chuyên môn trong loại hình tính toán này
Sự quen thuộc thậm chí còn rộng rãi hơn với cách đạt được kết quả tốt khi tạo prompt cho các hệ thống generative-AI
Thứ hai, statistical machine learning đã chỉ ra các kết quả đáng kinh ngạc trong rất nhiều lĩnh vực mà các phương pháp tiếp cận dựa trên logic symbolic đã bị đình trệ. Nếu chúng ta lấy mẫu ngẫu nhiên các nhóm đối tượng như người dùng doanh nghiệp về các vấn đề quan trọng nhất của họ nơi họ muốn có sự trợ giúp từ trí tuệ nhân tạo, chúng ta chủ yếu nhận được các câu trả lời mà generative AI đang dẫn trước rất xa so với các phương pháp khác hiện nay. Gánh nặng chứng minh đè lên vai những người thúc đẩy một phương pháp tiếp cận khác, để chỉ ra cách nó có thể cạnh tranh được.
Tôi sẽ thực hiện thử nghiệm lập luận đầu tiên cho luận điểm đó trong bài đăng tiếp theo của mình. Điểm mấu chốt là phóng tầm mắt ra xa và áp dụng phương pháp tiếp cận codesign, nhìn xa hơn các phạm vi thông thường mà các bài toán AI được định nghĩa. Các bài đăng sau sẽ quay lại với kỹ nghệ hiệu năng (performance engineering) của toàn bộ các computing stacks cho các hệ thống dựa trên logic symbolic.