
Sự hư cấu đắt đỏ của các Low-Level Programming Languages
Các AI coding tools đang đối mặt với một trở ngại lớn khi sử dụng các ngôn ngữ phổ biến.

Tôi đã và đang chia sẻ một phần câu chuyện về tương lai với các trustworthy search processes giúp tự động hóa software development. Nếu ban đầu chúng ta có một formal specification rõ ràng và đủ cụ thể, thì recursive self-improvement có thể tiến hành theo cách đảm bảo đồng nhất với các mục tiêu của chúng ta. Tôi đã thảo luận về một số lý do để lạc quan trên phương diện đó, bao gồm các bài học từ việc sử dụng formal verification gần đây (để kết nối các phần đã được xác thực lại với nhau và dự đoán các mối đe dọa bảo mật mới) và suy đoán về những thay đổi trong một nền kinh tế bị chi phối bởi các AI agents (đơn giản hóa user interfaces and requirements gathering). Điểm nghi ngờ đầu tiên về ý tưởng này thường là về thách thức trong việc viết các specifications như vậy. Vẫn còn rất nhiều thách thức trong việc xây dựng các specifications tốt cho các hệ thống có năng lực cao, nhưng bây giờ hãy để tôi chuyển sang các thách thức tiếp theo, những thách thức nảy sinh sau khi các specifications đã được viết xong.
Chúng ta hãy xem xét nói chung vấn đề về automatic generation of code from its specification. Nhiều AI coding assistants đang được sử dụng ngày nay để viết code theo kiểu “best effort” (nỗ lực tốt nhất), trong đó kết quả có thể chứa các lỗi khiến chương trình được tạo ra không tuân theo specification của nó. Tôi quan tâm nhất (và các bài đăng trong tương lai sẽ thường xuyên thảo luận nhất) đến các phương pháp correct by construction, trong đó một công cụ có thể bỏ cuộc nhưng sẽ không bao giờ trả về một chương trình không chính xác. Một cách tiếp cận đặc biệt thú vị là structured search qua space of programs, sử dụng formal verification như một fitness function để đánh giá các biến thể chương trình trung gian và cuối cùng.
Bất kể cách tiếp cận nào được thực hiện đối với automatic programming, chúng ta đều phải đối mặt với những mong muốn xung đột nhau, một mặt là đơn giản hóa space of programs và cách chúng ta tự động suy luận về nó; và mặt khác là tạo ra các chương trình có chất lượng cao nhất ở cuối cùng. Khó khăn là các chương trình chất lượng cao hơn có thể dài hơn và phức tạp hơn so với các chương trình chất lượng thấp hơn, đòi hỏi quá trình tìm kiếm tốn kém hơn để phát hiện. Một yếu tố quyết định quan trọng đến tính hiệu quả của việc tìm kiếm là lựa chọn programming language. Tuyên bố chính của tôi trong bài đăng này là các programming languages được sử dụng rộng rãi không phù hợp cho kiểu tìm kiếm này, đặc biệt là khi chúng ta cố gắng viết các high-performance programs – điều này sẽ xảy ra khi chúng ta nghĩ về một program-search system tự cải thiện đệ quy, dựa trên lượng thời gian và không gian mà một tìm kiếm phức tạp có thể chiếm dụng. Để lập luận cho tuyên bố này, tôi sẽ bắt đầu bằng cách nêu chi tiết một framework chung cho program search, sau đó tôi sẽ thu hút sự chú ý vào một ngách sinh thái còn thiếu trong framework đó đang bị các programming languages phổ biến bỏ bê.
Tìm kiếm trong Space of Programs
Hãy để tôi mô tả ở một cấp độ rất cao quá trình tinh chỉnh dần dần một specification thành một chương trình cuối cùng. Có thể cho rằng, các software engineers là con người làm việc theo cách này, và chúng ta có thể kỳ vọng sẽ ngày càng phụ thuộc vào các chương trình tự động hóa quy trình đó. Có một truyền thống trong computer science giúp chính thức hóa các ý tưởng này, được gọi là derivation by stepwise refinement, nhưng tôi sẽ để mọi thứ diễn ra một cách không chính thức ở đây. Chúng ta có thể nghĩ về việc khám phá như di chuyển từ đỉnh của mô tả sơ đồ sau xuống đáy.

Các cấp độ cao nhất của biểu đồ xử lý các ký hiệu tương đối trừu tượng và do đó cho phép hầu hết các chức năng được bao quát bằng các mô tả ngắn nhất. Các cấp độ thấp nhất gần hơn với computer hardware mà chúng ta dự định chạy trên đó, và chúng yêu cầu các chi tiết phải được trình bày hết sức cặn kẽ.
Mỗi node của tìm kiếm này là một chương trình trong một programming language nào đó. Mỗi ngôn ngữ chúng ta chọn nên mang lại lợi ích về khả năng thực thi của việc tìm kiếm, khả năng kiểm soát các chi tiết của chương trình cuối cùng, hoặc cả hai. Mô hình đơn giản nhất là chúng ta bắt đầu chọn các ngôn ngữ thiên về đơn giản hóa việc tìm kiếm và cuối cùng chuyển sang các ngôn ngữ cung cấp khả năng kiểm soát ở mức độ thấp, mặc dù việc kết hợp các lợi ích xuyên suốt cũng rất tốt. Bất kể thế nào, đó sẽ là một dấu hiệu cảnh báo nếu chúng ta làm việc với một ngôn ngữ đạt điểm kém trên cả hai trục… tuy nhiên tôi sẽ tuyên bố rằng ngày nay, AI code generation đang làm việc áp đảo với các ngôn ngữ như vậy.
Low-Level Programming Languages
Chúng ta hãy nghĩ cụ thể về các ngôn ngữ phù hợp cho các cấp độ thấp hơn của quá trình tìm kiếm. Một software engineer rất tận tâm có thể làm việc trực tiếp với assembly language, hình thức lập trình ở cấp độ gần như thấp nhất được thực hiện ngày nay. Tuy nhiên, phổ biến hơn nhiều là dừng lại ở một programming language như C, được phát minh vào những năm 1970 và đã ảnh hưởng sâu sắc đến thiết kế của các ngôn ngữ cấp thấp. Chính xác hơn, các ngôn ngữ như vậy nhằm cho phép kiểm soát chi tiết cách một chương trình sử dụng các tài nguyên hardware sẵn có và đạt được hiệu suất tốt nhất.
Đã có rất nhiều đổi mới tuyệt vời gần đây trong không gian programming languages này. Có lẽ câu chuyện thành công lớn nhất là ngôn ngữ Rust, bổ sung thêm việc kiểm tra theo kiểu formal verification để đảm bảo các chương trình tuân theo các quy tắc an toàn. Ngược lại, C nổi tiếng với việc các lập trình viên dễ dàng đưa vào các lỗi làm tổn hại đến tính an toàn và bảo mật. Các quy tắc an toàn này không đảm bảo rằng chương trình thực hiện chính xác những gì chúng ta muốn, nhưng các formal-verification tools như Verus and Prusti bổ sung loại kiểm tra đó. Bản thân là một người cuồng formal-methods, tôi sẽ không hài lòng cho đến khi một số phương pháp verification như vậy được coi là một phần của language definition, và các chương trình thất bại trong verification bị coi là không hợp lệ. Tuy nhiên, trong phần còn lại của bài đăng này, tôi muốn tập trung vào một trục khác của thiết kế ngôn ngữ.
Vấn đề là các ngôn ngữ trong danh mục này nhằm cung cấp khả năng kiểm soát hiệu suất chi tiết và hiệu quả. Tôi muốn lập luận rằng các ngôn ngữ cấp cao hơn hầu như luôn dễ chịu hơn khi sử dụng để triển khai các chương trình mà hiệu suất không quan trọng; chúng ta chỉ chọn một ngôn ngữ như C hoặc Rust để cho phép chúng ta tinh chỉnh hiệu suất. Các Lisp machines đã cung cấp một stack tuyệt vời để phát triển tất cả code trong một ngôn ngữ cấp cao thống nhất, và chúng “chỉ” thiếu các khả năng hiệu suất để bắt kịp với các xu hướng khác trong hardware! Vấn đề là C được thiết kế cho hardware của những năm 1970 và chưa được cập nhật cho các hướng đi mà thế giới máy tính đang hướng tới, với việc kết thúc của định luật Moore buộc chúng ta phải khéo léo hơn trong cách sắp xếp tính toán. Do đó, họ ngôn ngữ này được thiết kế để khớp vừa vặn với hardware model của những năm 1970 nhưng thất bại trong việc phơi bày các tính năng cần thiết để có được hiệu suất mở rộng tốt ngày nay. C, Rust và những người bạn quá low-level để trở thành các ngôn ngữ cấp cao thân thiện với lập trình viên, và chúng cũng quá high-level để phơi bày hộp công cụ thực sự của tối ưu hóa hiệu suất. (Nếu chúng ta bị kẹt với hardware cố định cụ thể, thì C và Rust có thể cung cấp cho các lập trình viên hầu như tất cả các nút điều khiển hiệu suất mà họ có sẵn, nhưng chúng ta nên nghĩ lớn hơn và codesign hardware mới cùng với các programming tools của nó.)
Khoảng cách và Giao tiếp
Computer hardware luôn đóng vai trò trung gian giữa thế giới vật lý và các abstractions tốt đẹp cho việc lập trình, nhưng loại lớp trung gian “kỳ diệu” đó đã gặp khó khăn trong việc mở rộng. Thực tế là tính toán diễn ra trong không gian ba chiều, nhưng hãy đơn giản hóa xuống không gian hai chiều cho mục đích của bài đăng blog này (mặc dù các công nghệ chip ba chiều đang ngày càng phổ biến). Khi đó chúng ta có một biển các nodes trải rộng trong không gian, và hãy giả sử mỗi node đại diện cho tính toán hoặc lưu trữ.
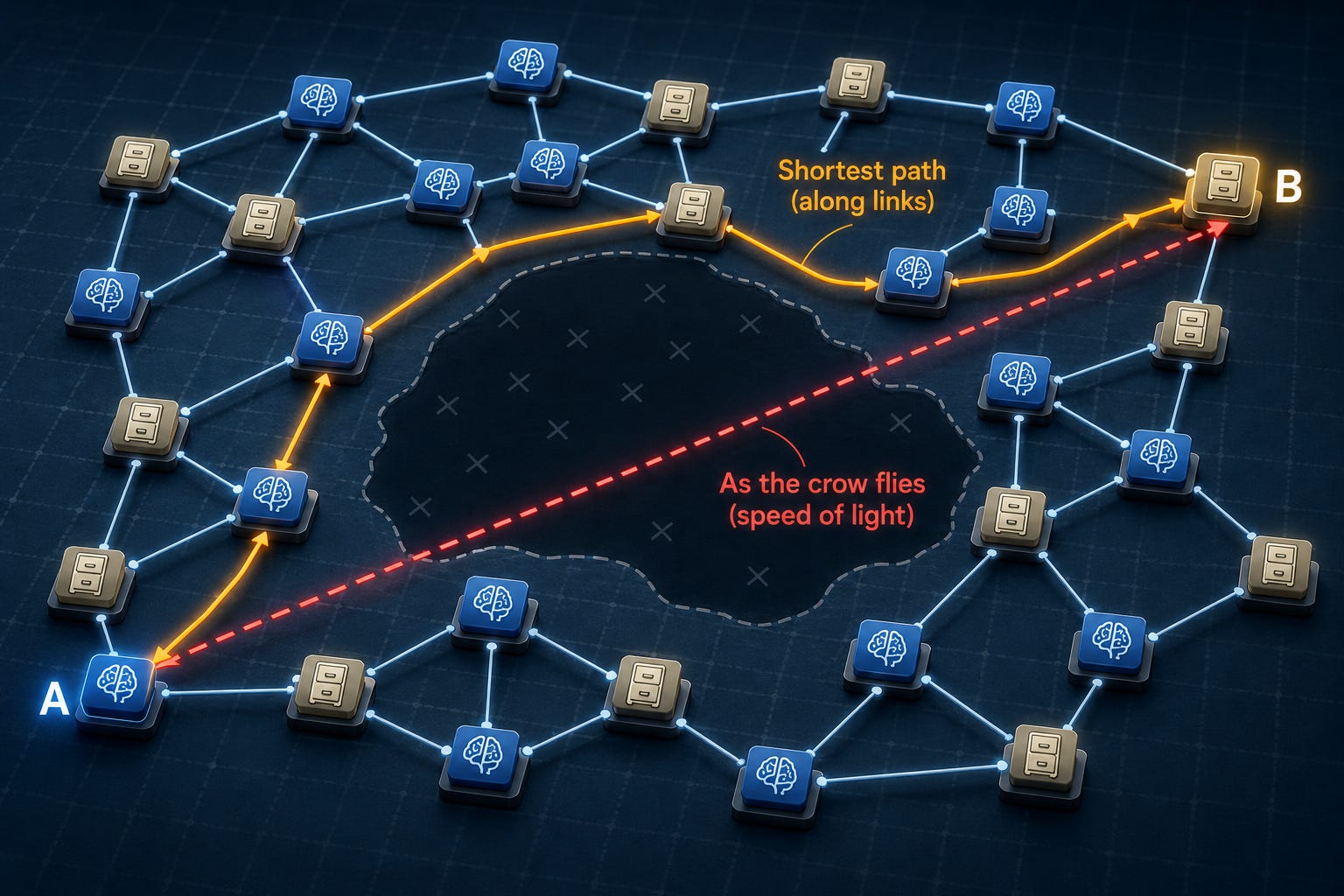
Một số cặp nodes được kết nối bằng dây dẫn, và thông thường tín hiệu chỉ truyền dọc theo các dây dẫn đó. (Wireless communication tạo ra quá nhiều overhead khiến nó không khả thi ở quy mô mà chúng ta đang nói đến ở đây.) Bởi vì có chi phí sản xuất cho mỗi dây dẫn, tương đối ít các kết nối trực tiếp tiềm năng giữa các nodes được xây dựng. Kết quả là, con đường nhanh nhất giữa hai nodes có thể đi theo một tuyến đường khá gián tiếp, trái ngược với con đường hình học trực tiếp nhất ở giữa bức tranh. Tuy nhiên, con đường trực tiếp đó thiết lập một loại giới hạn tốc độ cơ bản cho giao tiếp giữa một cặp node, thường được gọi là “giới hạn tốc độ ánh sáng” khi chúng ta giả định tín hiệu truyền đi với tốc độ tối đa có thể.
Tôi đã thảo luận về một phiên bản đơn giản hóa của loại hệ thống này trước đây trong bối cảnh về các giới hạn hiệu suất cơ bản của deep learning. Ở đó điểm mấu chốt là một hệ thống deep learning có thể được coi là một computation graph (hệ thống các nodes và các cạnh giữa chúng), với các cạnh đại diện cho các mối quan hệ đầu vào-đầu ra. Việc tính toán câu trả lời cuối cùng đòi hỏi phải tính toán giá trị của tất cả các nodes, việc này sẽ tốn ít nhất là bằng thời gian của con đường dài nhất tồn tại trong graph, một số đo quan trọng gọi là critical-path length. Khi các hệ thống mở rộng, overhead giao tiếp của việc truyền tín hiệu dọc theo các dây dẫn thường chiếm ưu thế trong tổng thời gian thực thi, và thiếu sót lớn trong C, Rust và các họ hàng của chúng là programming model che giấu các overhead giao tiếp này và các khía cạnh của cấu trúc chương trình giúp chúng có thể dự đoán và kiểm soát được.
Lập trình low-level programming truyền thống sống trong một thế giới tưởng tượng lệch khỏi thực tế theo hai cách lớn. Hai điều lớn này cũng đã được trình bày trong bài viết của Chisnall “C Is Not a Low-level Language”, và điểm bổ sung mà tôi muốn nhấn mạnh là những tưởng tượng này khiến việc đánh giá hiệu suất của một chương trình trở nên khó khăn hơn, điều này làm cho việc program search hiệu quả trở nên khó khăn hơn.
Chúng ta giả vờ rằng code trông giống như các chuỗi lệnh chạy từng cái một. Trong thực tế, tất cả các phần của một cấu trúc tính toán vật lý luôn luôn “running.” Hardware như các CPUs cố gắng hết sức để thúc đẩy utilization (sự sử dụng), tỷ lệ các nodes làm công việc hữu ích tại một thời điểm nào đó, nhưng nó chỉ có thể đi xa đến thế, thiết kế ngược cấu trúc của code về cơ bản là sequential ngay cả khi các câu hỏi hành vi liên quan là undecidable.
Chúng ta giả vờ rằng có một bộ nhớ chia sẻ lớn duy nhất mà tất cả các phần của chương trình đều truy cập. Đúng vậy, abstraction này được xây dựng một cách kỳ công bởi hardware, nhưng chúng ta không thể nghĩ về nó với một cost model ngây thơ. Thời gian để truy cập một vị trí bộ nhớ tại một computation node cụ thể có thể thay đổi đáng kể dựa trên nhiều yếu tố khác nhau, và cùng một node có thể trải qua thời gian truy cập rất khác nhau cho cùng một vị trí bộ nhớ tại các thời điểm khác nhau. Các nguyên tắc đằng sau việc dự đoán các yếu tố hiệu suất này quy về việc theo dõi locality of memory references, một khái niệm không may thường đòi hỏi tư duy global (toàn cục), nghĩa là việc hiểu hiệu suất của một phần hệ thống có thể yêu cầu theo dõi chi tiết hành vi của các phần khác. Ngoài ra, chúng ta có thể sử dụng các abstractions đã được thiết lập sẵn như MPI tiết lộ trực tiếp hơn sơ đồ hardware, nhưng các hệ thống này cũng bị coi là cực kỳ low-level và khó lập trình.
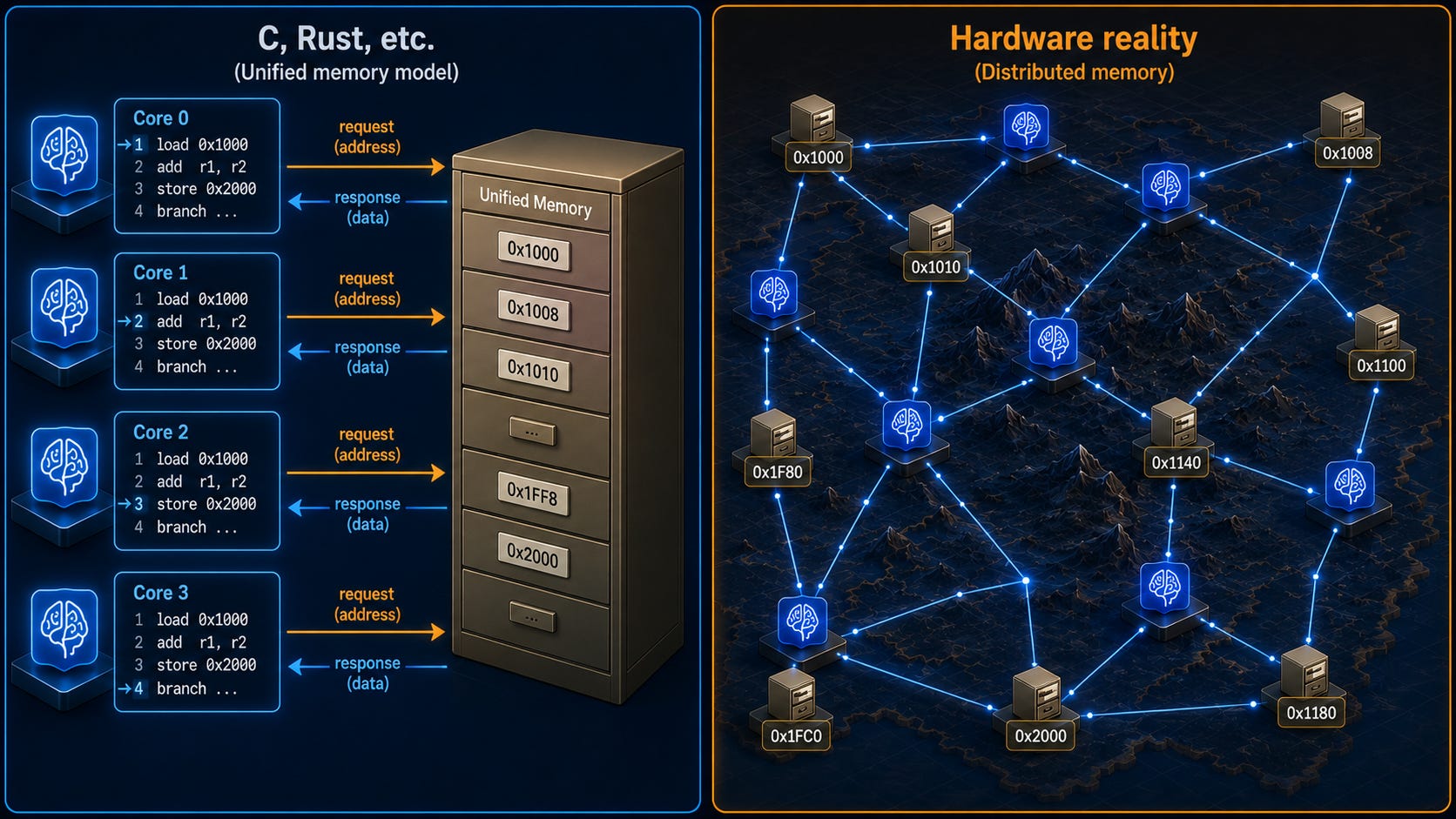
Một abstraction của sequential code execution là hữu ích cho bộ não con người bé nhỏ để theo kịp trong việc hiểu một chương trình, nhưng nó chỉ là quá xa vời thực tế để lý tưởng cho việc phân tích hiệu suất có khả năng mở rộng. Các low-level programming languages thường bắt đầu từ các tính năng sequential programming và cung cấp các tính năng bổ sung để giải thích cách một số chương trình như vậy nên chạy cùng một lúc. Việc các bản triển khai ngôn ngữ không thể hiểu những gì đang xảy ra bên trong các đơn vị parallelism khiến việc thực hiện các sắp xếp lại code quan trọng một cách tự động dưới dạng tối ưu hóa trở nên khó khăn hơn.
Các kỹ sư hiệu suất tinh hoa nhất có thể ghi nhớ cấu trúc của các nền tảng hardware cụ thể để nhìn vào các chương trình software thông thường và “thấy” chúng sẽ tốn bao nhiêu chi phí để chạy. Tuy nhiên, các chi tiết phức tạp đến mức cản trở việc tìm kiếm tự động thông qua các biến thể chương trình để tìm ra những biến thể có hiệu suất tốt nhất. Quan trọng là, cấp độ mô hình hóa hiệu suất này dường như đòi hỏi phải nghĩ về các chương trình ở một cấp độ abstraction rất thấp, hầu như không che giấu bất kỳ điều gì về tổ chức hardware. Ở cấp độ abstraction đó, ngay cả những cải tiến nghe có vẻ đơn giản cũng có thể yêu cầu thay đổi đối với nhiều dòng code, có thể lan rộng khắp một cơ sở code lớn, và nhiều heuristics tìm kiếm không bao giờ có thể thực hiện được cấp độ sửa đổi đồng bộ đó. (Một ví dụ về việc sửa đổi không cục bộ như vậy là đưa vào một data structure mới yêu cầu một coordination protocol mới cho các shared-memory accesses bởi tất cả các phần của code liên quan đến data structure đó.)
Kết luận
Dù chúng ta đang nghĩ về các software engineers con người thiết kế và triển khai một chương trình hay về AI search thông qua một space of programs để hiện thực hóa một specification, hai thuộc tính đặc biệt hữu ích trong các ký hiệu chúng ta sử dụng để đại diện cho các chương trình đang được xem xét. Một số ký hiệu cho phép chúng ta mô tả các hệ thống phức tạp một cách cô đọng, và những ký hiệu đó thuận tiện để hiểu và thao tác bằng đại số. Một số ký hiệu khác cung cấp cho chúng ta quyền kiểm soát để mô tả từng chi tiết cuối cùng của việc khai thác hardware để đạt hiệu suất tối đa. Rắc rối với các mainstream programming languages như C và Rust là chúng thể hiện những khuyết điểm lớn đối với cả hai mục tiêu. Ngay cả những người ủng hộ các ngôn ngữ đó thường đồng ý rằng sự đơn giản của lập trình bị hy sinh để đổi lấy quyền kiểm soát, khiến việc hiểu tự động về các chương trình và hành vi của chúng (về mặt hiệu suất hoặc mặt khác) là bất khả thi về mặt hình thức, mặc dù các nguyên tắc cấu trúc bổ sung như của Rust có thể giúp ích. Nhưng khi đó performance model của code chỉ là ngầm định, do khoảng cách lớn giữa thực tế của hardware và sự hư cấu của các phần của chương trình chạy sequential code và truy cập vào một shared global memory.
Có đủ các phần của lập luận này cũng như bằng chứng và hậu quả của nó để tôi tiếp tục trong ba bài viết tiếp theo. Đầu tiên, tôi sẽ giải thích nỗ lực phi thường của các CPUs hiện đại để trình bày programming abstraction kiểu C trong khi thể hiện hành vi hiệu suất rất mơ hồ. Tiếp theo, tôi sẽ đề xuất sự hội tụ giữa phong cách lập trình của software và hardware như một nguyên tắc thống nhất để vạch ra một lộ trình tốt hơn. Cuối cùng, tôi sẽ đề cập đến GPUs như một ví dụ về phương pháp tiếp cận đã phát triển gần hơn với lý tưởng này nhưng vẫn giữ lại một số điểm yếu thực sự liên quan đến việc tạo ra trustworthy decision systems, chủ đề bao trùm của blog này. Việc thiết lập nền tảng với các chi tiết này sẽ chuẩn bị cho chúng ta khám phá thêm về khẩu hiệu tổng thể của chúng ta rằng “trí thông minh phụ thuộc vào việc tổ chức tính toán một cách chính xác và hiệu quả.”