
Codesign cho Legibility (đối với AI và tất cả những đối tượng khác)
Đôi khi tất cả những gì cần làm chỉ là thay đổi thế giới.

Vài bài viết trước đã đề cập đến việc mặc dù các ý tưởng dòng chính (mainstream) hiện nay trong generative AI có những khả năng phi thường trong việc tìm kiếm các tập dữ liệu lớn, chúng lại có những nhược điểm nghiêm trọng ở cả thời gian phản hồi câu trả lời lẫn độ tin cậy của các câu trả lời đó. Việc kỳ vọng các phương pháp tiếp cận sẽ nằm trên một dải đánh đổi (trade-off) là điều tự nhiên, và nếu một phương pháp nào đó trở nên phổ biến, nó phải đạt điểm số rất tốt ở ít nhất là tốc độ hoặc độ tin cậy của câu trả lời, vì vậy có thể ngạc nhiên khi phong cách thống trị hiện nay lại gặp vấn đề ở cả hai khía cạnh này. Tôi đã bắt đầu lập luận ngắn gọn rằng các phương pháp dựa trên logic và mang tính symbolic hơn hứa hẹn sẽ giải quyết cả hai khiếu nại trên. Vậy tại sao những phương pháp như vậy vẫn chưa thống trị thế giới?
Câu trả lời trực tiếp là, cho đến nay, chúng đã thể hiện chất lượng câu trả lời kém hơn rõ rệt trên hầu hết các bài toán được quan tâm nhiều hiện nay. Nếu chúng ta thực hiện một cuộc khảo sát nhanh về các ứng dụng phổ biến của AI, chúng ta sẽ thấy deep learning và các công nghệ liên quan vượt xa ở mỗi ứng dụng. Nhưng liệu bản tóm tắt đó có thực sự ngụ ý rằng tương lai sẽ tập trung vào statistical machine learning không? Tôi sẽ trình bày một hệ thống khung thay thế (alternative framework) chứng minh cho câu trả lời là "không", mặc dù trước tiên tôi muốn tóm tắt một hệ thống khung dòng chính thống hơn.
Predictive Coding
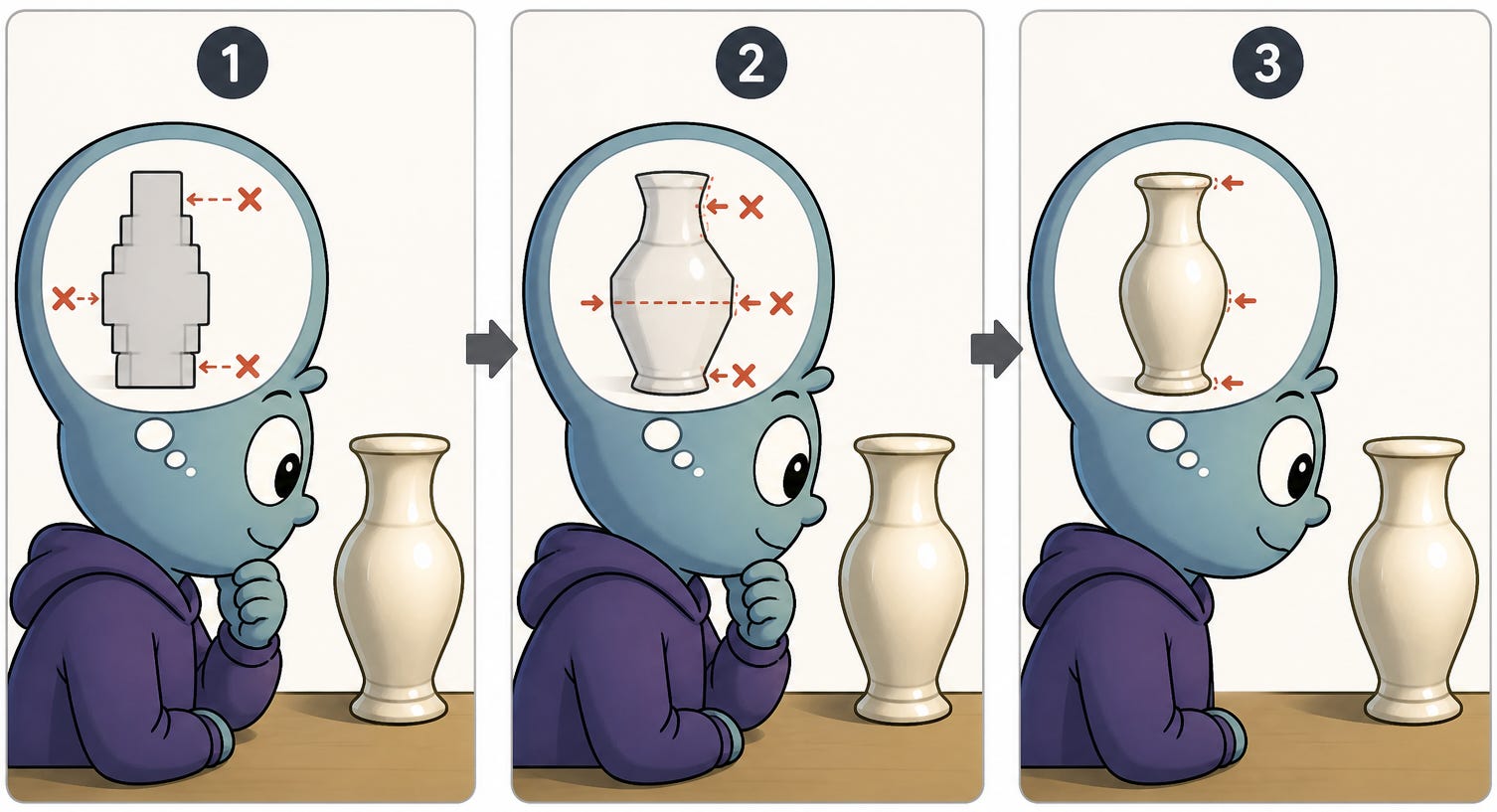
Predictive coding là một lý thuyết về trí tuệ khá phổ biến đối với những người suy nghĩ về các hệ thống AI mạnh mẽ. Nói một cách đại khái, lý thuyết predictive coding khuyến khích chúng ta vượt ra ngoài các mô hình đơn giản giả định rằng các giác quan của chúng ta cảm nhận trực tiếp sự thật khách quan của thế giới. Thay vào đó, bộ não của chúng ta cần phát triển các models nội bộ khá chi tiết về thế giới, và chúng ta chỉ có thể tích hợp các đầu vào giác quan đối với các models này, tìm xem trạng thái thế giới tương thích với mô hình nào khớp nhất với các đầu vào đó. Khi chúng ta nhận thấy kết quả xấu từ các models hiện tại của mình, chúng ta sẽ cập nhật chúng bằng cách xem xét chi tiết những gì xảy ra sai sót, rất giống với cách huấn luyện các mô hình deep-learning hoạt động với backpropagation để đảo ngược các quyết định không chính xác thành các thay đổi phù hợp cho các tham số mô hình.
Sơ đồ này cho thấy ý tưởng cơ bản trong một learning loop. Người quan sát tinh chỉnh thế giới quan (world model) của mình để giúp anh ta nhận biết một chiếc bình tốt hơn. Những trường hợp mô hình đưa ra dự đoán sai lệch so với dữ liệu đầu vào mới sẽ kích hoạt các sửa đổi đối với mô hình.
Tại sao chúng ta lại thấy mình trong các tình huống mà việc mô hình hóa các hiện tượng được quan tâm là rất thách thức? Tôi sẽ tập trung vào một dạng cơ chế rộng lớn: khi các hiện tượng đó được tạo ra bởi các quá trình tiến hóa không tối ưu hóa cho tính dễ hiểu (legibility). Nghĩa là, một số quá trình tiến hóa cung cấp phản hồi cho các thiết kế trung gian, nhưng nó không phạt các thiết kế khó hiểu.
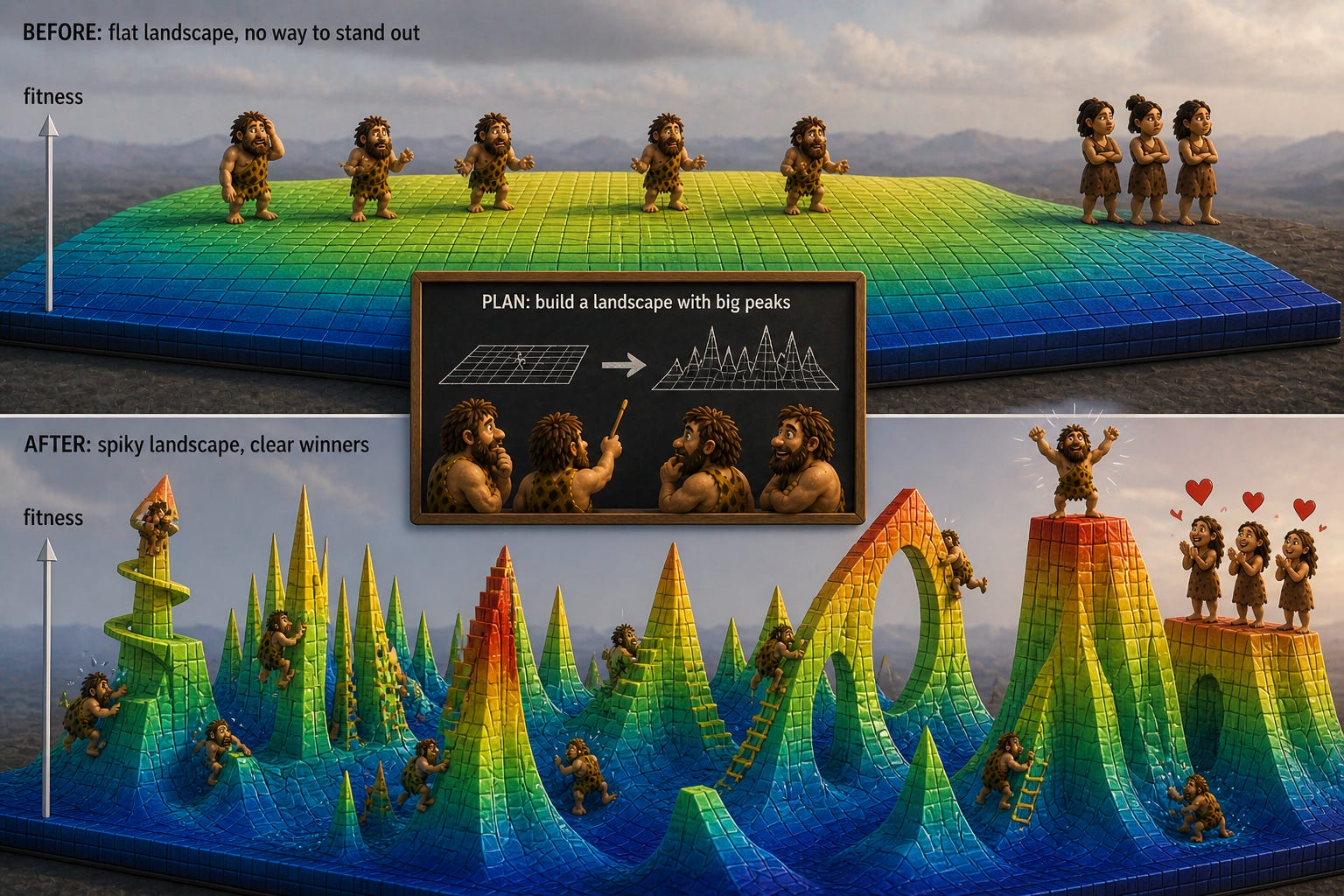
Ngay cả khi chúng ta tối ưu hóa một cách rõ ràng cho legibility, chúng ta vẫn có thể thấy quá trình tiến hóa bị mắc kẹt trong các tối ưu cục bộ (local optima). Lý do là vì quá trình tiến hóa tiến triển thông qua những thay đổi nhỏ, mỗi thay đổi trong đó cần cải thiện fitness theo ít nhất một cách nhỏ nào đó, nếu không biến thể đó sẽ bị loại bỏ. Có thể tồn tại các thiết kế lại dễ hiểu hơn một cách đáng kể nhưng lại không thể đạt được thông qua các chuỗi bước nhỏ vốn đều cải thiện legibility và/hoặc bất kỳ mục tiêu nào khác. (Có thể chúng ta tìm thấy một con đường tăng dần legibility nhưng lại làm giảm tính thực tiễn trong thế giới thực ở các điểm trung gian, mặc dù tính thực tiễn sẽ tăng vọt vào cuối con đường.)

Đây không chỉ là vấn đề của tiến hóa sinh học. Chúng ta cũng có thể thấy nó trong các hệ thống được thiết kế có chủ đích, thông qua việc nhìn nhận chính chúng ta như một hệ thống phân tán để tìm kiếm các ý tưởng kỹ thuật tốt hơn. Tôi đã viết trước đây về signaling như một tối ưu hóa cho các hệ thống như vậy, nơi các thành viên cố gắng thể hiện phẩm chất fitness vốn bị ẩn giấu của họ thông qua các màn trình diễn tốn kém, nhằm cung cấp tín hiệu sớm giúp thuật toán tối ưu hóa cắt tỉa các nhánh không triển vọng. Sự hiện diện của signaling thực chất có thể dẫn đến việc tối ưu hóa (các phần của) hệ thống cho legibility kém hơn, nhằm tạo cơ hội cho việc thể hiện năng lực một cách phóng đại.
Kết quả là chúng ta hoàn toàn có thể kết thúc với một loạt các bài toán AI kinh điển có vẻ như, xét theo kiến thức hiện tại của chúng ta, mang độ phức tạp không thể giảm bớt (irreducibly complex): nơi chỉ có loại mô hình lớn, không có cấu trúc được tạo ra bởi deep learning mới có thể mang lại các quyết định đủ tốt. Chúng ta thậm chí có thể lấy gợi ý từ Kolmogorov complexity và định nghĩa độ phức tạp của một bài toán theo độ thái của mô hình ngắn nhất hiểu rõ bài toán đó. Các mô hình nền tảng mới nhất được mô tả với hàng nghìn tỷ (terabits) trọng số – trong đó "tera" có nghĩa là 10 mũ 12. Một mặt, chúng ta có thể ăn mừng thành tựu kỹ thuật của việc huấn luyện các mô hình có cấu trúc phức tạp tương đối tự do như vậy và nhận ra rằng các mô tả phức tạp có thể là cần thiết để hiểu một loạt các hiện tượng quan trọng. Ở mặt khác, các mô hình phức tạp hơn có xu hướng đắt đỏ hơn để tìm kiếm và thực thi. Điểm chung của cả predictive coding và thực hành machine learning là việc học thông qua các vòng lặp có xu hướng làm tăng độ phức tạp: khi một mô hình được khớp ngày càng tốt hơn với một hiện tượng bên dưới, mô hình sẽ trở nên phức tạp hơn, hoặc nó hội tụ đến kết quả tốt hơn vì vốn đã có độ phức tạp cố hữu trong kiến trúc của nó ngay từ đầu. Điều gì sẽ xảy ra nếu chúng ta mở rộng các vòng lặp đó sao cho chúng cũng có thể bao gồm các bước được thiết kế để giảm độ phức tạp?
Codesign cho Legibility
Ngày nay, phần lớn mọi người đều coi đó là điều hiển nhiên rằng cách để tiến bộ đối mặt với các bài toán suy luận đầy thách thức là cải thiện các hệ thống AI. Tuy nhiên, một kỹ thuật khác có thể còn mạnh mẽ hơn: thay đổi các bài toán để dễ giải quyết hơn. Các bài toán đã được sửa đổi có thể phù hợp hơn cho các phương pháp tiếp cận AI có thuộc tính vượt trội về tốc độ và độ tin cậy. Các hệ thống dựa trên quy tắc cổ điển (classical rule-based systems) không chỉ tận dụng cấu trúc logic được định nghĩa rõ ràng khi nó tồn tại; chúng thường cũng thất bại hoàn toàn trong các lĩnh vực mà cấu trúc đó không được biết đến. Liệu chúng ta có thể thiết kế lại các hệ thống ở cấp độ cao hơn để giúp cấu trúc đó trở nên rõ ràng không?
Tôi đã viết trước đây về codesign với ví dụ về các phương tiện tự hành. Ý tưởng rộng lớn hơn là chúng ta có thể làm cho các bài toán AI trở nên đơn giản hơn bằng cách thay đổi bối cảnh mà chúng hoạt động. Sử dụng ý tưởng đó, chúng ta có thể lấy thế giới của một learning loop trong predictive-coding và chuyển đổi nó thành một codesign loop xen kẽ giữa các bước học hỏi và thay đổi thế giới đang được học, với mục tiêu cải thiện legibility, hay sự dễ dàng trong việc học hỏi.
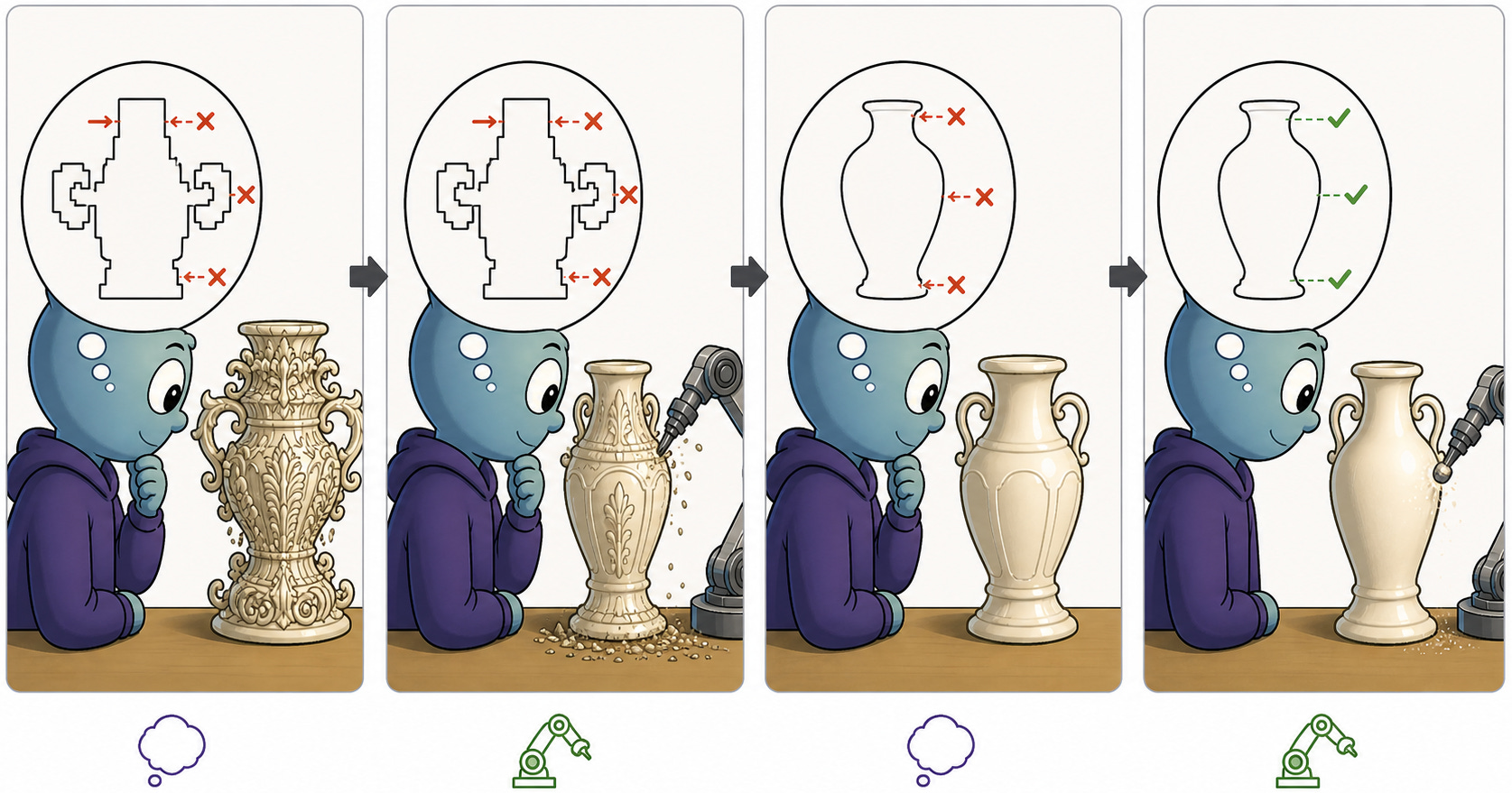
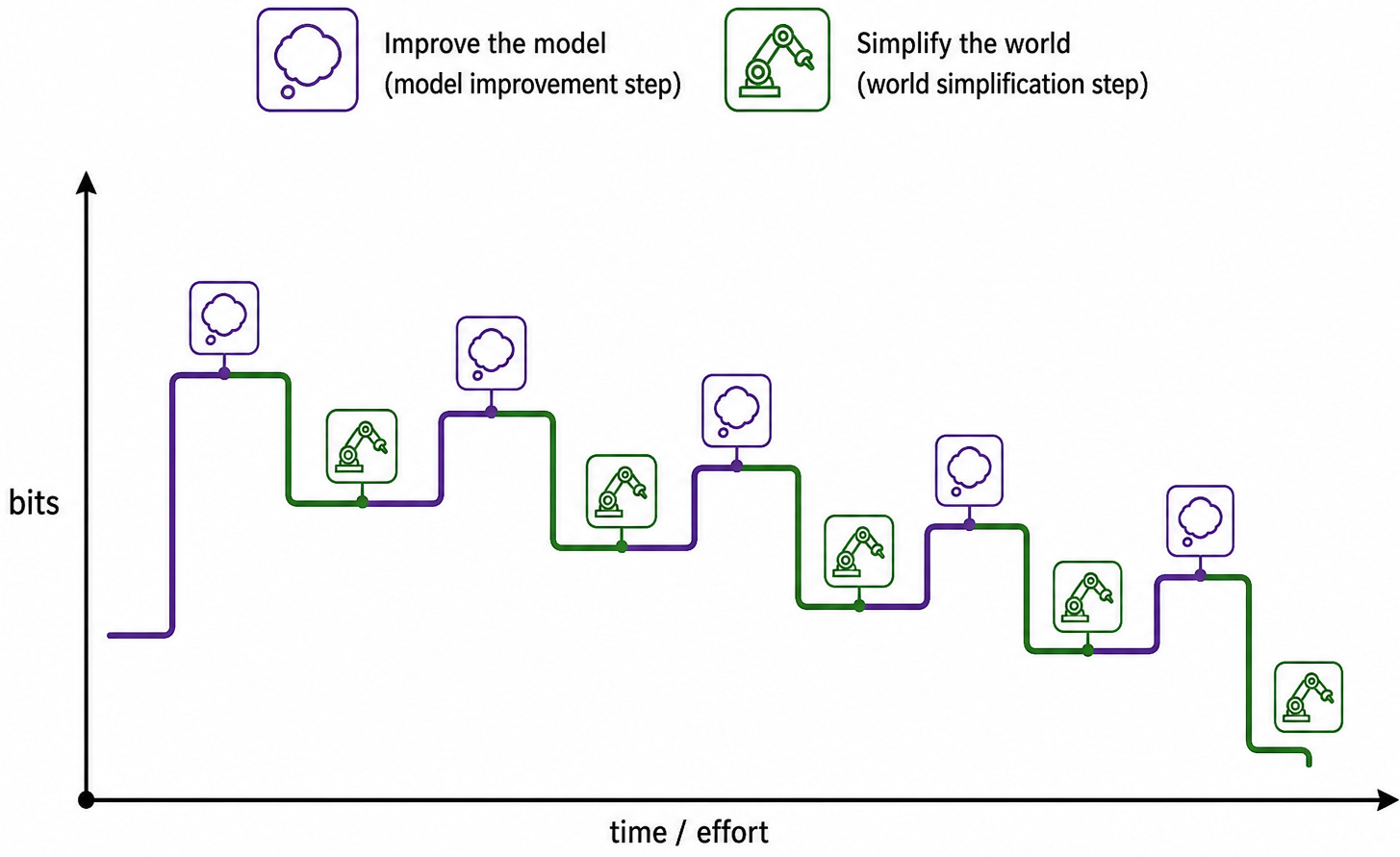
Quay lại ý tưởng đo lường độ phức tạp theo số lượng bit cần thiết để mô tả thế giới, giờ đây chúng ta đang kết hợp các bước tinh chỉnh mô hình, vốn thực sự có thể kết hợp thêm các bit bổ sung; và các bước đơn giản hóa thế giới, vốn thực sự làm giảm độ phức tạp của các mô hình hiệu quả khi được áp dụng đúng cách. Khung lập luận này gợi ý một góc nhìn rất khác so với việc tôn vinh kỹ thuật cho phép học nhiều bit. Thay vào đó, chúng ta thấy tiến bộ đến từ việc thay đổi thế giới để yêu cầu càng ít bit mô tả càng tốt. Sự nén kiến thức như vậy đến từ cấu trúc khớp tốt với thế giới, từ đó có thể hỗ trợ các đảm bảo (guarantees) rõ ràng. Biểu đồ cách điệu tiếp theo này cho thấy cách xen kẽ các loại thay đổi này giúp chúng ta kéo độ phức tạp mô tả xuống dưới. Ngay cả sau khi đầu tư vào các mô hình phức tạp hơn, chúng ta vẫn có thể tìm thấy các con đường quay lại sự đơn giản, được định hướng bởi những gì có thể giúp ích cho các mô hình, thông qua việc đơn giản hóa thế giới.
Từ góc nhìn này, chúng ta nên thay đổi thế giới để loại bỏ các bài toán AI đầy thách thức càng nhiều càng tốt, được định hướng bởi kinh nghiệm xây dựng các thế hệ hệ thống trước đó. Dưới đây là một vài ví dụ về các cơ hội thuộc loại này, hầu hết trong số đó tôi đã đề cập trong các bài đăng trước, nơi tôi nhấn mạnh các ví dụ về động lực tiến hóa dẫn đến các môi trường khó khăn hơn mức cần thiết cho các tác nhân thông minh. Mỗi ví dụ xác định một bài toán khó liên quan đến AI và tìm cách thay thế nó bằng một giải pháp thay thế có cấu trúc tốt hơn giúp hợp lý hóa việc tự động hóa. Tôi sẽ trình bày các đề xuất này theo thứ tự tăng dần về mức độ gây tranh cãi hoặc nỗ lực để tái cấu trúc thế giới.
Một ví dụ tốt đã được áp dụng rộng rãi trong kỹ nghệ phần mềm. Các web applications đầu tiên được thiết kế chỉ để con người sử dụng trực tiếp với các trình duyệt GUIs. Tuy nhiên, rất nhanh sau đó, một số người dùng muốn các chương trình thay mặt họ truy cập các web applications. Các nỗ lực ban đầu liên quan đến các phương pháp kỹ thuật không mấy dễ chịu như scraping, đòi hỏi phần mềm phải hiểu cả ngôn ngữ tự nhiên và bố cục trực quan. Cuối cùng, chủ sở hữu của nhiều web applications đã bắt đầu cung cấp các web APIs, cách tiếp cận các dịch vụ tương tự theo những phương thức thân thiện hơn với việc hiểu tự động, đòi hỏi phải giải quyết chính xác không một vấn đề nào được coi là "AI".
Lập trình phần mềm là một lĩnh vực mà chúng ta nắm quyền kiểm soát, với việc con người đã chủ động thiết kế các ngôn ngữ lập trình và các công cụ khác. Các ngôn ngữ lập trình luôn được thiết kế để làm cho các chương trình dễ hiểu hơn đối với con người, mặc dù quán tính thói quen vẫn để lại một số ý tưởng thiết kế tồi. Thậm chí có một số hoạt động signaling đang diễn ra, nơi các nhà thiết kế ngôn ngữ đôi khi đưa vào các yếu tố phức tạp vì chúng tạo ra các câu đố mà các lập trình viên thích giải quyết. Thay vì bám víu vào các ngôn ngữ tình cờ có nhiều ví dụ xuất hiện trong các đợt chạy huấn luyện LLM lớn đầu tiên, chúng ta nên thay đổi cách thức lập trình hoạt động để AI dễ dàng phát hiện lỗi hơn và các khía cạnh tương tự.
Chúng ta nên thay đổi môi trường mà các phương tiện tự hành sinh sống để đơn giản hóa tầm nhìn và các vấn đề khác liên quan đến việc kiểm soát hiệu quả. Thay vì những con đường đầy rẫy các hiện tượng không thể dự đoán trước, trong một số bối cảnh, một mô hình giống như đường hầm tàu điện ngầm sẽ phù hợp hơn. Mạng lưới đường bộ ngày nay được tiến hóa với suy nghĩ về những người lái xe con người, không xem xét các khả năng tiết kiệm chi phí thông qua tiêu chuẩn hóa và đơn giản hóa.
Bây giờ dần dần tăng tiến về tính chất suy đoán của các đề xuất, việc chuyển rời khỏi việc sử dụng ngôn ngữ tự nhiên sẽ đơn giản hóa nhiều bài toán liên quan. Khi nhiều phần của nền kinh tế bị chi phối bởi các AI agents, chúng sẽ có các lựa chọn bên cạnh ngôn ngữ tự nhiên để phối hợp với nhau. Ngôn ngữ tự nhiên là các cỗ máy ọp ẹp được định hình bởi các quá trình tiến hóa vốn không lựa chọn mạnh mẽ cho sự thiếu mơ hồ hay tính đơn giản của việc xử lý. Trên thực tế, signaling thúc đẩy việc hướng tới ngôn ngữ phức tạp hơn có thể được sử dụng để phô diễn khả năng nhận thức. Các giao thức truyền thông của các AI agents không cần phải duy trì bất kỳ hành trang (baggage) nào như vậy. (Thực ra, ví dụ trước về việc áp dụng các web APIs là một trường hợp ban đầu của nguyên tắc này được giảm thiểu vào thực tế rất hiệu quả!)
Tôi không thể cưỡng lại việc đưa ra thêm một ý tưởng khá mang tính suy đoán, điều mà bạn có thể chấp nhận hoặc bỏ qua một cách độc lập với việc tin vào hệ thống khung codesign rộng lớn này. Sinh học đầy rẫy những bí ẩn, những thứ bí ẩn đối với bộ não nhỏ bé của chúng ta bởi vì, ngoại trừ một ngoại lệ nhỏ có thể xảy ra trong quá khứ gần đây nhất, chưa từng có áp lực tiến hóa nào đối với các sinh vật để chúng có thể hiểu được cơ chế hoạt động của chính mình. Chúng ta có thể tiếp tục nghiên cứu reverse-engineering các cơ chế tiến hóa của mình, nhưng về lâu dài có thể thấy kết quả tốt hơn từ việc thay thế các bộ phận của chính chúng ta. Ví dụ, các cơ quan thay thế nhân tạo có thể tuân theo các thực hành kỹ thuật tốt nhất và dễ hiểu cũng như tối ưu hóa hơn các cơ quan tự nhiên.
Phương pháp chung, về một vòng lặp cải tiến kết hợp giữa học tập và sửa đổi hiện tượng cần học, là một vũ khí bí mật chưa được đánh giá đúng mức trên con đường hướng tới các hệ thống thông minh hiệu quả. Chúng ta đang xem xét từ "hệ thống" theo nghĩa rộng giữ cho các ví dụ codesign ở trên nằm trong phạm vi.
Hệ quả đối với Việc Tự động Hiểu Khả thi
Có thể các bài toán AI kinh điển ngày nay đòi hỏi việc học các hàm toán học có vẻ như có độ phức tạp không thể giảm bớt, khiến các phương pháp dựa trên logic về cơ bản không thể áp dụng được. Tuy nhiên, bằng cách thay đổi thế giới sao cho nó bộc lộ các bài toán quyết định khác nhau, chúng ta có thể làm cho suy luận dựa trên logic trở nên cạnh tranh. Bằng cách mang lại cho thế giới cấu trúc dễ hiểu (legible structure), chúng ta kích hoạt các phương pháp vốn phát triển mạnh mẽ dựa trên cấu trúc, có tiềm năng tận hưởng các lợi ích cho cả hiệu năng cũng như tính có thể giải thích (explainability) và các đảm bảo toán học một cách rộng rãi. Hai trong số các danh mục lớn cho các bài đăng sắp tới là (1) các chi tiết cụ thể hơn về việc thế giới có thể và nên khác biệt như thế nào để hỗ trợ suy luận tự động hiệu quả và (2) kiến trúc đúng đắn của các hệ thống suy luận đó nhằm tận dụng cấu trúc, xem xét trên toàn bộ stack phần cứng và phần mềm. Việc đi theo các hướng này sẽ đưa chúng ta đi theo một hướng khá khác biệt so với sự đồng thuận của ngành công nghiệp.