
Tại sao các Software Requirements trở nên dễ dàng hơn trong một nền kinh tế AI
Các Abstraction boundaries mang lại lợi ích

Về mặt nguyên tắc, một trong những biện pháp bảo vệ tốt nhất chống lại việc các hệ thống AI đi chệch hướng trong quá trình recursive self-improvement là formal verification, nơi chúng ta chứng minh bằng toán học rằng các hệ thống đáp ứng các yêu cầu chính thức. Một trở ngại tự nhiên là việc phải đảm bảo viết ra đủ chi tiết các quy tắc chúng ta muốn thực thi, những mô tả như vậy được gọi là specifications. Vai trò ngày càng tăng của AI trong nền kinh tế, một mặt, có thể làm tăng số lượng hệ thống máy tính mà việc thực thi nghiêm ngặt các quy tắc là vô cùng quan trọng. Tuy nhiên, có một khía cạnh, có lẽ là trớ trêu, trong đó việc chỉ ra các quy tắc đúng đắn, tức là viết các formal specifications tốt, lại trở nên dễ dàng hơn. Tôi đã lập luận rằng, khi AI phổ biến, việc thiết kế nền kinh tế để bao gồm các bong bóng nơi AI chỉ tương tác với các AI khác là hoàn toàn hợp lý, và tôi đã phác thảo cách mà việc specifying user interfaces khi đó trở nên dễ dàng hơn.
Bây giờ tôi sẽ chứng minh rằng thách thức rộng hơn trong việc thống nhất các system requirements cũng trở nên dễ dàng hơn về mặt cơ bản. Lợi thế cốt lõi đến từ việc ý định của ai cần được chính thức hóa trong các yêu cầu. Thu thập các yêu cầu từ con người có thể khó khăn vô cùng, nhưng điều gì sẽ xảy ra khi nguồn của các yêu cầu mới chủ yếu là các chương trình khác đã có sẵn trong môi trường production?
Phần khó khăn của Software Engineering
Ngay cả trước khi các AI coding assistants thay đổi cách phân bổ thời gian của một software engineer cho các hoạt động khác nhau, một sự thật hiển nhiên trong lĩnh vực này là hoạt động tiêu tốn nhiều thời gian nhất là hiểu người dùng thực sự muốn gì, hay requirements-gathering. Với việc tự động hóa gần đây đối với rất nhiều công việc lập trình thường nhật, chúng ta có thể kỳ vọng rằng tầm quan trọng cốt lõi của requirements-gathering sẽ chỉ tăng lên. Tôi muốn gợi ý rằng, khi dựa vào nhiều hơn những gì có thể thực hiện được với tự động hóa, chúng ta sẽ thấy requirements-gathering theo định nghĩa thông thường lại giảm đi tầm quan trọng một cách trớ trêu. Để chứng minh điều đó, trước tiên tôi nên điểm lại những quan điểm truyền thống.
Khi các máy tính có thể lập trình được phát triển lần đầu tiên, các chi tiết về việc ai đã làm gì để lập trình cho chúng chắc chắn có chút hỗn loạn. Tuy nhiên, rất nhanh sau đó, khoảng những năm 1960, sự phân chia đã phát triển giữa các analysts (nhà phân tích) và lập trình viên. Nhóm trước có nhiệm vụ hiểu các yêu cầu và dịch chúng thành các ký hiệu tương đối rõ ràng như các flowcharts (sơ đồ khối), các lập trình viên sau đó có thể dịch chúng thành code. Quá trình đào tạo lập trình chính quy của riêng tôi chỉ tiếp xúc rất ít với việc vẽ flowchart trước khi xu hướng đó biến mất hoàn toàn, nhưng trong đợt thực tập mùa hè, tôi nhớ mình đã được một nhân viên kỹ thuật lâu năm của một tập đoàn lớn khuyên rằng “programmer” là một lựa chọn con đường sự nghiệp tồi, đại diện cho một tầng lớp thấp hơn về nhận thức nhận lệnh từ các analysts. (Có lẽ những phát triển trong hỗ trợ AI coding khiến lời khuyên đó có tầm nhìn xa hơn tôi nhận ra vào lúc đó!)
Ngành software engineering đã phát triển các phương pháp truyền thống như waterfall model, nơi các nhóm rất cẩn thận trải qua nhiều phiên bản yêu cầu bằng văn bản trước khi bắt đầu quy trình lập trình tốn kém. Viết các yêu cầu không chỉ là một quy trình nội bộ của một nhóm chuyên gia phần mềm. Điều được cho là quan trọng nhất là giao tiếp với những người dùng dự kiến của chương trình, để hiểu đầy đủ những chức năng nào sẽ làm họ hài lòng. Một cuộc trò chuyện hiếm khi là đủ. Thay vào thế, người dùng dự kiến phải được xem các bản sửa đổi lặp đi lặp lại của tài liệu yêu cầu, để giúp họ suy nghĩ trừu tượng hơn về toàn bộ các tình huống liên quan.
Cuối cùng, waterfall lỗi thời để nhường chỗ cho các phương pháp agile, tập trung vào việc tạo ra các chương trình hoạt động nhanh hơn, để người dùng có thể đưa ra phản hồi đầy đủ thông tin hơn. Vấn đề là ngay cả các chuyên gia phần mềm cũng thấy khó liệt kê tất cả các tình huống liên quan cho một chương trình phức tạp. Nhiều tình huống chỉ trở nên rõ ràng là quan trọng khi dựa trên kiến thức chuyên môn của người dùng, tuy nhiên những người dùng đó lại không được đào tạo về kiểu tư duy trừu tượng và có hệ thống cần thiết để vạch ra tất cả các luồng sử dụng liên quan, với các bước và sự tinh tế của chúng. Việc khai thác thông tin như vậy để định hướng cho một lộ trình sản phẩm vẫn còn rất thách thức ngày nay đến mức thúc đẩy sự ra đời của chuyên ngành product management.
Thách thức trong việc tìm hiểu giải pháp nào thực sự tốt nhất cho người dùng thường được giải thích bằng một câu nói được cho là (có lẽ là ngụy tạo) của Henry Ford, về việc nếu ông hỏi khách hàng của mình họ muốn gì về phương tiện giao thông, họ sẽ yêu cầu những con ngựa nhanh hơn, chứ không phải những chiếc ô tô mà cuối cùng ông đã trao cho họ. Có ít nhất hai vấn đề riêng biệt. Thứ nhất, một người dùng có ý tưởng mơ hồ về mục đích cơ bản của một phần mềm có thể gặp khó khăn trong việc giải thích mục đích đó với đủ chi tiết. Thứ hai, một người dùng không hiểu biết về thực tế phát triển phần mềm có thể không hiểu cái gì là khả thi để xây dựng và với chi phí nào.
Tin tốt là những thách thức này sẽ giảm đáng kể khi người dùng yêu cầu chức năng thường không phải là con người. Chính xác hơn, loại thách thức requirements-gathering kiểu cũ vẫn tồn tại, có lẽ thậm chí dưới dạng thách thức hơn đối với một số ít bộ phận của một hệ sinh thái tác nhân, trong khi hoạt động này phần lớn có thể tránh được đối với các bộ phận còn lại.
Phần mềm như một Người dùng Dễ hiểu hơn
Có một lý do cơ bản tại sao việc biết những gì một chương trình “muốn” lại dễ dàng hơn so với những gì một con người muốn. Hành trình tiến hóa của chúng ta không tạo ra nhiều áp lực chọn lọc lên tâm trí con người để người khác dễ dàng mô phỏng. Thực tế là, các khía cạnh như signaling (phát tín hiệu) thậm chí còn thúc đẩy tính không rõ ràng trong quá trình tư duy của chúng ta, chẳng hạn như để người khác khó đoán ra điều gì sẽ gây ấn tượng với chúng ta, để chúng ta có thể tin tưởng rằng những người thực sự gây được ấn tượng với chúng ta có năng lực phi thường và xứng đáng được liên kết cùng. Ngược lại, một chương trình cần phải giải thích được cho ít nhất một đối tượng: chiếc máy tính chạy nó! Nghĩa là máy tính cần có sự hiểu biết đủ rõ ràng về ý nghĩa chương trình để có thể chạy được chương trình đó, điều mà chúng ta có thể diễn đạt kỹ thuật hơn là nhu cầu các chương trình phải có ngữ nghĩa không mơ hồ (unambiguous semantics). Thêm vào đó là nhu cầu (ít nhất là cho đến gần đây) để con người hiểu chương trình khi họ đang viết và bảo trì nó. Đã có rất nhiều áp lực chọn lọc đối với các chương trình để chúng có thể hiểu được, điều này giờ đây mang lại lợi ích trong khả năng yêu cầu viết code mới của chúng để giúp chúng thực hiện công việc tốt hơn.
Môi trường tối ưu để lợi thế này tỏa sáng là nơi các bộ phận đáng kể của nền kinh tế chỉ bao gồm AI tương tác với các AI khác, thay vì với con người. Một thiết lập như vậy có thể tối đa hóa lợi ích của các môi trường được thiết kế cho khả năng đọc hiểu bởi automated reasoning. Một hệ sinh thái công việc tự động có thể recursively self-improve hướng tới một specification được thiết lập trước, hoặc một tập hợp các tác nhân cạnh tranh và hợp tác có thể tiến hóa cùng nhau hướng tới các specifications của riêng chúng. Dù bằng cách nào, chúng ta cũng có một đặc tả dễ đọc bằng máy về các mục tiêu cơ bản, có thể định kỳ được chuyển thành các yêu cầu cho các chương trình mới.
Bức vẽ tiếp theo minh họa nguyên lý này một cách trực quan hơn. Phần bên trái mô tả thế giới giống như ngày nay hơn, bao gồm nhiều AI agents, hầu hết chúng phải phối hợp trực tiếp với con người, buộc phải thu thập các yêu cầu từ các bên liên quan không giỏi giải thích những gì họ muốn. Phần bên phải mô tả thế giới mà chúng ta có thể đang hướng tới, nơi hầu hết nền kinh tế được xử lý bởi các AI agents, những tác nhân tự nhiên hình thành các cụm với rất ít gatekeepers (người gác cổng) cần giao tiếp với con người. Phần bên trong của các cụm là những nơi có trật tự và các yêu cầu rõ ràng. Trong thế giới này, đại đa số các chương trình đều ở bên trong cụm và được hưởng lợi từ các nguồn yêu cầu rõ ràng.
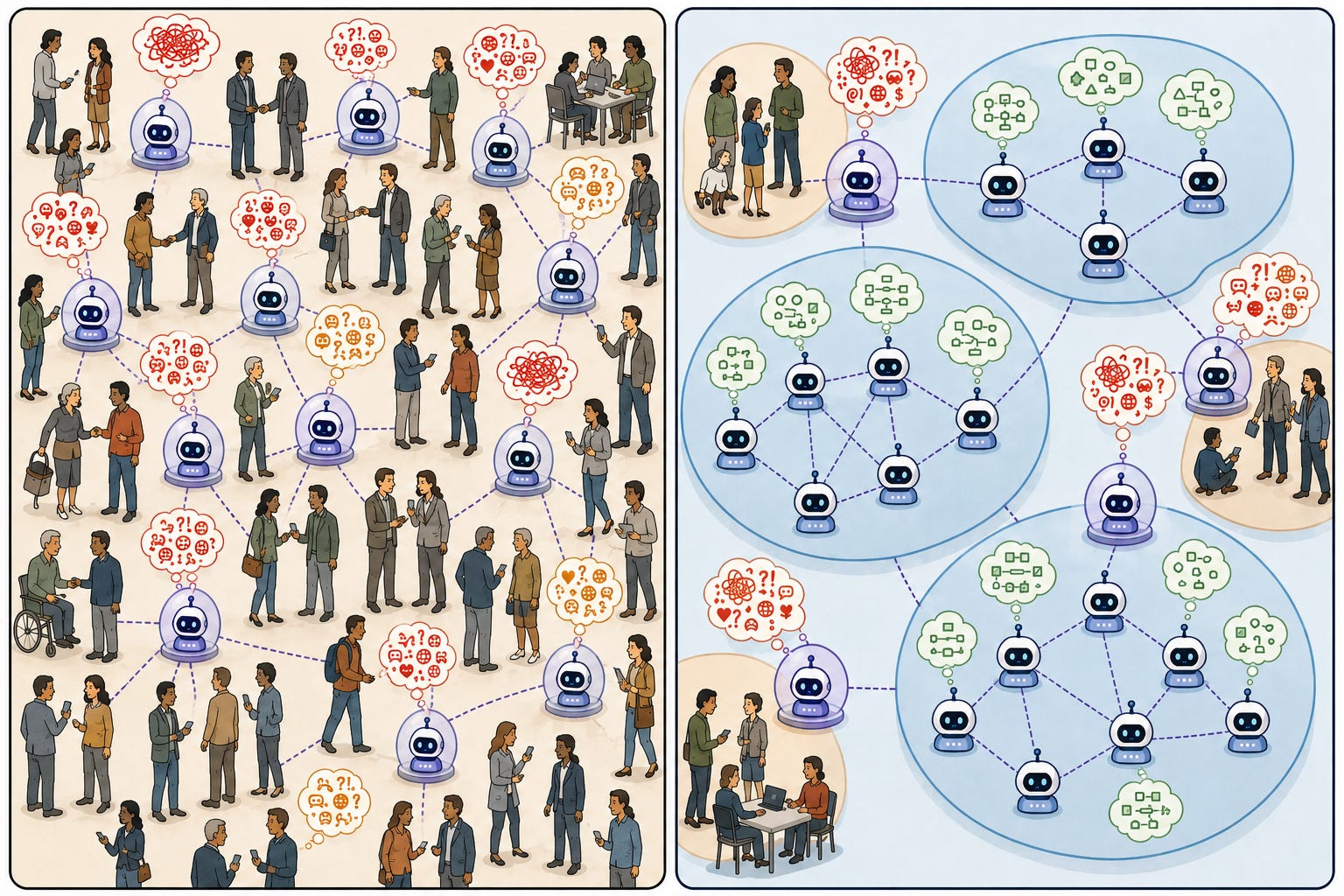
Điều tối quan trọng là chúng ta sẽ không đến sau và cố gắng mô tả hành vi và mong muốn của các hệ sinh thái tác nhân. Hiện tại chúng ta có tiềm năng tích hợp formal specification và verification vào thiết kế của chúng từ những ngày đầu. Thách thức của chúng ta là viết một specification bao trùm toàn bộ hệ sinh thái AI, buộc những sinh vật bên trong đó phải tiến hóa theo những cách tương thích với các mục tiêu và giá trị của chúng ta. Thách thức requirements-gathering này vẫn khó khăn như thường lệ! Điểm của tôi là nhiều dự án kỹ thuật khác bên trong các bong bóng AI như vậy trở nên dễ thiết lập khuôn khổ hơn, và chúng sẽ trở thành phần lớn nỗ lực software-engineering đang diễn ra (và là nguồn chi phí liên quan).
Một phiên bản khiêm tốn hơn của hiện tượng này đã phổ biến ngày nay. Hãy lấy ví dụ về một nhóm software-engineering triển khai một trình duyệt web mới. Các tiêu chuẩn kỹ thuật hiện có hạn chế đáng kể thiết kế mới. Đã có rất nhiều yêu cầu được ghi lại trong các tiêu chuẩn Internet, giải thích cách code của một trang web tương ứng với những gì sẽ hiển thị cho người dùng. Khi nhiều phần của nền kinh tế được xử lý bởi các AI agents hơn, nhiều bối cảnh của chúng sẽ được chuẩn hóa tương tự hoặc ít nhất là được thể hiện trong code hiện tại có thể phân tích được.
Cần lưu ý ở đây rằng loại phần mềm AI phổ biến nhất ngày nay, deep learning, có nhược điểm rõ rệt là các chương trình riêng lẻ (nay được hiểu là bao gồm cả các yếu tố học được như trọng số mô hình) có rất ít cấu trúc rõ ràng và do đó khó hiểu, chẳng hạn như để tìm ra “chúng muốn gì”. Tôi cho rằng đặc tính này sẽ thúc đẩy chúng ta sử dụng nhiều hơn các phương pháp khác được thiết kế cho khả năng dễ hiểu và khả năng giới hạn hành vi của chúng một cách chính xác bằng các lập luận toán học, mặc dù lập luận rộng hơn của tôi vẫn có giá trị trong các trường hợp khác. Nói cách khác, chúng ta có thể có một khoảng thời gian ngắn để quyết định xem chúng ta muốn sống trong một thế giới của các hệ thống học được không thể thấu hiểu hay thay vào đó là thúc đẩy các hệ thống được chứng minh là đáp ứng các yêu cầu rõ ràng. Con đường thứ hai có thể là cực kỳ quan trọng không chỉ cho sự an toàn chống lại các AI nổi loạn mà còn cho hiệu quả của việc tự cải tiến AI mà nó cho phép, ngay cả khi mục tiêu cuối cùng chỉ là nhắm mục tiêu quảng cáo trực tuyến tốt hơn. Bây giờ hãy để tôi giải thích nguồn gốc của hiệu quả đó.
Sao chép các phần của Specification và Code của chính bạn là tương đối dễ dàng
Hãy cụ thể hơn một chút về cách các giai đoạn đầu tiên của software engineering trở nên rẻ hơn, khi chúng ta có các chương trình yêu cầu viết các chương trình mới.
Đầu tiên giả định rằng các chương trình người dùng đã được viết tuân theo các thực hành tốt và có các tài liệu yêu cầu được trau chuốt của riêng chúng. Chúng ta thậm chí có thể nhìn vào phiên bản tổng quát nhất của một lập luận, giả sử rằng các chương trình sẽ yêu cầu các chương trình mới có các yêu cầu của riêng chúng được viết ra theo các tiêu chuẩn chất lượng mong muốn cho các chương trình mới. Lời giải thích nông cạn cho lợi thế này, do đó, là chúng ta chỉ có thể sao chép các phần nội dung yêu cầu có liên quan từ các yêu cầu của người dùng yêu cầu chương trình mới. Không có tùy chọn nào như vậy là đơn giản đối với người dùng con người, những người có xu hướng không công bố rộng rãi các mục tiêu cuộc sống của họ dưới dạng máy có thể đọc được.
Xem xét rộng hơn về việc các chương trình muốn thấy các chương trình mới được viết như thế nào. Tôi đã gợi ý rằng chúng ta thấy một nền kinh tế tham gia vào đổi mới kỹ thuật như một distributed system theo nghĩa computer-science, với các tác nhân khác nhau hợp tác và cạnh tranh trong một tập hợp các bài toán tối ưu hóa chồng chéo. Các bên tham gia khác nhau biết ở các mức độ chi tiết khác nhau những gì họ đang cố gắng thực hiện; các bên tham gia là phần mềm đặc biệt có nhiều khả năng liên kết với các rigorous formal specifications (hoặc ít nhất, vinh dự đó khó xảy ra đối với con người!). Ở một mức độ nào đó, một hệ thống kinh tế như vậy là một chương trình tham gia vào việc lặp đi lặp lại tự tối ưu hóa chính nó.
Hãy cụ thể hơn với một ví dụ nơi một chương trình tự cải thiện lưu giữ một số code của chính nó vào một biến thể được cải tiến một cách tự nhiên. Trường hợp tương đối đơn giản là một chương trình tính toán một hàm toán học cụ thể và nhận thấy các cách cải thiện cấu trúc của chính nó để tính toán hàm đó hiệu quả hơn. Tôi đang lập luận rằng các dự án software-engineering phát triển trong tương lai sẽ trông giống như kiểu tự tối ưu hóa này hơn là những gì chúng ta quen thuộc. Một chương trình có mục tiêu nhưng chỉ có ý tưởng tương đối mơ hồ về cách đạt được mục tiêu đó sẽ yêu cầu viết các chương trình mới nhắm vào cùng một mục tiêu nhưng với chiến lược cụ thể hơn. Một sự tương đồng tốt dù khá kỹ thuật là multi-stage programming, tôi sẽ giải thích bằng ví dụ (mặc dù hầu hết các chi tiết code không bắt buộc phải theo dõi sát sao). Dưới đây là một hàm Python (đệ quy) nâng số x lên lũy thừa n.
def power(x, n):
if n == 0:
return 1
elif n % 2 == 0:
y = power(x, n // 2)
return y * y
else:
return x * power(x, n - 1)Hãy tưởng tượng rằng một AI agent sử dụng hàm này thường xuyên cho các tác vụ lũy thừa. Trên thực tế, nó nhận thấy rằng một nửa số lần sử dụng có n bằng 13. Thông qua một quy trình cơ học được gọi là partial evaluation, nó tạo ra phiên bản chuyên biệt này.
def power13(x):
x2 = x * x
x3 = x * x2
x6 = x3 * x3
x12 = x6 * x6
x13 = x * x12
return x13Chúng ta đã có một giai đoạn tính toán để tạo ra code này, và bây giờ chúng ta có thể chạy code mới lặp đi lặp lại trong một giai đoạn sau, do đó có tên gọi là “multi-stage programming”. Hàm power13 mới có thể chạy nhanh hơn power (nó không cần chạy tất cả các bài kiểm tra đó về tính chất số học của số mũ; nó không cần làm công việc ghi chép sổ sách về cách một nhóm các cuộc gọi hàm liên quan đến nhau). Một phần những gì chúng ta từ bỏ để đạt được tốc độ đó là tính tổng quát của hàm, nhưng chúng ta cũng có thể tưởng tượng mình giữ lại cả phiên bản cũ. Chúng ta vẫn sử dụng thêm bộ nhớ cho các phiên bản chuyên biệt, và chúng ta vẫn tốn thời gian để tạo ra chúng. Các sự đánh đổi tương tự cũng áp dụng cho just-in-time compilation như được thực hiện bởi các trình duyệt web để thực thi hiệu quả code được nhúng trong các trang web.
Tuyên bố của tôi, giờ đây mang tính kỹ thuật hơn, là những ví dụ từ điện toán phổ thông ngày nay mang tính đại diện cho tương lai của phát triển phần mềm hơn là các dự án software-engineering cổ điển. Đúng vậy, các dự án mới sẽ vẫn được bắt đầu để xây dựng phần mềm với người dùng là con người, trong trường hợp đó các vấn đề và phương pháp cổ điển vẫn phù hợp. Tuy nhiên, vì lý do hiệu quả, ngày càng có nhiều phần của nền kinh tế được xử lý bởi các AI agents không có kết nối trực tiếp với con người, chỉ có các AI agents khác. Các tác nhân và nhóm tác nhân sẽ kích hoạt phát triển phần mềm mới vì cùng lý do mang lại lợi ích của việc chuyên biệt hóa hàm power ở trên, nhưng các dự án này sẽ tương đối được xác định rõ ràng hơn, với các specifications của chúng được rút ra một cách tự nhiên, thường bằng các cách cơ học, từ các specifications hoặc ít nhất là code của các tác nhân yêu cầu.
Hình ảnh tiếp theo cố gắng minh họa mô hình này, với một tác nhân yêu cầu một chương trình mới dựa trên một tập con code hoặc specification của chính nó, cộng với một kích thích môi trường mới lạ mà code bây giờ nên được chuyên biệt hóa cho phù hợp.

Các bài viết trước đã liên quan đến các so sánh mang tính kỹ thuật tương tự dựa trên interpreters (trình thông dịch), các chương trình chạy các chương trình khác bằng các ngôn ngữ cụ thể; và compilers (trình biên dịch), các chương trình dịch các chương trình khác giữa các ngôn ngữ. Ở một mức độ nào đó, một tác nhân có thể hoạt động vô thời hạn như một interpreter. Nó có một số nhiệm vụ cấp cao với nhiều chi tiết thực thi cần tìm hiểu, thông qua một số quy trình tìm kiếm, có lẽ là phối hợp với các tác nhân khác. Nó có thể tích lũy các ghi chú về kiến thức thu được cho đến nay, các ghi chú này được tham khảo liên tục bởi code được viết để chuẩn bị hành động thích hợp trên bất kỳ ghi chú nào được chuyển giao cho nó. Tuy nhiên, khi việc tìm kiếm tiếp tục diễn ra, một số phần của code được bộc lộ là không liên quan. Một số phần được tiết lộ là chứa các xử lý đáng kể cho các trường hợp không phổ biến hoặc không liên quan. Với một chương trình ban đầu đủ phức tạp đại diện cho mọi thứ cần thiết để thực hiện một công việc gần giống như công việc được thực hiện ngày nay bởi các chuyên gia được đào tạo chuyên sâu, tất cả các loại dự án software-engineering đều có thể được coi là sự chuyên biệt hóa của chương trình ban đầu đó. Phạm vi khả thi thậm chí còn rộng hơn khi chúng ta tưởng tượng các cộng đồng tác nhân phối hợp để khởi động các dự án phần mềm.
Kết luận
Lập luận mà tôi trình bày ở đây hoàn thiện khuyến nghị hoặc dự đoán gồm ba điểm về cách chúng ta sẽ tận dụng trí thông minh tự động.
Formal verification là một công cụ vô giá cho các quy trình tìm kiếm phần mềm tốt hơn, cho phép xác nhận trước rằng một chương trình sẽ hoạt động như mong muốn trong nhiều tình huống khác nhau. Tuy nhiên, chúng ta cần các specifications đủ chính xác để làm cho formal verification trở nên có ý nghĩa.
Nếu chúng ta thực sự khởi động thành công với các specifications chính xác và toàn diện cho các hệ thống máy tính, thì các hoạt động tìm kiếm phần mềm tốt hơn mà chúng phối hợp có thể truyền tải chất lượng specification đó một cách tự nhiên sang việc phát triển các chương trình mới.
Với loại recursive self-improvement loop đó hoạt động tốt, sẽ có lợi khi tìm cách tách biệt các đơn vị hoạt động kinh tế khỏi các nguồn phức tạp của specification, cho phép chúng có các specifications đơn giản hơn nhằm kích hoạt quá trình tìm kiếm hoạt động hiệu quả.
Một vòng lặp như vậy phụ thuộc rất lớn vào tính hiệu quả của việc triển khai nó. Nó chạy càng nhanh và càng làm được nhiều việc với một lượng bộ nhớ nhất định, chúng ta càng có thể tìm ra các chiến lược mới tốt hơn một cách hiệu quả, điều này mang lại lợi ích đệ quy cho khả năng tiếp tục tự cải thiện của hệ thống. Mối quan ngại đó thúc đẩy việc suy nghĩ cẩn thận về việc phần mềm tương lai sẽ trông như thế nào, như tôi sẽ đề cập trong một loạt bài đăng về thiết kế các programming languages. Tôi sẽ lập luận rằng các nguyên tắc tương tự giúp ích cho các hệ thống tự trị cũng có ý nghĩa đối với các lập trình viên con người. Tôi cũng sẽ lập luận rằng các ngôn ngữ như Rust, vốn thường được ca ngợi là đại diện cho tương lai của programming-language design, lại không được thiết kế cho việc mở rộng hiệu suất mà chúng ta cần cho các ứng dụng quan trọng.
I have some experience with very large-scale projects within major corporations.
Specifications were created by staff in customer-facing roles and subsequently stored in large databases. These specifications were then broken down into detailed requirements. Over time, the volume grew to the point where there were thousands of individual requirements.
Although the development process mandated a thorough review of all requirements, human errors still occurred. Furthermore, additional requirements were frequently introduced during the development phase itself.
All of this resulted in a requirements database that lacked full consistency—regardless of whether the Waterfall model or Agile Development was being used.
Here is what I would like to see:
a) Requirements management tools should check natural language text for consistency right from the start and immediately alert users to any inconsistencies found in the database.
b) The process of breaking down high-level requirements into detailed ones should be AI-assisted, with the AI specifically flagging any gaps—essentially signaling, "Something is missing here!"
c) Existing requirements in commercial tools like e.g. IBM DOORS or Siemens Polarion should feature a new mode allowing users to resolve database inconsistencies through a dialogue with the AI.
d) Official bodies—such as the IETF, SAE (automotive), ERA (railway), and many others—should check their existing specifications for consistency and gaps. New specifications (typically involving multiple companies) should be developed in collaboration with AI.
Formal verification is only helpful if you know what to verify. The spec you check needs to match your intents about what is possible and what shouldn't happen.
In Quint, specs can be executed which helps a lot with understanding those things - you won’t be reading mathematical formulas, but seeing actual step-by-step system behaviors. This is what allows you to precisely define what correct behavior is and isn’t, and make formal verification meaningful.